Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: cdc进程异常挂掉
[TiDB Usage Environment] Production Environment
[TiDB Version] v4.0.13
Topology: 3 TiDB + 3 PD (mixed deployment), 3 TiKV, 2 TiCDC
Background:
An alert was received indicating abnormal CPU usage on one CDC. Upon investigation, it was found that there were originally two CDC processes handling synchronization tasks. However, during the alert period, one of the CDC processes suddenly crashed, causing the CPU usage on the other CDC machine to spike. The synchronization process was not affected. Upon checking the resources at the time of the crash, it was determined that the issue was not resource-related and might be related to TiKV leader switching, but this is not certain.
Solution:
Restarting the crashed CDC process resolved the issue.
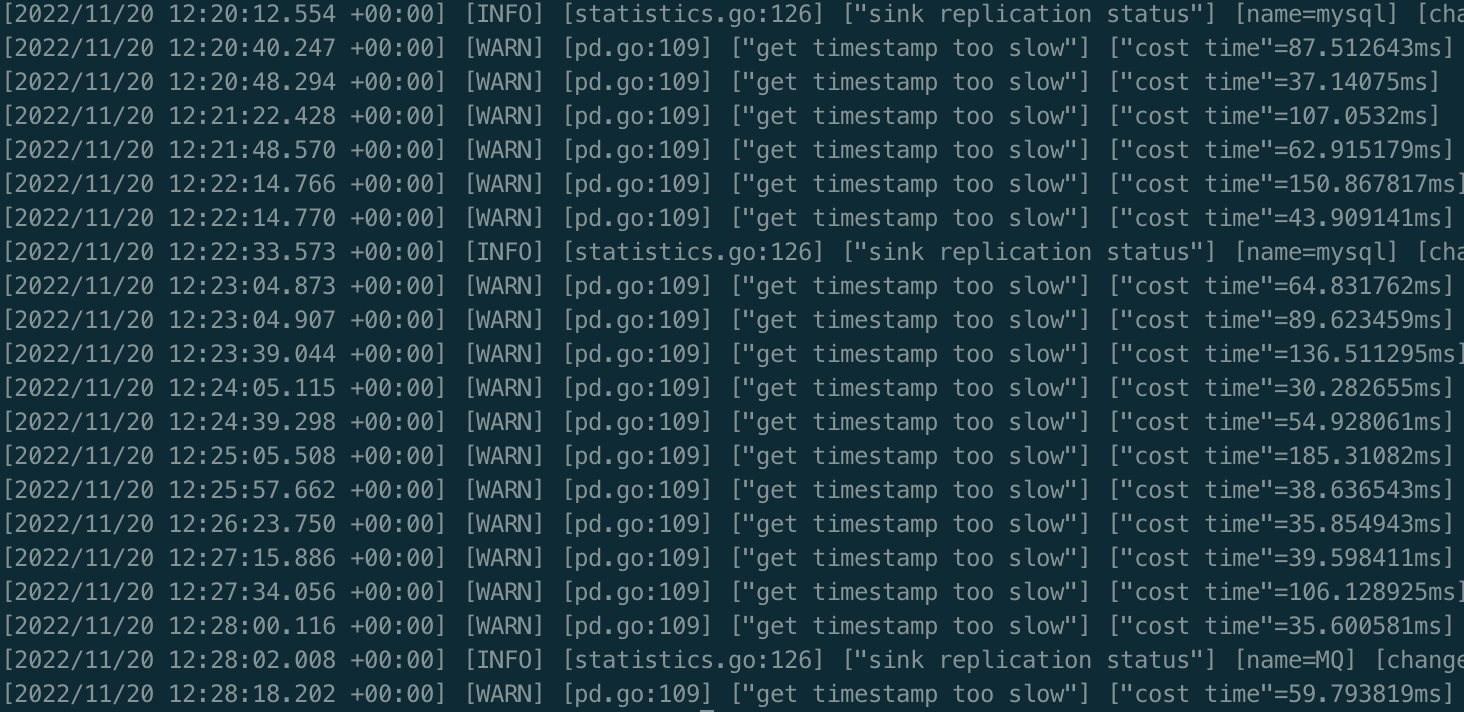
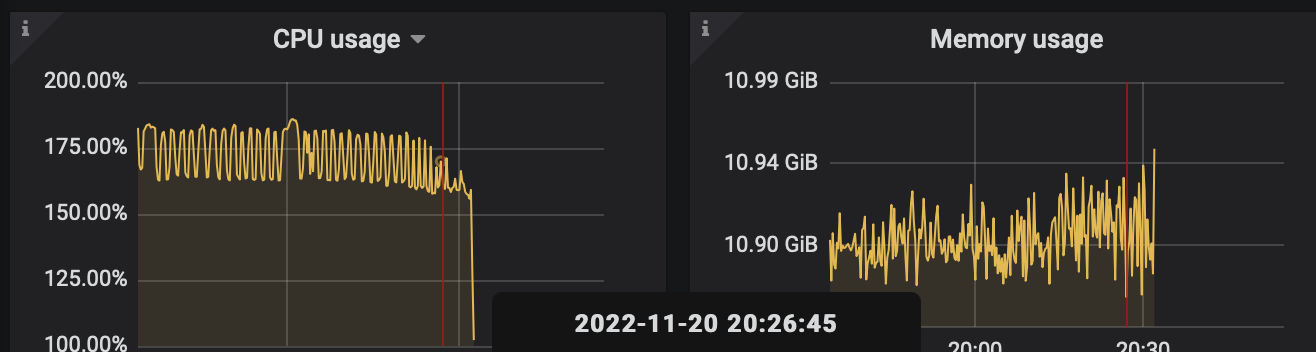
Resource monitoring during the fault period of the machine where the CDC process crashed (CPU and resources did not reach the threshold):
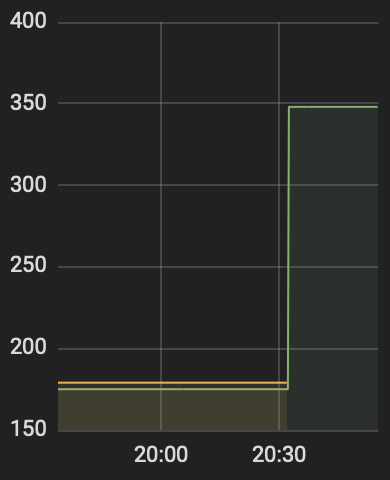
CDC monitoring (transactions were all directed to one machine):
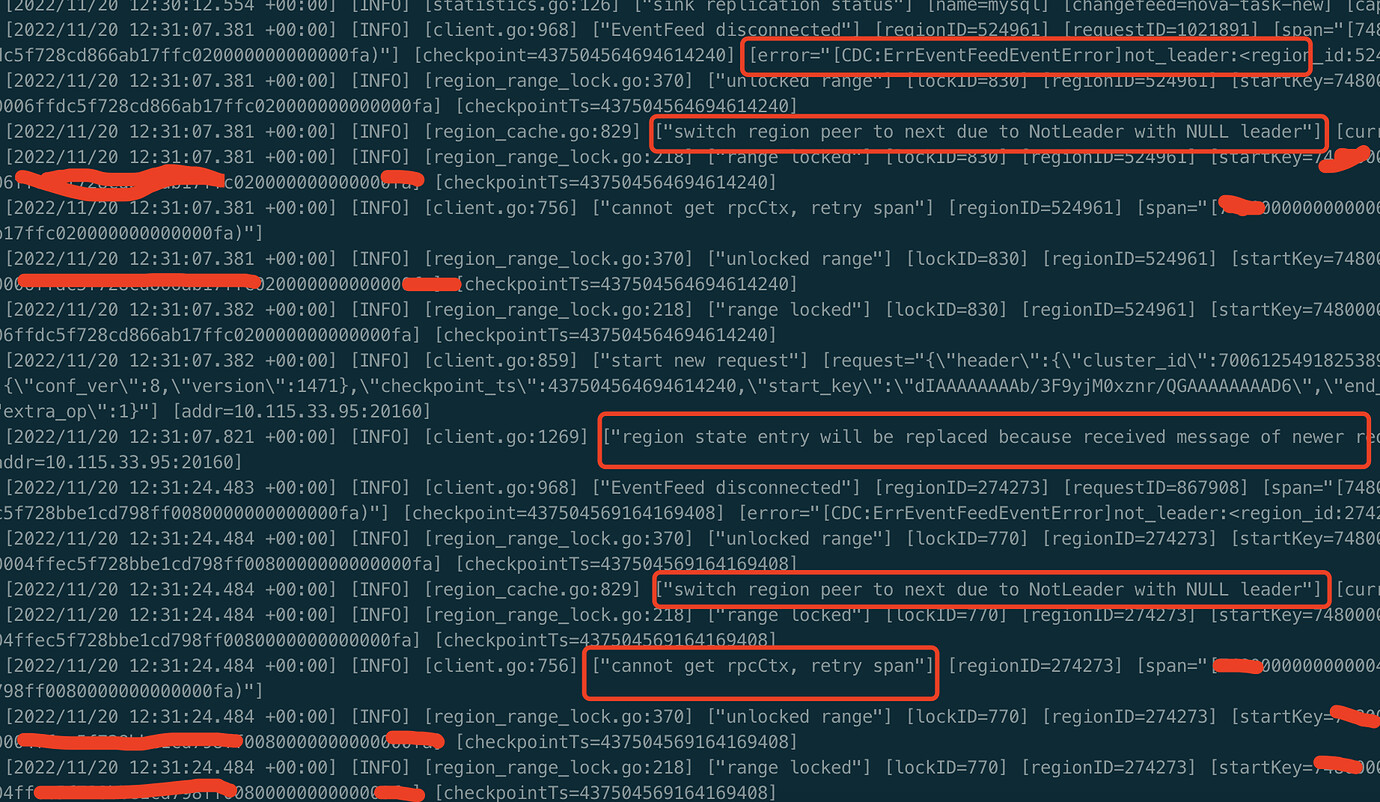
TiKV logs:
[2022/11/20 12:31:24.476 +00:00] [INFO] [pd.rs:797] ["try to transfer leader"] [to_peer="id: 274275 store_id: 5"] [from_peer="id: 274276 store_id: 61784"] [region_id=274273]
[2022/11/20 12:31:24.481 +00:00] [INFO] [peer.rs:2109] ["transfer leader"] [peer="id: 274275 store_id: 5"] [peer_id=274276] [region_id=274273]
[2022/11/20 12:31:24.481 +00:00] [INFO] [raft.rs:1376] ["[term 30] starts to transfer leadership to 274275"] [lead_transferee=274275] [term=30] [raft_id=274276] [region_id=274273]
[2022/11/20 12:31:24.481 +00:00] [INFO] [raft.rs:1389] ["sends MsgTimeoutNow to 274275 immediately as 274275 already has up-to-date log"] [lead_transferee=274275] [raft_id=274276] [region_id=274273]
[2022/11/20 12:31:24.484 +00:00] [INFO] [raft.rs:1003] ["received a message with higher term from 274275"] ["msg type"=MsgRequestVote] [message_term=31] [term=30] [from=274275] [raft_id=274276] [region_id=274273]
[2022/11/20 12:31:24.484 +00:00] [INFO] [raft.rs:783] ["became follower at term 31"] [term=31] [raft_id=274276] [region_id=274273]
[2022/11/20 12:31:24.484 +00:00] [INFO] [raft.rs:1192] ["[logterm: 30, index: 1337, vote: 0] cast vote for 274275 [logterm: 30, index: 1337] at term 31"] ["msg type"=MsgRequestVote] [term=31] [msg_index=1337] [msg_term=30] [from=274275] [vote=0] [log_index=1337] [log_term=30] [raft_id=274276] [region_id=274273]
[2022/11/20 12:31:24.484 +00:00] [INFO] [endpoint.rs:321] ["cdc deregister region"] [deregister="Deregister { deregister: \"region\", region_id: 274273, observe_id: ObserveID(1962251), err: Request(message: \"peer is not leader for region 274273, leader may None\" not_leader { region_id: 274273 }) }"]
[2022/11/20 12:31:24.484 +00:00] [INFO] [delegate.rs:348] ["cdc met region error"] [error="Request(message: \"peer is not leader for region 274273, leader may None\" not_leader { region_id: 274273 })"] [region_id=274273]
[2022/11/20 12:31:24.485 +00:00] [INFO] [endpoint.rs:457] ["cdc register region"] [downstream_id=DownstreamID(2214038)] [req_id=1056029] [conn_id=ConnID(6884)] [region_id=274273]
[2022/11/20 12:31:24.485 +00:00] [INFO] [endpoint.rs:457] ["cdc register region"] [downstream_id=DownstreamID(2214039)] [req_id=1022946] [conn_id=ConnID(6549)] [region_id=274273]
[2022/11/20 12:31:24.486 +00:00] [INFO] [endpoint.rs:321] ["cdc deregister region"] [deregister="Deregister { deregister: \"region\", region_id: 274273, observe_id: ObserveID(2082446), err: Request(message: \"peer is not leader for region 274273, leader may None\" not_leader { region_id: 274273 }) }"]
[2022/11/20 12:31:24.486 +00:00] [INFO] [delegate.rs:348] ["cdc met region error"] [error="Request(message: \"peer is not leader for region 274273, leader may None\" not_leader { region_id: 274273 })"] [region_id=274273]
[2022/11/20 12:31:24.486 +00:00] [INFO] [endpoint.rs:321] ["cdc deregister region"] [deregister="Deregister { deregister: \"region\", region_id: 274273, observe_id: ObserveID(2082446), err: Request(message: \"peer is not leader for region 274273, leader may None\" not_leader { region_id: 274273 }) }"]
[2022/11/20 12:31:07.056 +00:00] [INFO] [peer.rs:1728] ["starts destroy"] [merged_by_target=true] [peer_id=859003] [region_id=859001]
[2022/11/20 12:31:07.056 +00:00] [INFO] [peer.rs:628] ["begin to destroy"] [peer_id=859003] [region_id=859001]
[2022/11/20 12:31:07.056 +00:00] [INFO] [pd.rs:877] ["remove peer statistic record in pd"] [region_id=859001]
[2022/11/20 12:31:07.056 +00:00] [INFO] [peer_storage.rs:1450] ["finish clear peer meta"] [takes=157.81µs] [raft_logs=16] [raft_key=1] [apply_key=1] [meta_key=1] [region_id=859001]
[2022/11/20 12:31:07.058 +00:00] [INFO] [peer.rs:668] ["peer destroy itself"] [takes=2.049106ms] [peer_id=859003] [region_id=859001]
[2022/11/20 12:31:07.058 +00:00] [INFO] [router.rs:265] ["[region 859001] shutdown mailbox"]
[2022/11/20 12:31:07.374 +00:00] [INFO] [raft.rs:1739] ["[term 37] received MsgTimeoutNow from 524962 and starts an election to get leadership."] [from=524962] [term=37] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.374 +00:00] [INFO] [raft.rs:1177] ["starting a new election"] [term=37] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.374 +00:00] [INFO] [raft.rs:807] ["became candidate at term 38"] [term=38] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.374 +00:00] [INFO] [raft.rs:902] ["524963 received message from 524963"] [term=38] [msg=MsgRequestVote] [from=524963] [id=524963] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.374 +00:00] [INFO] [raft.rs:923] ["[logterm: 37, index: 7223] sent request to 524964"] [msg=MsgRequestVote] [term=38] [id=524964] [log_index=7223] [log_term=37] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.374 +00:00] [INFO] [raft.rs:923] ["[logterm: 37, index: 7223] sent request to 524962"] [msg=MsgRequestVote] [term=38] [id=524962] [log_index=7223] [log_term=37] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.380 +00:00] [INFO] [raft.rs:1673] ["received from 524964"] [term=38] ["msg type"=MsgRequestVoteResponse] [from=524964] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.380 +00:00] [INFO] [raft.rs:874] ["became leader at term 38"] [term=38] [raft_id=524963] [region_id=524961]
[2022/11/20 12:31:07.384 +00:00] [INFO] [endpoint.rs:457] ["cdc register region"] [downstream_id=DownstreamID(2210903)] [req_id=1022945] [conn_id=ConnID(7229)] [region_id=524961]
[2022/11/20 12:31:07.822 +00:00] [INFO] [endpoint.rs:1017] ["cdc resolver initialized and schedule resolver ready"] [takes=440ms] [observe_id=ObserveID(2076635)] [lock_count=0] [resolved_ts=0] [downstream_id=DownstreamID(2210903)] [conn_id=ConnID(7229)] [region_id=524961]
PD logs:
[2022/11/20 12:30:07.384 +00:00] [INFO] [grpc_service.go:815] ["update service GC safe point"] [service-id=ticdc] [expire-at=1669033807] [safepoint=437504548625187182]
[2022/11/20 12:30:08.953 +00:00] [INFO] [operator_controller.go:424] ["add operator"] [region-id=805185] [operator="\"balance-leader {transfer leader: store 1 to 5} (kind:leader,balance, region:805185(2336,8), createAt:2022-11-20 12:30:08.953777489 +0000 UTC m=+11081243.422388666, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, steps:[transfer leader from store 1 to store 5])\""] ["additional info"="{\"sourceScore\":\"6448.00\",\"targetScore\":\"6447.00\"}"]
[2022/11/20 12:30:08.953 +00:00] [INFO] [operator_controller.go:620] ["send schedule command"] [region-id=805185] [step="transfer leader from store 1 to store 5"] [source=create]
[2022/11/20 12:30:08.965 +00:00] [INFO] [cluster.go:566] ["leader changed"] [region-id=805185] [from=1] [to=5]
[2022/11/20 12:30:08.965 +00:00] [INFO] [operator_controller.go:537] ["operator finish"] [region-id=805185] [takes=11.47198ms] [operator="\"balance-leader {transfer leader: store 1 to 5} (kind:leader,balance, region:805185(2336,8), createAt:2022-11-20 12:30:08.953777489 +0000 UTC m=+11081243.422388666, startAt:2022-11-20 12:30:08.953933172 +0000 UTC m=+11081243.422544349, currentStep:1, steps:[transfer leader from store 1 to store 5]) finished\""] ["additional info"="{\"sourceScore\":\"6448.00\",\"targetScore\":\"6447.00\"}"]
CDC logs:
[2022/11/20 12:32:11.153 +00:00] [INFO] [server.go:169] ["campaign owner successfully"] [capture-id=2c4f2eb6-a362-4db6-97cb-93a66577d148]
[2022/11/20 12:32:11.154 +00:00] [INFO] [owner.go:1645] ["start to watch captures"]
It seems that the CDC owner change was caused by the leader switch. The tracking regions of the crashed CDC were deregistered and re-accepted by another CDC. I don’t quite understand the principle behind this. Can someone explain?