[TiDB Usage Environment] Production Environment / Testing / Poc
[TiDB Version] V5.2
[Reproduction Path]
When using UUID as the primary key, does the clustered index become invalid, or will an implicit auto-increment rowid be used to maintain the primary key?
Previous versions were more friendly to bigint… In fact, to meet the requirements of data sharding, UUID would be more suitable.
bigint also has many compatibility treatments, such as the auto_random method…
Okay, using UUID means maintaining a rowid. I thought it was always incrementing, but now I see it is unique within the table.
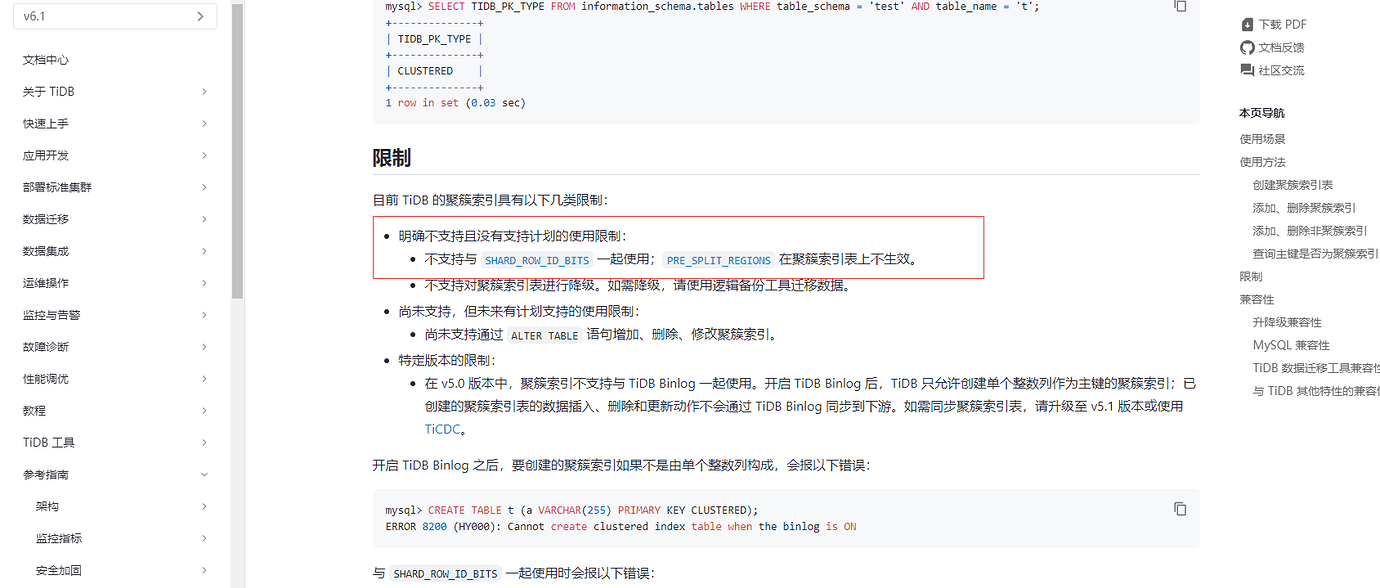
Another question, I previously used UUIDs without a clustered index (it was version 4.0 before, and I recently upgraded to 6.1; v4.0 does not support clustered indexes). How can I change it to a clustered index now? The official documentation says modification is not supported.
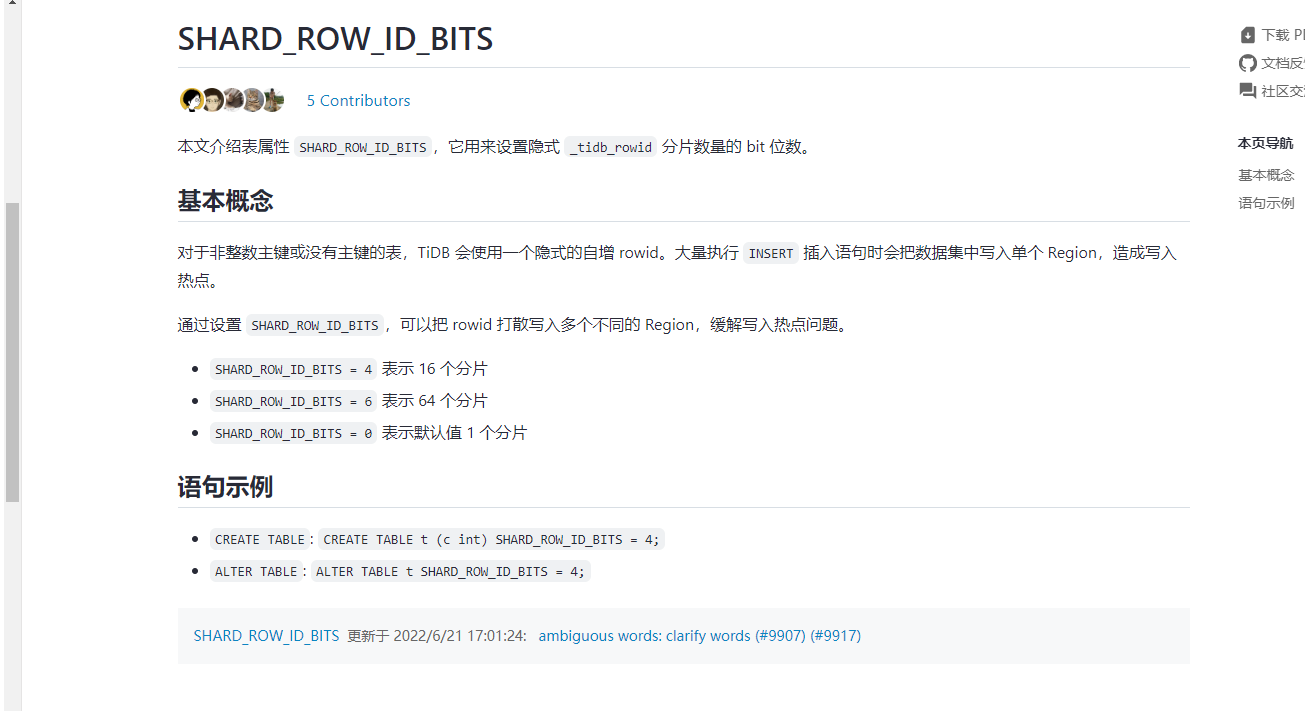
Isn’t it mentioned here that a non-integer primary key will use an implicit auto-increment rowid? Or does it mean that an implicit auto-increment rowid will only be used if I explicitly set SHARD_ROW_ID_BITS when creating the table? If SHARD_ROW_ID_BITS is not explicitly set, the primary key will be used directly (if the primary key is a UUID, then the UUID will be used).
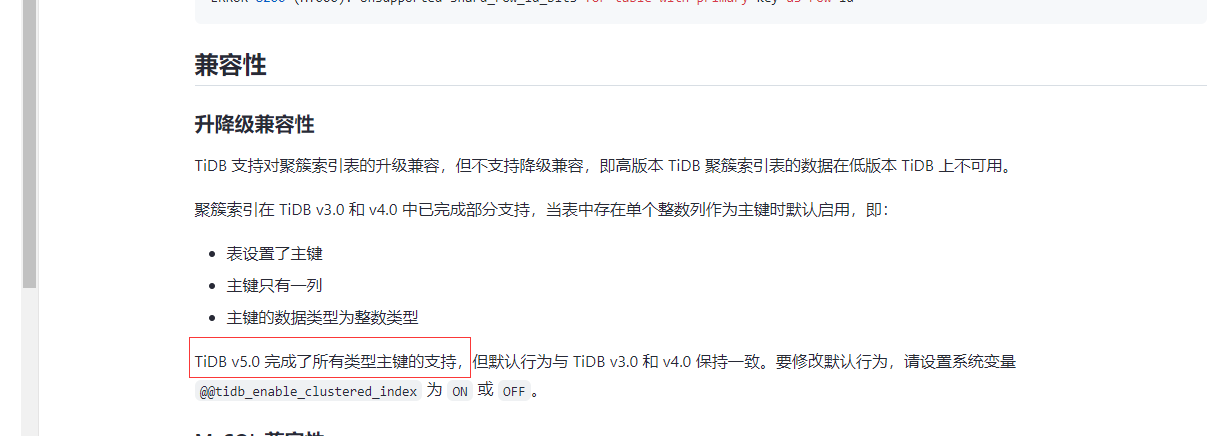
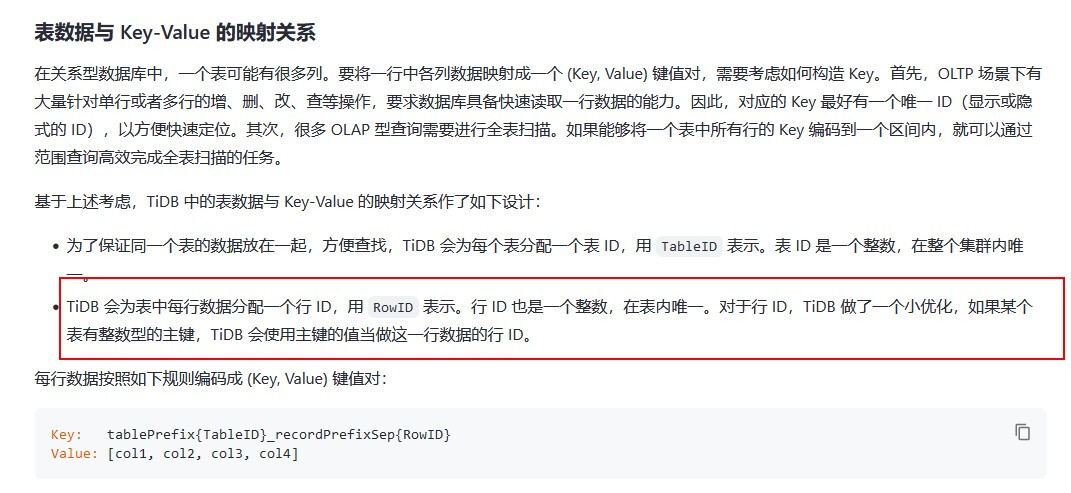
Before clustered indexes were introduced, a rowid was added by default to all primary keys except for those of the Int type. After the introduction of clustered indexes, as long as it is specified as clustered, no rowid is added.
So, is the primary key in my table a clustered index? I still have a rowid, but when querying data, I can retrieve all data using the primary key id. Previously, I didn’t specify clustered, but there was no table-back operation when querying data. This primary key should be a clustered index, right?
It’s obvious that this is using a clustered index. The primary key of this table is FILE_NUMBER.
The ID is of character type, and if cluster index is not specified, the primary key is an independent index. PointGet means accessing through the primary key or unique key.
Do primary keys and unique keys also store row data? What is the difference between primary keys and clustered indexes in storing data? Do primary keys store row data?
Another question is, if I currently don’t have a clustered index, how can I make it a clustered index? The official website says modification is not supported.
If it is a clustered index, find the corresponding Value through tablePrefix{TableID}_recordPrefixSep{index value}.
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
If it is a primary key index or a unique index, find the RowID in the Value through tablePrefix{tableID}_indexPrefixSep{indexID}_index value, and then use RowID to find the corresponding Value through tablePrefix{TableID}_recordPrefixSep{RowID}.
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
If it is a normal secondary index, it matches the range of {RowID} through tablePrefix{TableID}_indexPrefixSep{IndexID}_index value, and then queries the value through RowID using tablePrefix{TableID}_recordPrefixSep{RowID}.
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}indexedColumnsValue{RowID}
Value: null