Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 上图是否cdc 任务内部排序慢,如何调优
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] v6.1.0
[Encountered Issues: Problem Phenomenon and Impact]
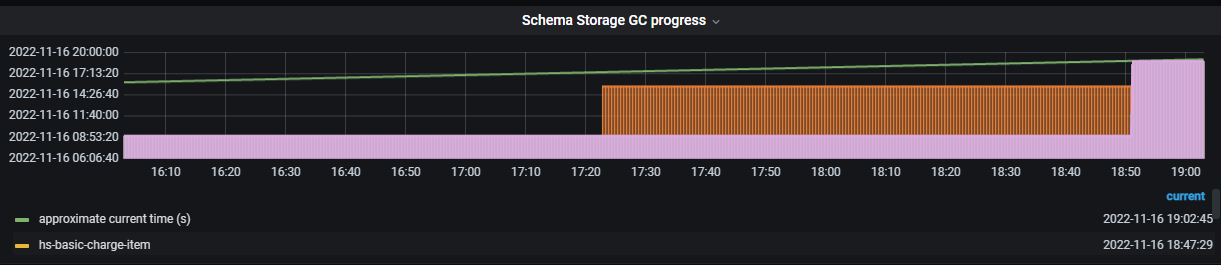
What does schema storage gc progress mean? There is a table that hasn’t moved, stuck there. Is there also a latency issue? How to optimize it?
Does this indicate that the CDC task sorting is slow? How to optimize it?
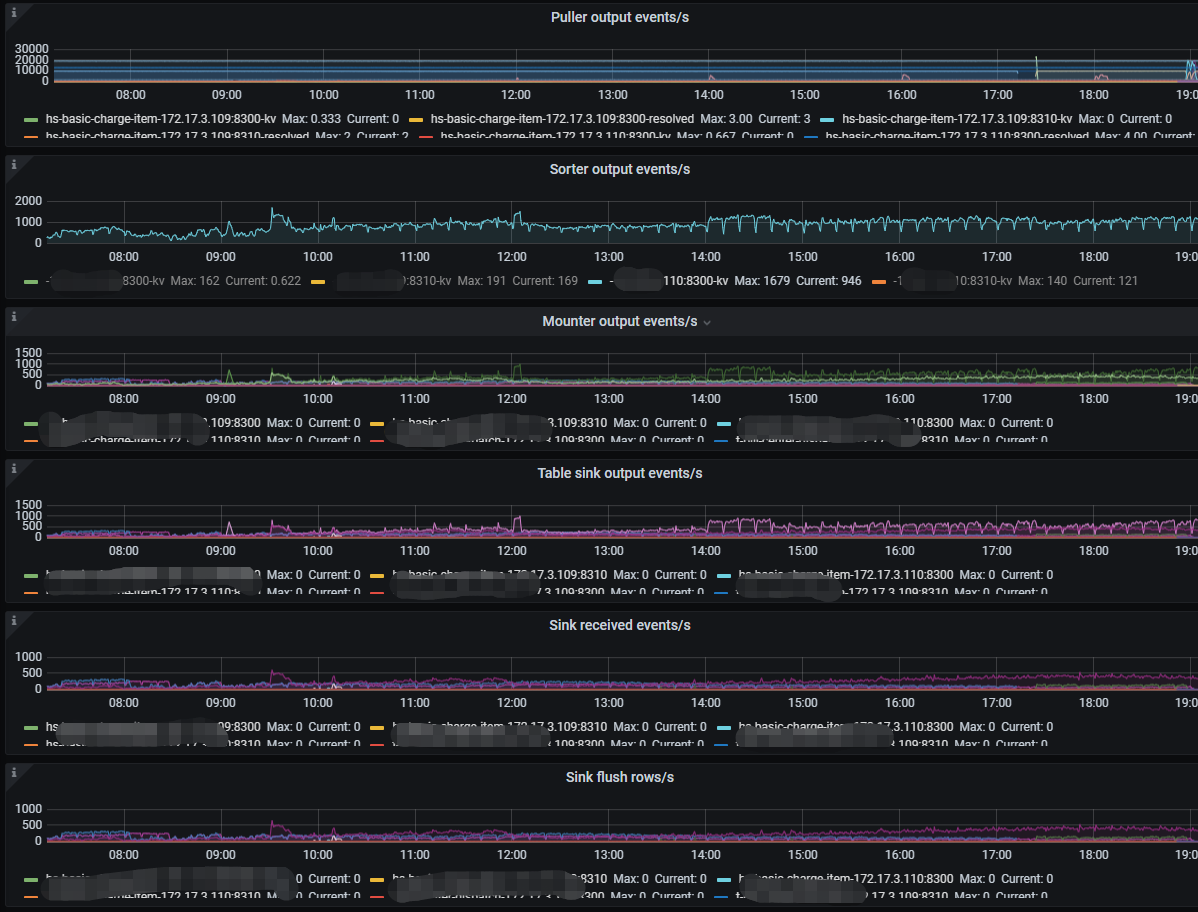
Currently, TiCDC might still be executing some DDL operations, and the memory usage should be quite high. Additionally, if the sorter event is relatively slow, you should check whether it is due to large transactions by looking for the “BIG_TXN” keyword in the TiDB logs and the size of the “Transaction Write Size Bytes” in TiDB. Also, check the Sink write monitoring in TiCDC.
If it is indeed due to large transactions, it is recommended to synchronize this part of the data to the downstream using other backup methods, such as using BR or Lightning.
There are some large transactions, but the volume is not high. It might be due to synchronizing a wide table with over 300 fields. The logs show 30-80 BIG_TXN entries per TiDB node. How should we optimize the CDC node in this situation? Currently, we are performing incremental synchronization, so BR and Lightning cannot be used.
The same table, creating two test tasks to synchronize to different Kafka instances, results in different extraction delays on the CDC side. Why is this happening?
Q1. How should we optimize the CDC node in this situation?
- If you are using TiCDC version 6.1.0, you can try using version 6.1.2. Version 6.1.2 has corresponding optimizations for large transactions.
- For a large single table with more than 300 fields, the CDC encoding speed in version 6.1.0 is relatively slow, which can indeed lead to synchronization speed issues. You can consider using a separate changefeed to synchronize that large single table, as it may be slowing down the synchronization progress of other tables. This can also speed up the encoding of messages for that table.
Q2. For the same table, establishing two test tasks to synchronize to different Kafka instances results in different CDC extraction delays. Why is this?
- It could be due to different network speeds of the Kafka instances. You can observe whether the sink write duration percentile metrics for the changefeeds writing to different Kafka instances differ significantly.
Finally, TiCDC versions 6.5.0 and 6.1.3 will have targeted optimizations for wide table synchronization, so you can try using those versions when they are available.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.