Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 执行亿级数据出现oom
[Test Environment for TiDB] Testing
[TiDB Version] v6.1.0
[Reproduction Path]
[Encountered Issue: Problem Phenomenon and Impact]
Executing SELECT COUNT(*) FROM dx_hash_map exceeds the system default of 1 minute and directly results in lost connection to MySQL, which is essentially an OOM (Out of Memory) issue.
[Resource Configuration]
TiDB and PD are deployed together on 3 machines with 16 cores and 16GB RAM each.
TiKV is deployed on 3 separate machines with 16 cores and 32GB RAM each.
Following the solution in this blog post 专栏 - tidb server的oom问题优化探索 | TiDB 社区, adjustments were made but the OOM issue still occurs.
OOM error in tidblog
According to the blog, if the memory limit is exceeded, it should use disk, but upon checking, it does not.
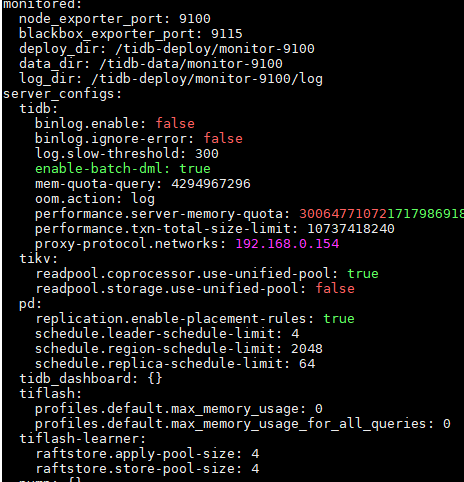
Cluster TiDB configuration
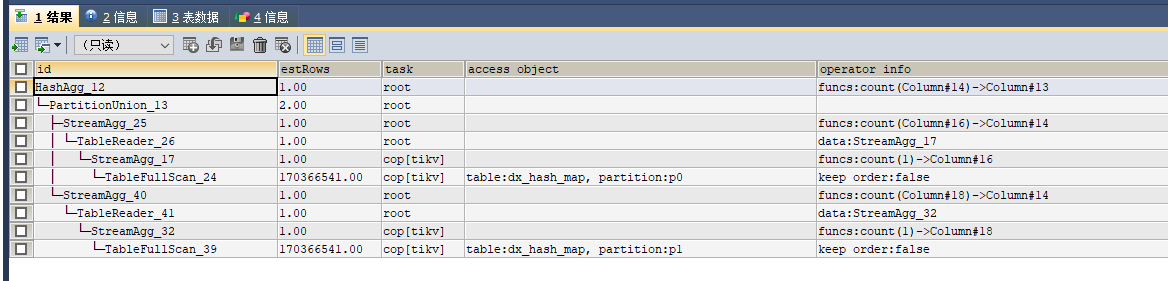
Execution plan
Please post the SQL execution plan.
Please take another look.
I don’t think this SQL is the cause. The expensive SQL in the logs just indicates that this SQL scans a lot of data.
Your SQL count is done by TiKV according to the execution plan, and what does OOM refer to, TiKV, TiDB, or TiFlash? I see a hint in the logs indicating it uses the TiFlash engine.
To determine if there is an OOM, check the uptime in the monitoring or the server’s dmesg -T | grep tidb.
The command dmesg -T | grep tidb did not find any log information on the machines in this cluster (the cluster has been expanded recently).
I think the main reason is that the number of connections is too high. You can try to increase the value of max_connections in the MySQL configuration file.
If you can’t find it, I understand there shouldn’t be an OOM, right? Check the server memory usage and the uptime of each component in the monitoring to determine if there was an OOM or a process restart. If there’s none, I understand it’s not an OOM.
The default value of tidb_enable_clustered_index is INT_ONLY, which means that the clustered index is enabled by default for tables with integer primary keys.
It feels like there is a time limit on the network, and the connection is closed after the timeout.
Don’t log in with the client, just wait for the server to execute and see.
Executing on the client still results in lost connection…

Currently using HAProxy to forward TiDB.
Are you connecting directly to the database or through a proxy?
Use the proxy method to forward and proxy 3 machines.
Go to the dashboard and search the logs to see if there are any “panic” keywords.
Try connecting directly without executing SQL through HA.
Hmm, currently using the direct method is pending…
Direct connection is possible. Are there any related solutions for optimizing connections within HAProxy? 
Execute
select count(*), imei from dx_hash_map group by imei