Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 某台机器上 TIKV 节点 突然Leader数量跌为0
[TiDB Usage Environment] Production Environment
[TiDB Version] 4.0.12
[Reproduction Path] Deleting data from a table with 10 indexes
[Encountered Problem: Phenomenon and Impact]
Environment: The TiDB cluster has 6 KV nodes distributed across 3 machines, with two KV processes on each machine.
Problem: The three KV machines are xxx.xxx.xxx.10, xxx.xxx.xxx.16, and xxx.xxx.xxx.17. Among them, xxx.xxx.xxx.17 and xxx.xxx.xxx.10 frequently experience the Leader count dropping to 0, and then immediately start balancing the leader, returning to a balanced state. The drop to 0 occurs simultaneously for the two instances on the machine.
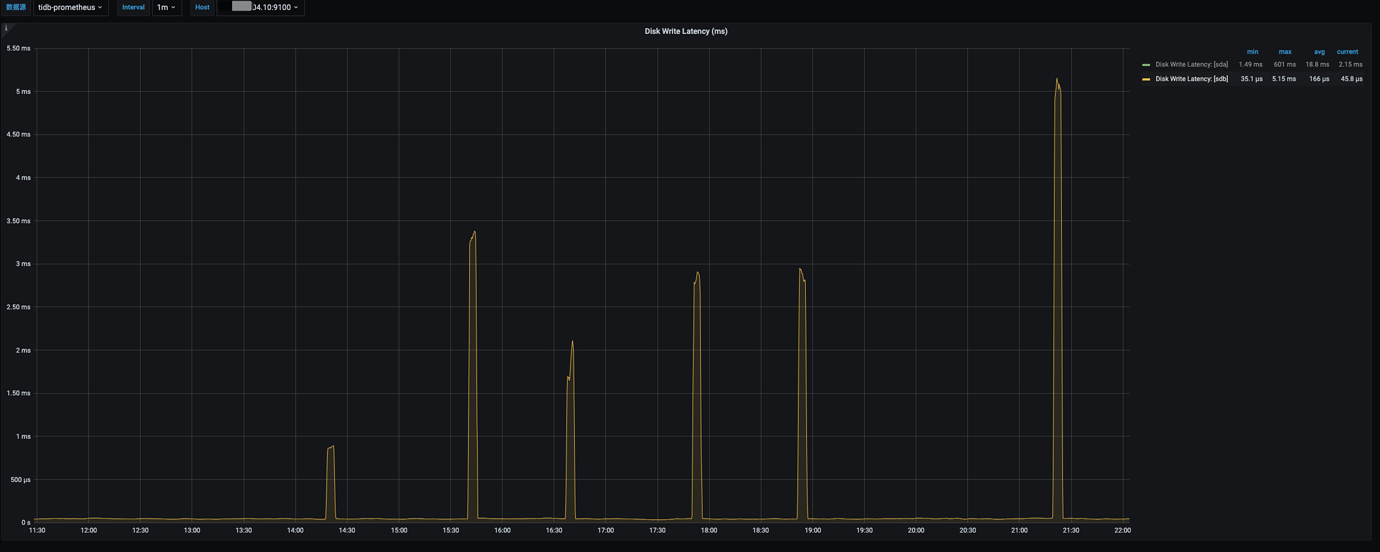
When the Leader count drops to 0 and then balances, there is a period where the data disk IO utilization is very high, then it returns to normal.
When not deleting data, the Leader count does not drop to 0.
Checking the TiKV logs of the problematic Leader drop to 0, there are many occurrences of:
[2022/11/23 21:20:04.988 +08:00] [WARN] [store.rs:645] [“[store 33447] handle 971 pending peers include 917 ready, 1558 entries, 6144 messages and 0 snapshots”] [takes=39049]
Suspected machine issues, but no disk errors were found on the hardware, and the two machines alternately experiencing the issue is quite strange.
Monitoring information: https://clinic.pingcap.com.cn/portal/#/orgs/430/clusters/6932065597686668710?from=1669196400&to=1669203000
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
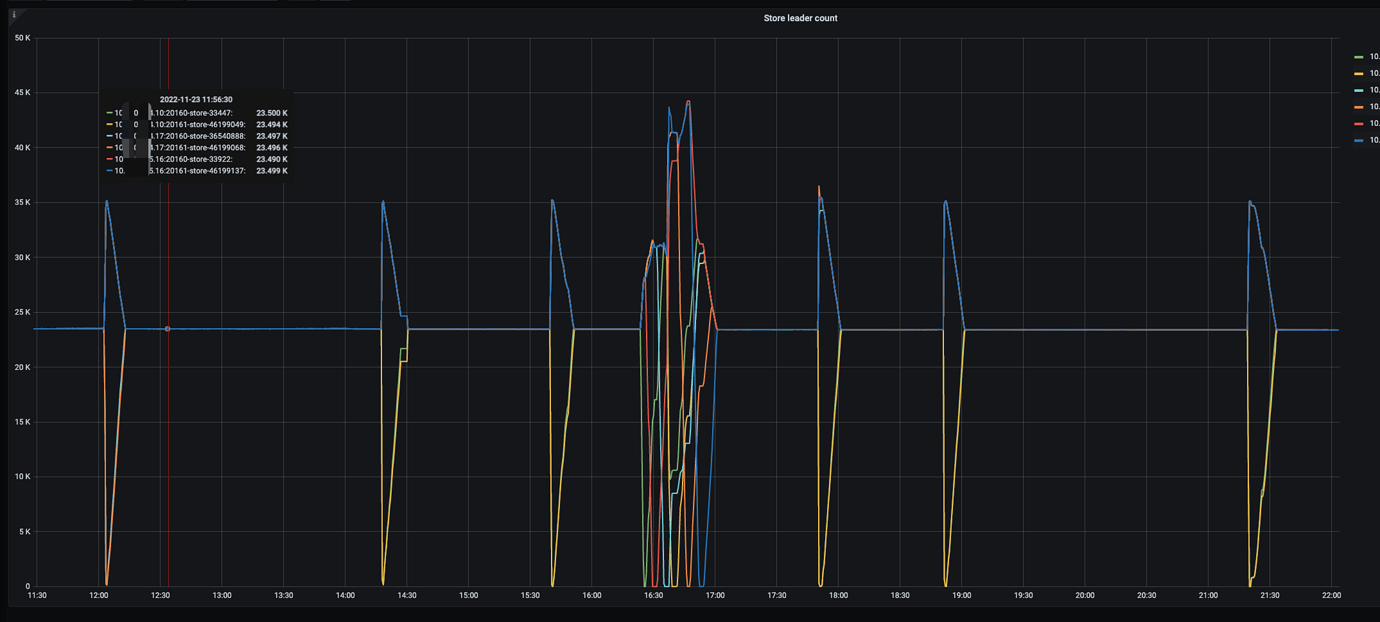
In the above screenshot, the middle graph shows alternating changes in quantity, which can be ignored as it is during the reload of the TiKV node. Observe the three instances of Leader drop to 0 on the left and right.