Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tidb5.4.2集群崩溃 SELECT * FROM INFORMATION_SCHEMA.TABLES limit 3 ; ERROR 9005 (HY000): Region is unavailable
Bug Report
Clearly and accurately describe the issue you found. Providing any steps to reproduce the problem can help the development team address the issue promptly.
[TiDB Version]
tidb 5.4.2
[Impact of the Bug]
Cluster crash, users cannot log in.
[Possible Steps to Reproduce]
[Observed Unexpected Behavior]
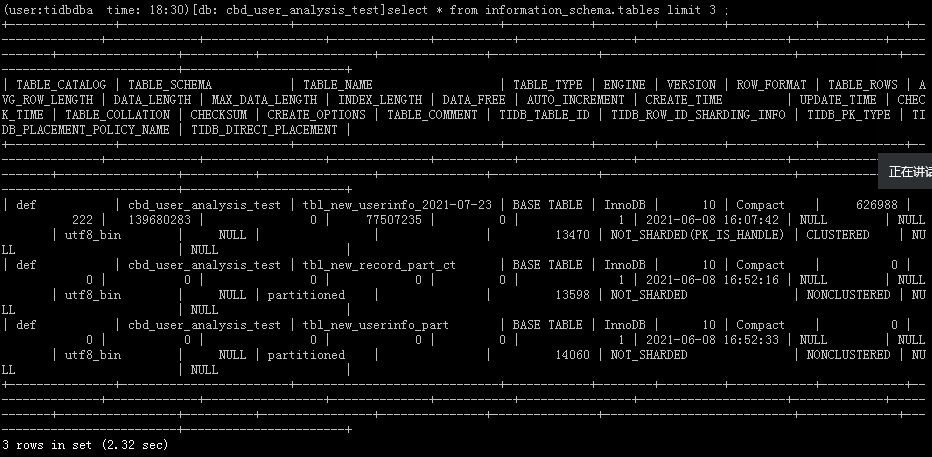
SELECT * FROM INFORMATION_SCHEMA.TABLES limit 3; ERROR 9005 (HY000): Region is unavailable
[Expected Behavior]
[Related Components and Specific Versions]
All components 5.4.2
[Other Background Information or Screenshots]
Such as cluster topology, system and kernel version, application app information, etc.; if the issue is related to SQL, please provide the SQL statement and related table schema information; if there are critical errors in the node logs, please provide the relevant node log content or files; if some business-sensitive information is inconvenient to provide, please leave your contact information, and we will communicate with you privately.
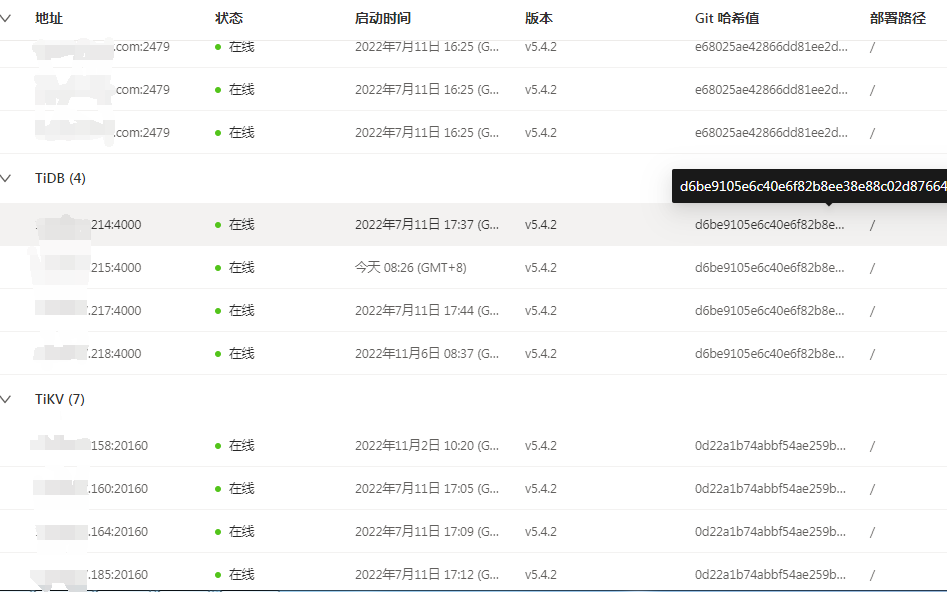
This morning at 6:57 AM, the upstream ticdc reported an error, indicating that the downstream table could not be found. I logged into the downstream (current crashed cluster) via command line and found that show create table was normal. Around 10 AM, the development team reported that the test application could not log in. It was found that INFORMATION_SCHEMA.TABLES was unavailable.
Check the cluster status.
Please send it.
Our environment is not deployed with tiup. Is there a download link for the compiled version of clinic?
You can refer to the official documentation to check the status of the corresponding region and the status of the corresponding TiKV instance.
Error Number: 9005
The complete error message is ERROR 9005 (HY000): Region is unavailable.
The accessed Region is unavailable, a certain Raft Group is unavailable, such as insufficient replica numbers, which occurs when TiKV is relatively busy or the TiKV node is down. Please check the TiKV Server status/monitoring/logs.
You can deploy the diagnostic toolkit.
There was a PD error reported early in the morning.
It might be related to the bug in version 5.4.2.
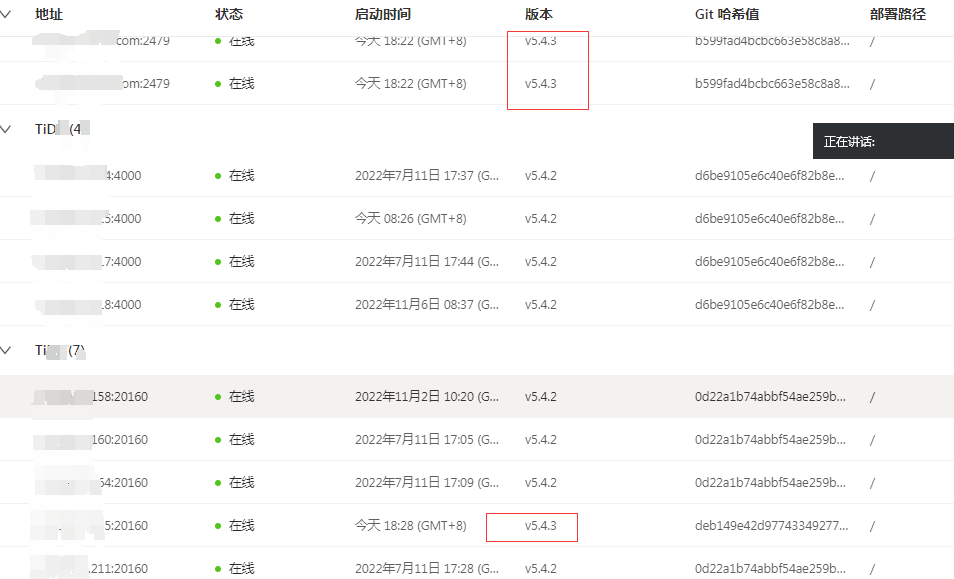
Well, I’m preparing to upgrade and see if it will be more stable than now. Fortunately, this is a downstream cluster. Additionally, there are two production clusters still on version 5.4.2 that are being urgently coordinated for an upgrade to avoid similar issues from happening again.
Before upgrading TiKV, you need to perform the evict-leader operation, which is particularly slow. If you use the command pd-ctl -u pd:2379 store_id weight 0 x, the leader steps down very quickly. Why is the weight 0 method not recommended?
After upgrading PD to 5.4.3, the cluster has recovered. Currently, only one TiKV is at version 5.4.3, while the others are at 5.4.2. The evict-leader process is too slow.
If the business does not need to wait, you can force the upgrade.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.