【TiDB Usage Environment】Production Environment
【TiDB Version】v5.4.1
【Encountered Issue: Problem Phenomenon and Impact】
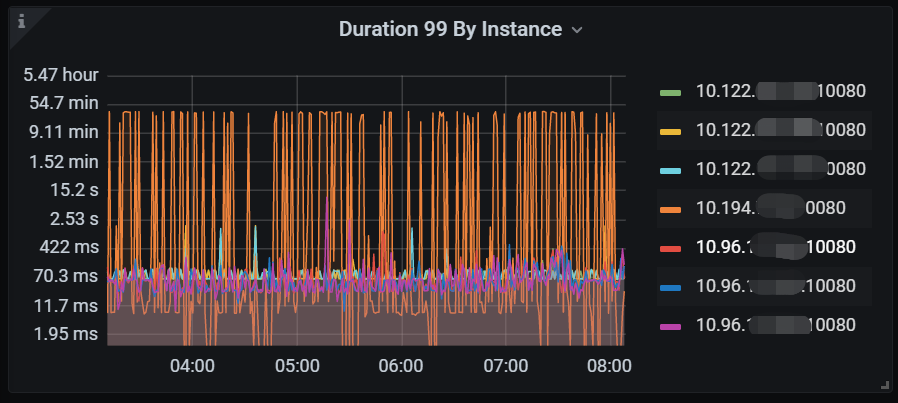
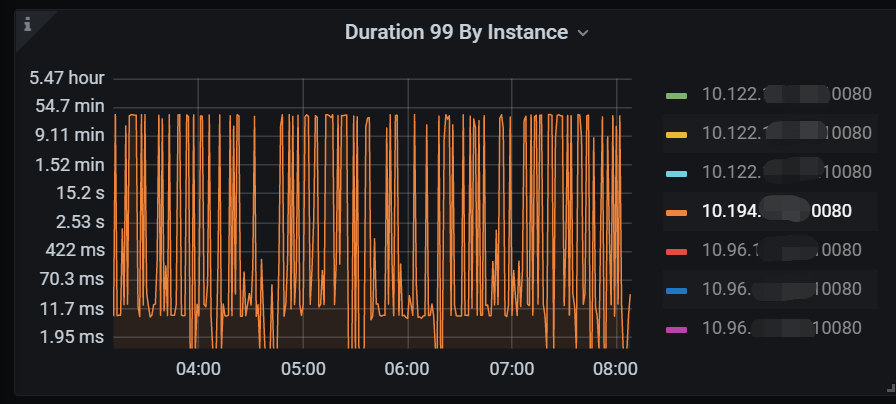
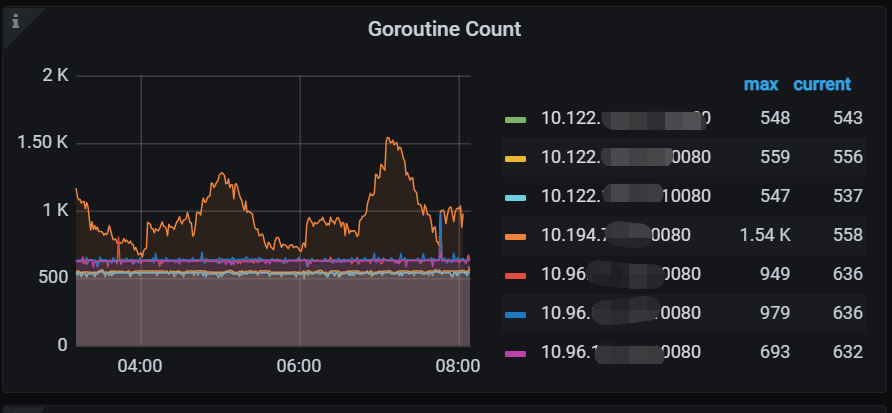
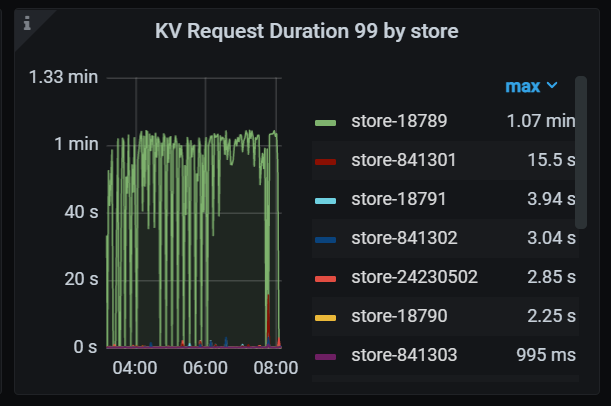
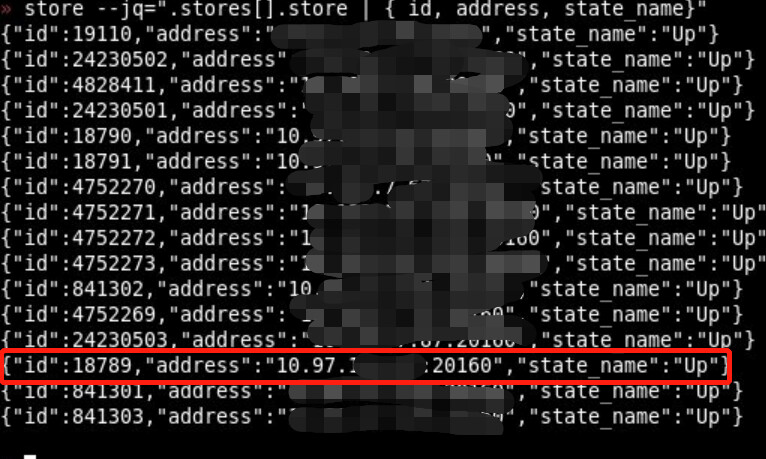
Our environment is a two-city, three-center setup, with two data centers in Beijing and one in Shenyang. Currently, when a task is run by a developer and it lands on the Shunyi data center in Beijing, the TiDB node in Shunyi hangs and can only be resolved by a restart.
We have optimized the tasks run by the developers:
Split large transactions
Optimized SQL
Shuffled the keys of the tables
Please help us identify other areas we can work on. If the information is insufficient, what additional information do we need to provide?
Thank you all.
For a two-city, three-center architecture, you should prioritize configuring PD and region leaders to be primarily on one side of the two centers to minimize network impact. I’m not sure if your cluster is configured this way. Refer to the documentation:
What is the memory usage like when it hangs? Also, check if overcommit_memory is set to 0 or 1. If it is set to 0, it won’t actively kill the process, so it will hang.
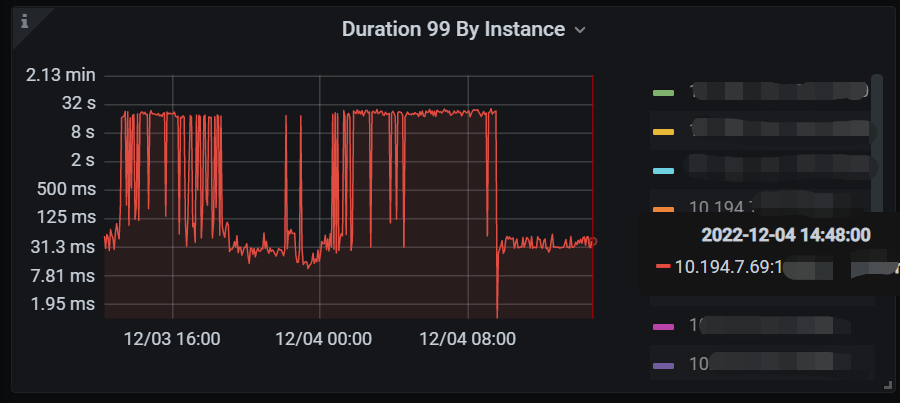
Today, from 04-08, it happened again. From Grafana, the memory usage is not high. As for the overcommit_memory parameter, we have not configured it, as shown below: