Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv 节点oom导致自动重启
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version]
[Reproduction Path] What operations were performed when the issue occurred
[Encountered Issue: Issue Phenomenon and Impact]
[Resource Configuration]
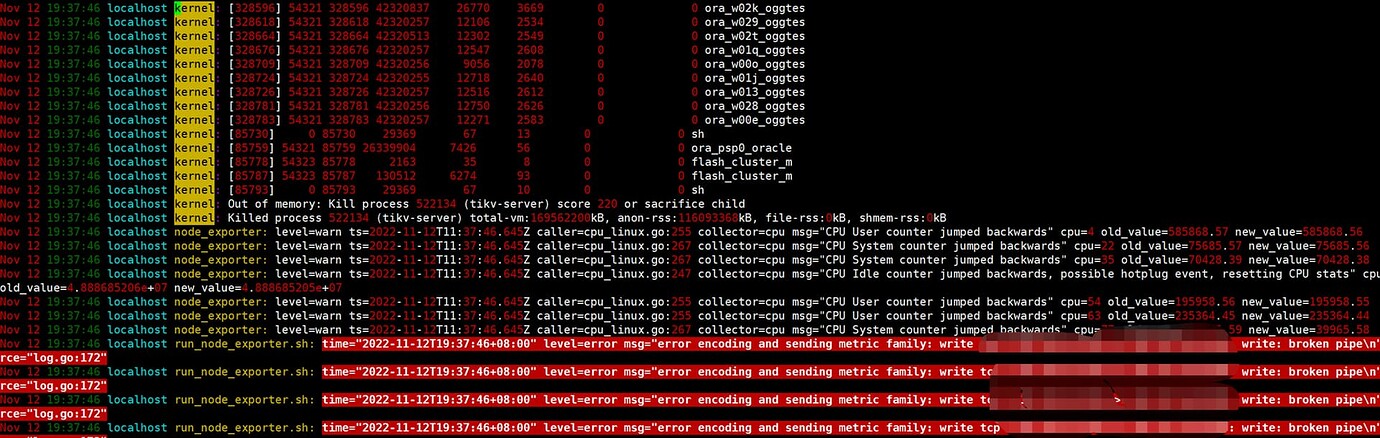
[Attachments: Screenshots / Logs / Monitoring]
Around 19:00 on November 12th, the TiKV node experienced a restart. Upon checking the TiKV node-related logs, no anomalies were found. However, upon checking the system logs, it was discovered that:
I would like to ask, won’t this memory be automatically released?
【TiDB Version】
【Reproduction Steps】What operations were performed when the issue occurred
Please provide these details.
Version information: v6.1.1
Operations performed: Basically no business operations, just checked the dashboard. The time points when issues appeared were all related to some internal SQL and monitoring SQL.
How is the TiKV memory parameter storage.block-cache.capacity configured? How much memory does the machine have? Is it deployed with multiple instances?
First, follow this to troubleshoot:
There are 4 clusters deployed on these 3 machines.
Multi-instance deployment, set the memory for each TiKV with storage.block-cache.capacity = (MEM_TOTAL * 0.5 / number of TiKV instances)
Setting the memory too high can easily lead to OOM (Out of Memory).
The machine’s memory is 527517072, and the cluster is set to 214078MiB. This cluster is composed of 3 servers, with each machine deploying one TIKV node. In this case, the memory setting is reasonable. However, since these 3 servers are deploying 4 clusters, does that mean it should be 527517072 / 0.5 / 4?
Is the memory setting for the TiKV node too large? However, the TiKV logs do not show OOM, only the server’s operation logs indicate an OOM occurred.
It’s equivalent to deploying 4 TiKV instances on one server. If that’s the case, the memory allocated to TiKV is indeed too large. The operating system logs showing OOM can confirm this point.
Parameter settings for hybrid deployment: 混合部署拓扑 | PingCAP 文档中心
Won’t this memory be automatically released?
 If you have 3 machines and 4 clusters, with balanced distribution, that means each server will have 4 TiKV nodes. Isn’t that too many?
If you have 3 machines and 4 clusters, with balanced distribution, that means each server will have 4 TiKV nodes. Isn’t that too many?
Memory is released slowly, not all at once.
In that case, it also involves sharing memory and storage, right?
However, since the 4 TiKV nodes on each server are not part of the same cluster, there will definitely be resource contention issues. When resources are insufficient, the Linux mechanism is likely to randomly kill processes 
Looking at the monitoring, this is a big problem as it has not been released continuously…
This monitoring should be for server memory, not TiDB memory usage. You can check the memory usage of each node to see what is causing it. It might also be an issue with GC.