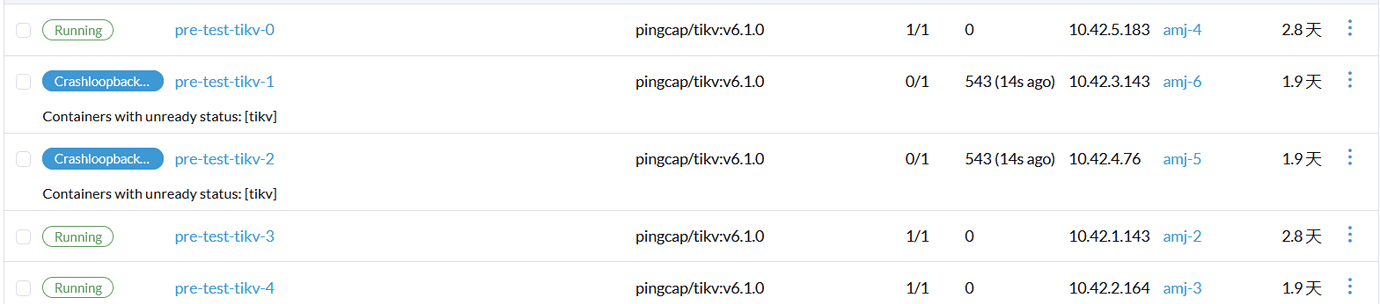
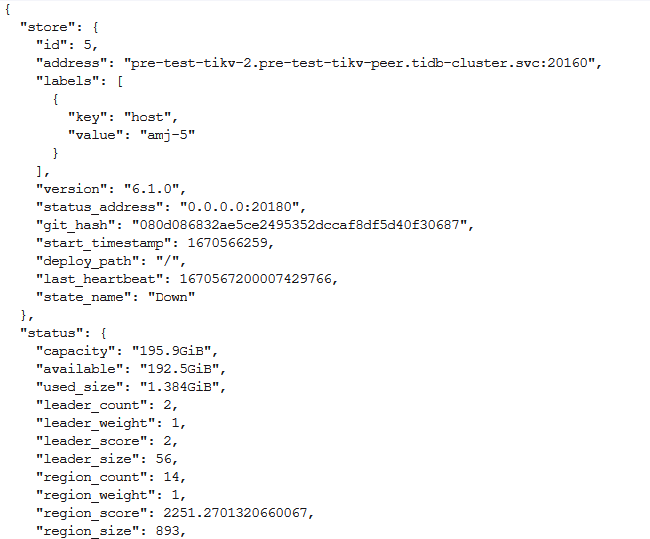
Logs
I1213 07:29:34.989188 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:34.997998 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:34.998262 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46472491”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.724813 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:45.732652 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.732806 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46472491”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.754481 1 tidbcluster_control.go:69] TidbCluster: [tidb-cluster/pre-test] updated successfully
I1213 07:29:45.865868 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:45.875868 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.876047 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46474051”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.843729 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:51.851744 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.852085 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46474051”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.869532 1 tidbcluster_control.go:69] TidbCluster: [tidb-cluster/pre-test] updated successfully
I1213 07:29:51.965092 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:51.972914 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.973294 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46474101”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
Version: 1.3.9