Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiKV莫名重启,TiKV leader掉底,时间段内查询失败
【TiDB Usage Environment】Production Environment
【TiDB Version】v5.1.1
【Reproduction Path】nothing
【Encountered Problem: Phenomenon and Impact】
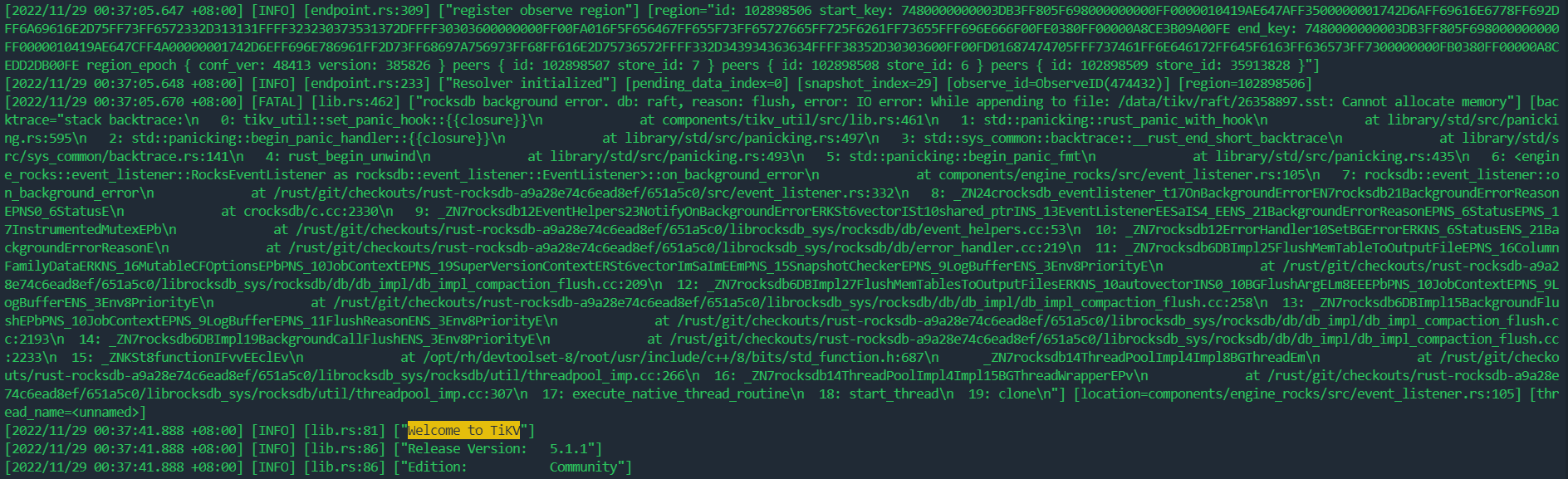
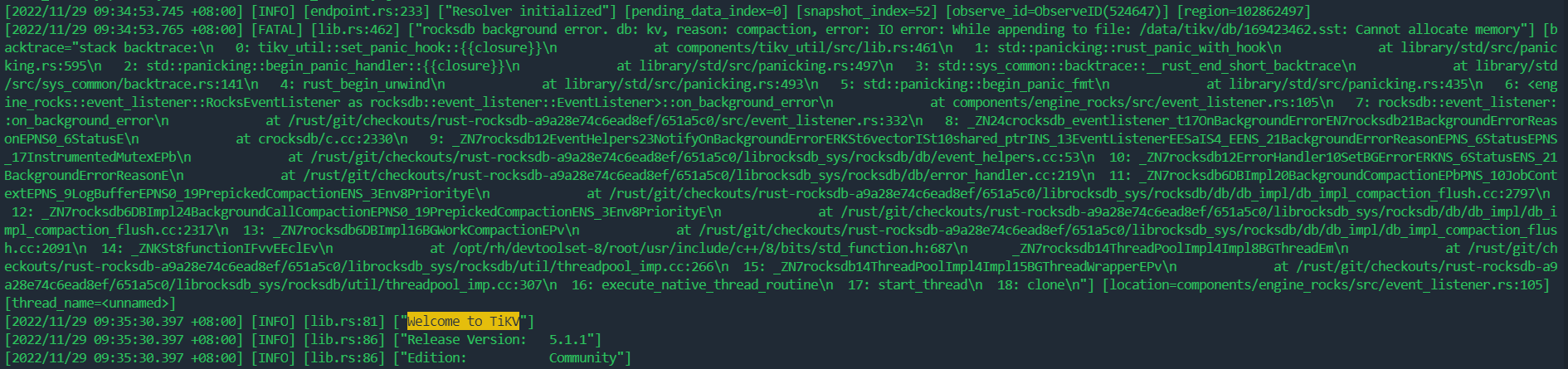
One TiKV leader in the cluster drops periodically, with no fixed time interval. Checking the TiKV logs reveals that the TiKV was restarted at those times.
Log context as follows:
【Resource Configuration】
【Attachments: Screenshots/Logs/Monitoring】
Go to the TiKV GitHub to submit an issue. It seems like you’ve encountered a bug. If it’s a known issue, you might consider upgrading. According to the logs, it’s version 5.1.1. Upgrading to a newer version might also have a fix.
IO error, Cannot allocate memory.
Check the OS logs?
There are no OOM-related entries in the system logs.
The machine has 128GB of memory, and there was no memory increase before the restart. Recently, the restarts have become more frequent.
I see there is a similar issue that is still open.
Thank you.
Strangely, the restart only happens on this particular TiKV. Not sure if taking this TiKV offline would solve the issue.
Not enough memory? Is there a memory failure? Check the OS logs.
There are no issues with the system logs or memory. The lifespan of the data disk storing TiKV is relatively low. Could this be the cause? We will observe after replacing the disk.
I want to know if there is any IO jitter when an issue occurs.
It looks like the detailed error information type is an IO error, one occurred during flush and the other during compaction. Check if the corresponding TiKV leader dropped due to full IO. I have a friend who also experienced the TiKV leader dropping, then coming back up and dropping again.
It looks like the spike occurs after the restart and then gradually decreases.
Based on this chart and the error message, the likelihood of an exception due to insufficient memory is quite high. The memory usage exceeds 80% in the chart, so any slight fluctuation in memory usage could lead to an out-of-memory (OOM) condition.
Execute journalctl -S '2022-11-29 00:20:00' -U '2022-11-29 01:00:00' as the root user to check for any clues before and after the specified time.
After replacing the disk, this issue has not reoccurred. It is likely that the error was caused by the low lifespan of the disk.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.