Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 关于监控的理解以及调优
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version]
[Reproduction Path] Data collection (executing select and insert operations), many times, the largest table level is tens of millions
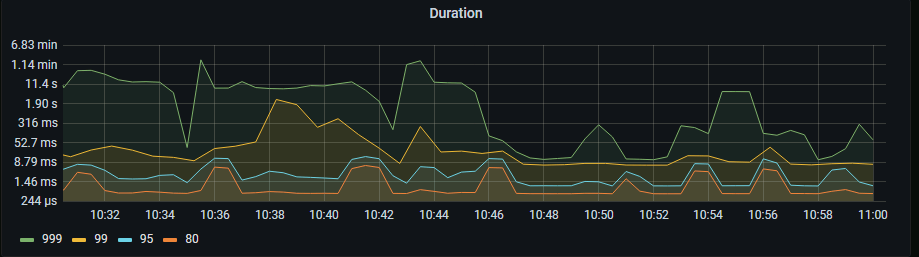
[Encountered Problem: Phenomenon and Impact] High latency, very slow read and write speed. Since we just started using TiDB, we have learned a lot of theoretical knowledge but have no concept of data scale. Hope experts can explain what data scale is considered large.
[Resource Configuration] pd3 16 cores 8g tikv3 16 cores 16g tidb*3 one with 64 cores 128g, others 16 cores 16g
[Attachments: Screenshots/Logs/Monitoring]