[TiDB Usage Environment] Testing
[TiDB Version] V6.1
Environment Configuration:
Number of Services:
tidb service: 1
pd: 1
tikv: 6
Configuration:
Three nodes in total, each node configured with: 12C64G
Network card: 10 Gigabit
Deployment Method:
K8S deployment
Underlying Storage:
ceph
[Encountered Issues: Problem Phenomenon and Impact]
The environment is newly deployed.
In the old environment, there are two large tables, one 100G and one 900G, along with other scattered business data totaling 500G, making up about 1.5T of data. Using the BR tool to back up and import the old data into the new environment, the 500G data took about 2 hours to import, with a relatively high overall data import efficiency, so the specific write speed was not noted.
After importing the new data, algorithm testing was performed (using tispark to read data from a 50G table, then adding a column and writing it back to a new table), and new data writing operations were carried out.
During step 3, it was noticeably felt that the data writing efficiency was very low.
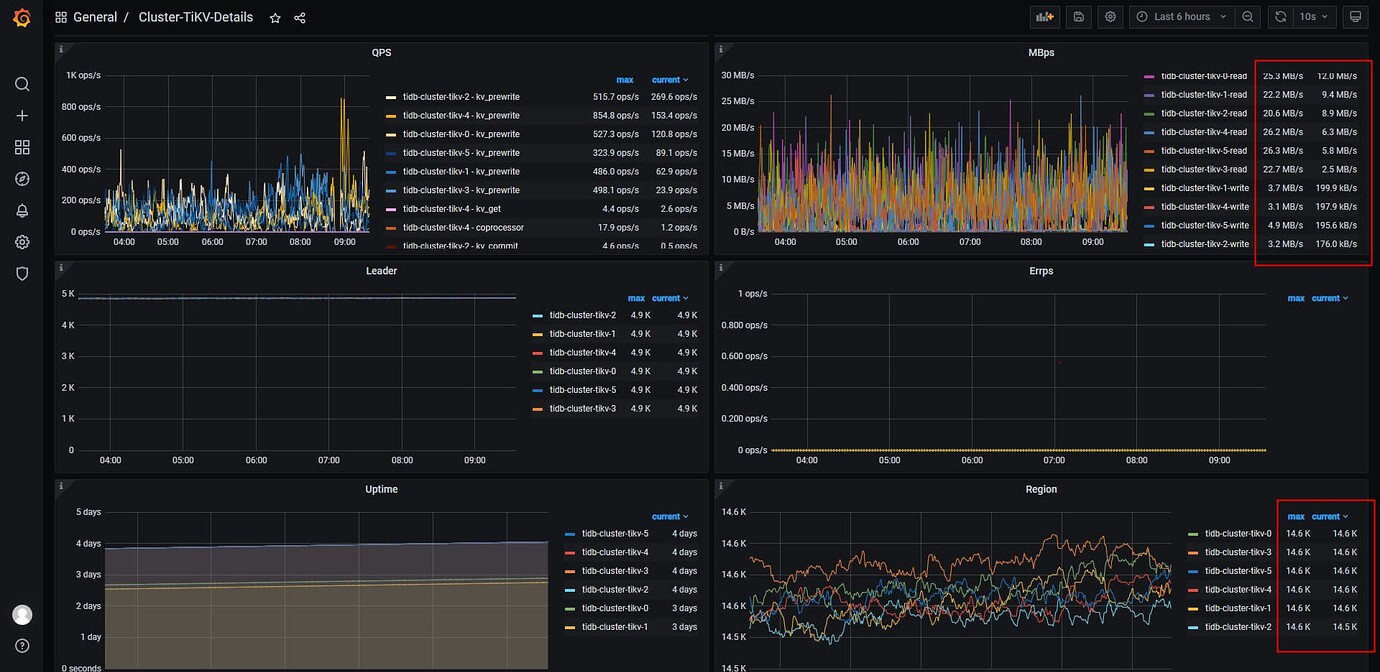
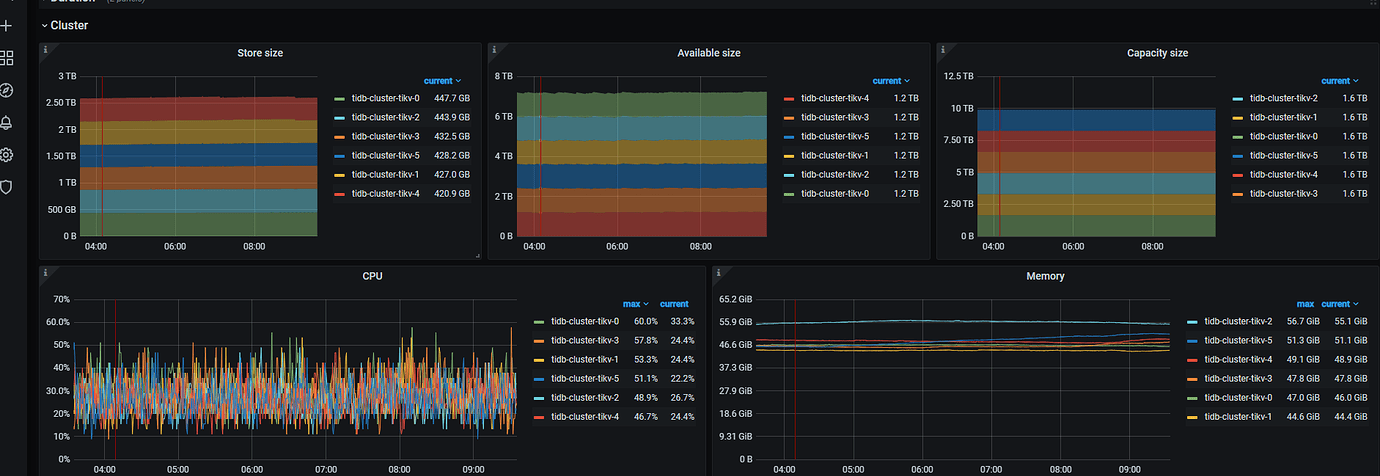
After deploying Grafana to monitor tikv read/write conditions, it was found that tikv’s read/write efficiency was very low.
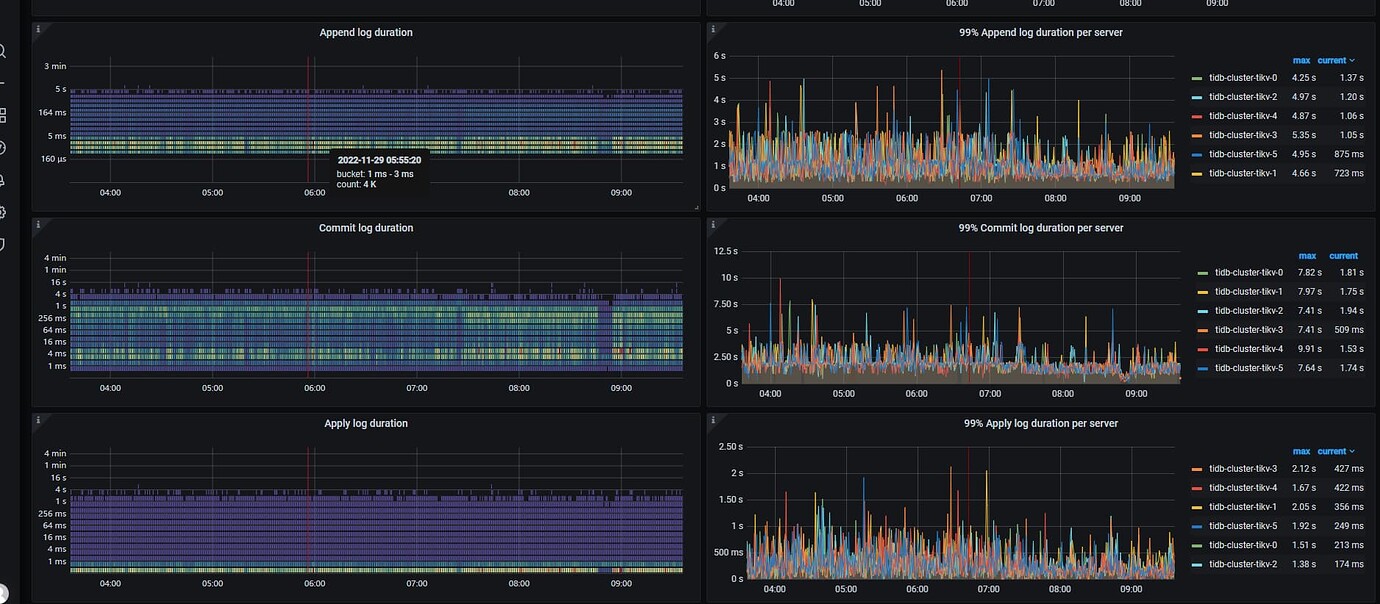
What type of storage disk was used in the old environment? Looking at the append/commit/apply duration, it seems like the disk performance is very poor.
The reasonable range for regions is 20,000 to 30,000. If the number exceeds this range, you need to refer to best practices and articles on massive region scheduling for optimization.
It looks like your applylog and commitlog times are quite long, which basically means that disk IO is relatively slow. If hardware conditions cannot be improved and you want to maximize TiDB throughput, you can adjust the configuration with the following ideas:
Tolerate higher latency slightly and batch more. For example, if one disk IO originally writes 1k data, you can batch more and write 4k at a time.
Increase the compression rate of the underlying RocksDB. With a higher compression rate, there will be less data on the disk, and correspondingly, the IO bandwidth usage will be reduced.
Increase data caching to keep more data in memory, thus reducing disk IO.
The main caches in TiKV are the size and number of memtables, and the size of the block cache. The size and number of memtables mainly affect writes and immediate reads after writes, while the block cache mainly affects reads. These have monitoring metrics, and you can check the cache hit rate in rocksdb-kv.
The main caches in TiDB are for caching coprocessor read results and small table caches. You can find the configurations.
There is no free lunch. To improve performance with HDD, you have to sacrifice in other areas, such as using more memory and CPU.
Take your time to adjust, it’s quite fun. The parameters listed above are just a few examples, and there are many other methods, such as increasing the region size to reduce the bandwidth occupied by network Raft interactions. However, increasing the region size can easily lead to hotspots, so you need to balance various aspects. TiDB is like a Swiss Army knife with many fancy configurations.
Regarding configuration 1, I would like to ask:
Is it setting max-batch-wait-time?
How can I control the amount of data sent each time through this value? For example, if I want each IO to write 4M, how should I set this value?