Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 7.5.1 ticdc 问题
Background:
We are planning to upgrade TiDB in-place with a rollback plan, from version 6.5.9 to 7.5.1. We found that the data on the source and target ends were synchronized before the upgrade, but after the upgrade, the delay of a TiCDC task became increasingly large. This TiCDC task synchronizes a partitioned table with about 40 partitions. There was no delay before the upgrade, but the delay increased after the upgrade.
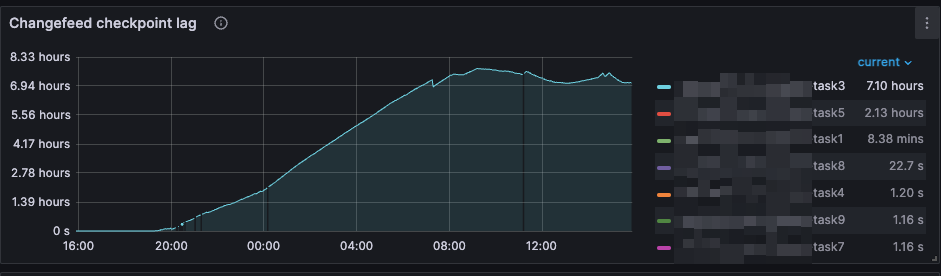
We have adjusted the following parameters (to no avail):
Increased worker-num
Increased worker-count
Increased per-table-memory-quota
Set cache-prep-stmts to false
We also found that the downstream computing nodes were under significant pressure, and even after increasing the downstream computing nodes (source end TiDB x 4, target end TiDB x 13), the issue was not resolved.
Monitoring revealed that update and delete operations did not change on the target end, but insert statements seemed to be converted to replace. After communicating with community support, we learned that after version 6.1.3, TiCDC automatically determines if there are duplicate data downstream, which can cause insert to become replace, potentially leading to performance degradation.
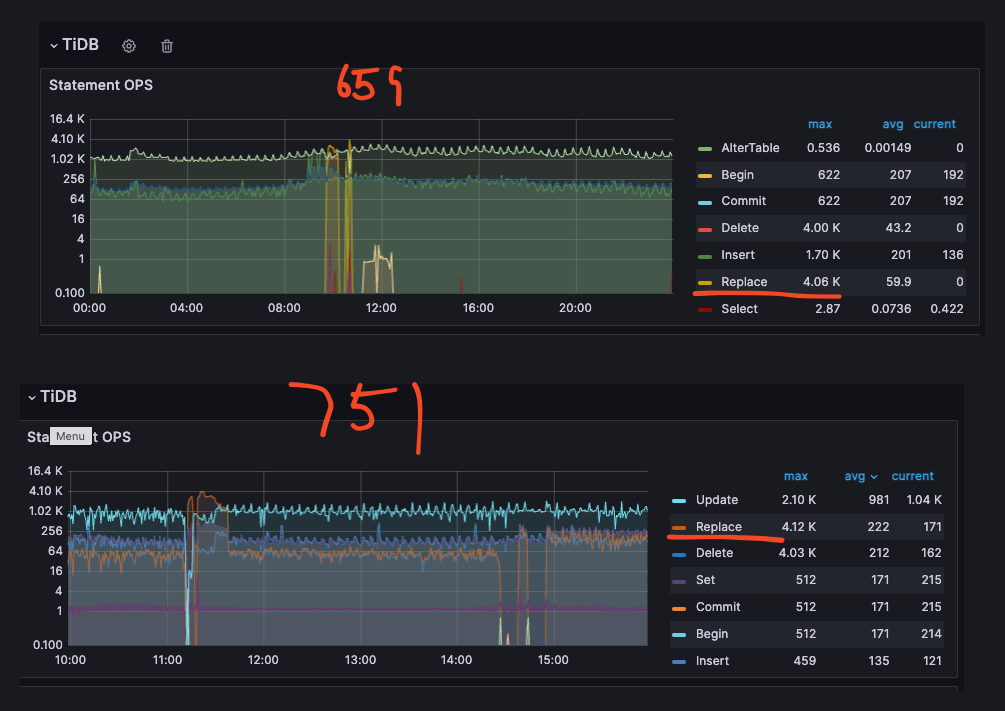
I would like to ask the following two questions:
- The synchronization task was created after version 6.5.9. If TiCDC’s behavior towards SQL has been consistent, why did it not become replace before the upgrade but did so after the upgrade?
- If the issue is that replace is slowing down the speed, how can we adjust TiCDC to reduce the delay?