Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 集群突然挂了一个tikv报错is out of range 启动不了
【TiDB Usage Environment】Production Environment
【TiDB Version】
【Reproduction Path】What operations were performed when the issue occurred
None
【Encountered Issue: Issue Phenomenon and Impact】
During cluster operation, one TiKV suddenly crashed
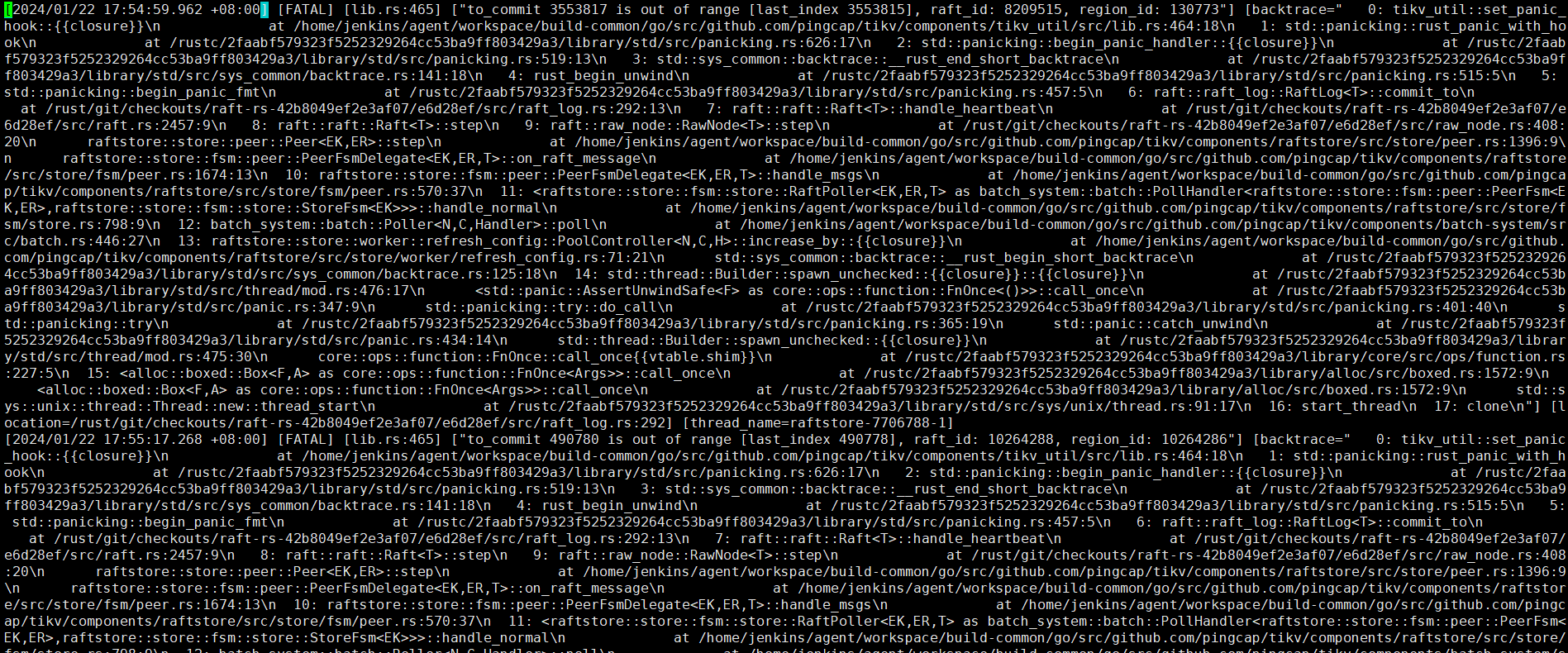
[2024/01/22 17:54:59.962 +08:00] [FATAL] [lib.rs:465] [“to_commit 3553817 is out of range [last_index 3553815], raft_id: 8209515, region_id: 130773”] [backtrace=" 0: tikv_util::set_panic_hook::{{closure}}\n at /home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tikv/components/tikv_util/src/lib.rs:464:18\n
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots/Logs/Monitoring】
This is most likely a bug. Check on GitHub to see if it’s a bug. Your cluster version is also quite old.
I feel a bit confused. I don’t understand the situation, it seems like the code I pulled and the package I deployed are in a bad environment?
Did the node suddenly drop while the cluster was running normally, or did the issue occur under other circumstances?
The packaging of TiDB is also integrated into Jenkins.
This is unrelated. This is a bug that hasn’t been fixed for 2 years. The issue the original poster mentioned should be a different bug.
v5.4.2 feels not old. It’s not good to upgrade in a production environment. I saw other posts with the same issue.
Official, production environment installed and deployed with tiup
A TiKV node suddenly went down and couldn’t be restarted while the cluster was running normally. The tikv_stderr.log on the node showed this error.
Just scale down and then scale up again, no need to worry.
Region 130773 has an issue. Delete this peer and fix it.
pd-ctl>> operator add remove-peer <region_id> <store_id>
Then use tikv-ctl on that TiKV instance to mark the Region’s replica as tombstone to skip the health check during startup:
tikv-ctl --data-dir /path/to/tikv tombstone -p 127.0.0.1:2379 -r <region_id>
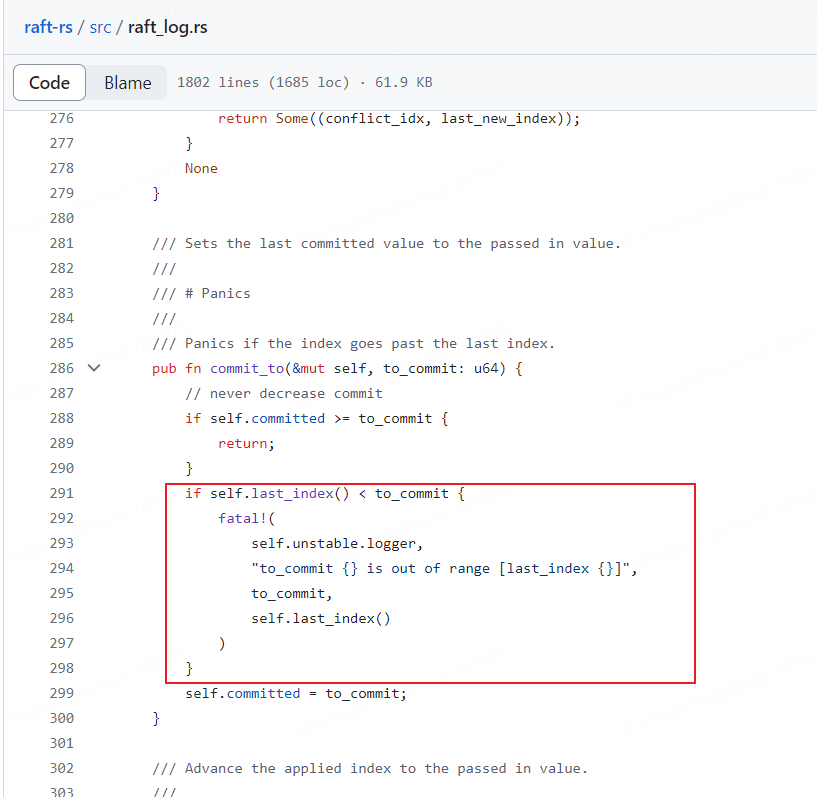
This roughly means: the logs of this node have reached the last_index, but to commit, the commit has exceeded the local logs. So it panicked.
The node has already dropped, can it still execute scaling down? Does it need to be forced?
I tried deleting, but the more I delete, the more it increases. The deletion speed can’t keep up with the increase. Should I stop the nodes first? How do I stop them?
Are there errors in more than one region? Then just delete this node directly. Physically destroy it. Then execute store delete xxx in PD to delete this store. After this store becomes a tombstone, delete the TiKV directory on it and pull up a new one. The premise is that your cluster has only one faulty TiKV. If there are more than one, you might lose multiple replicas, and the above operations will not be applicable.
It is possible to force scale-in.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.