[TiDB Usage Environment] Production Environment
[TiDB Version]
v4.0.14
[Reproduction Path] Operations performed that led to the issue
Deployed TiDB v4.0.14 on a cloud server with 3 TiKV nodes. After one TiKV node crashed and restarted, it failed to come back up and panicked. This caused the entire cluster to become unavailable.
[Encountered Issue: Problem Description and Impact]
Finally resolved the issue by adding a new TiKV node, shutting down the faulty node, and restarting the remaining 2 TiKV nodes.
[Resource Configuration] Navigate to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
Here is the TiKV error log:
{"log":"[2023/07/20 12:49:05.709 +08:00] [FATAL] [lib.rs:481] [\"to_commit 1238767 is out of range [last_index 1238765], raft_id: 893827, region_id: 893825\"] [backtrace=\"stack backtrace:\\n 0: tikv_util::set_panic_hook::{{closure}}\\n at components/tikv_util/src/lib.rs:480\\n 1: std::panicking::rust_panic_with_hook\\n at src/libstd/panicking.rs:475\\n 2: rust_begin_unwind\\n at src/libstd/panicking.rs:375\\n 3: std::panicking::begin_panic_fmt\\n at src/libstd/panicking.rs:326\\n 4: raft::raft_log::RaftLog\u003cT\u003e::commit_to\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/\u003c::std::macros::panic macros\u003e:9\\n 5: raft::raft::Raft\u003cT\u003e::handle_heartbeat\\n at rust/git/checkouts/raft-rs-841f8a6db665c5c0/b5f5830/src/raft.rs:1877\\n 6: raft::raft::Raft\u003cT\u003e::step_follower\\n at rust/git/checkouts/raft-rs-841f8a6db665c5c0/b5f5830/src/raft.rs:1718\\n raft::raft::Raft\u003cT\u003e::step\\n at rust/git/checkouts/raft-rs-841f8a6db665c5c0/b5f5830/src/raft.rs:1129\\n 7: raft::raw_node::RawNode\u003cT\u003e::step\\n at rust/git/checkouts/raft-rs-841f8a6db665c5c0/b5f5830/src/raw_node.rs:339\\n raftstore::store::peer::Peer::step\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/peer.rs:941\\n raftstore::store::fsm::peer::PeerFsmDelegate\u003cT,C\u003e::on_raft_message\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/fsm/peer.rs:1206\\n 8: raftstore::store::fsm::peer::PeerFsmDelegate\u003cT,C\u003e::handle_msgs\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/fsm/peer.rs:455\\n 9: \u003craftstore::store::fsm::store::RaftPoller\u003cT,C\u003e as batch_system::batch::PollHandler\u003craftstore::store::fsm::peer::PeerFsm\u003cengine_rocks::engine::RocksEngine\u003e,raftstore::store::fsm::store::StoreFsm\u003e\u003e::handle_normal\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/raftstore/src/store/fsm/store.rs:785\\n 10: batch_system::batch::Poller\u003cN,C,Handler\u003e::poll\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/batch-system/src/batch.rs:325\\n 11: batch_system::batch::BatchSystem\u003cN,C\u003e::spawn::{{closure}}\\n at home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tikv/components/batch-system/src/batch.rs:402\\n std::sys_common::backtrace::__rust_begin_short_backtrace\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libstd/sys_common/backtrace.rs:136\\n 12: std::thread::Builder::spawn_unchecked::{{closure}}::{{closure}}\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libstd/thread/mod.rs:469\\n \u003cstd::panic::AssertUnwindSafe\u003cF\u003e as core::ops::function::FnOnce\u003c()\u003e\u003e::call_once\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libstd/panic.rs:318\\n std::panicking::try::do_call\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libstd/panicking.rs:292\\n std::panicking::try\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8//src/libpanic_unwind/lib.rs:78\\n std::panic::catch_unwind\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libstd/panic.rs:394\\n std::thread::Builder::spawn_unchecked::{{closure}}\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libstd/thread/mod.rs:468\\n core::ops::function::FnOnce::call_once{{vtable.shim}}\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/libcore/ops/function.rs:232\\n 13: \u003calloc::boxed::Box\u003cF\u003e as core::ops::function::FnOnce\u003cA\u003e\u003e::call_once\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/liballoc/boxed.rs:1022\\n 14: \u003calloc::boxed::Box\u003cF\u003e as core::ops::function::FnOnce\u003cA\u003e\u003e::call_once\\n at rustc/0de96d37fbcc54978458c18f5067cd9817669bc8/src/liballoc/boxed.rs:1022\\n std::sys_common::thread::start_thread\\n at src/libstd/sys_common/thread.rs:13\\n std::sys::unix::thread::Thread::new::thread_start\\n at src/libstd/sys/unix/thread.rs:80\\n 15: \u003cunknown\u003e\\n 16: clone\\n\"] [location=/rust/git/checkouts/raft-rs-841f8a6db665c5c0/b5f5830/src/raft_log.rs:237] [thread_name=raftstore-22185-0]\n","stream":"stderr","time":"2023-07-20T04:49:05.709255578Z"}
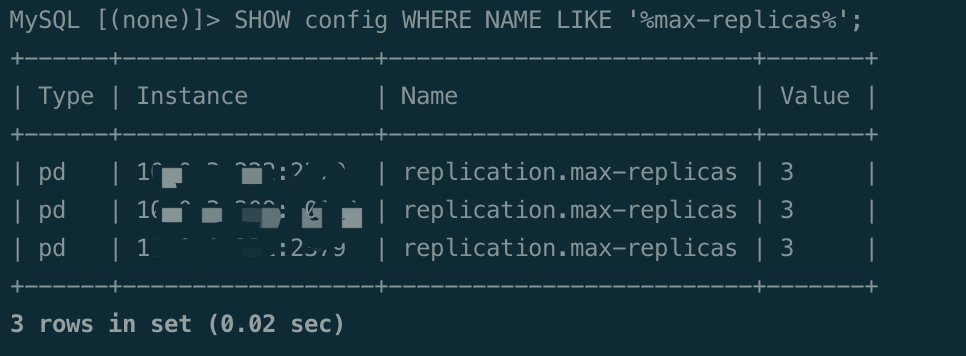
SHOW config WHERE NAME LIKE ‘%max-replicas%’;
What is the max-replica parameter? Why does the entire cluster become unavailable when one of the three TiKV nodes goes down…
This has already been resolved by adding a new TiKV, stopping the faulty KV, and restarting the remaining two KVs. However, the cause needs to be investigated.
I don’t know which step worked. Anyway, after performing these operations, the broken KV is still in a stopped state. It hasn’t been taken offline from pd-ctl, keeping it for investigation.
The 4.0 version has this issue where the raftstore.sync-log parameter is set to false. When a TiKV node restarts due to power outages or similar reasons, it will cause TiKV to panic and fail to start. You must use the tikv-ctl tool to recover the Region. In version 5.0, this parameter was removed, and the default is set to true.
Version 4.0 is indeed quite old, and encountering such issues is inevitable. It is recommended to upgrade to at least 5.4, which will be much more stable.
I haven’t used version 4.0, but with versions 5 and 6, a 3-replica 3-node TiKV setup won’t be affected by the failure of one node; the remaining 2 nodes will still provide service. If there are issues with version 4.0, it’s hard to pinpoint the cause unless you dig into the source code. Community staff will probably just recommend upgrading your version…