Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: dm集群有一个worker突然起不来
【TiDB Usage Environment】Production Environment
【TiDB Version】
【Reproduction Path】What operations were performed when the issue occurred
【Encountered Issue: Issue Phenomenon and Impact】
【Resource Configuration】
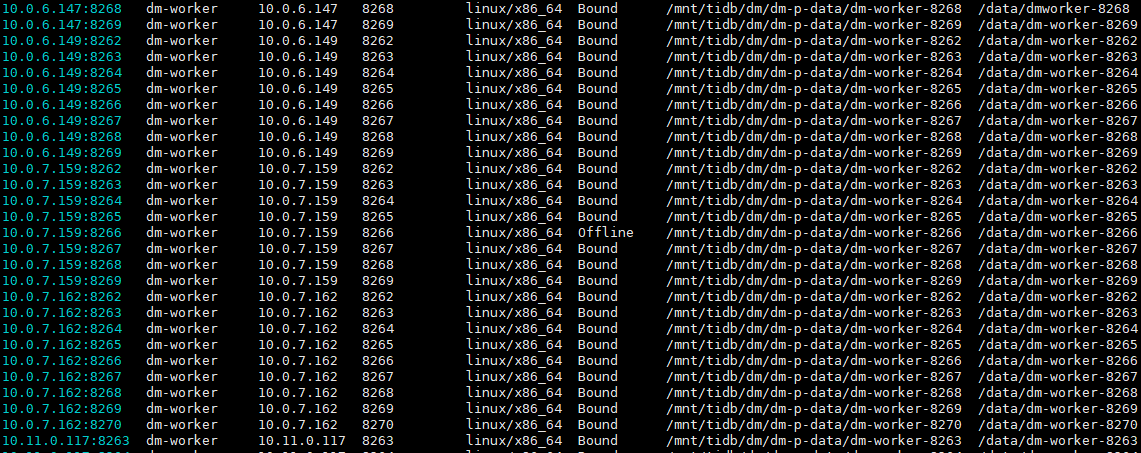
【Attachments: Screenshots/Logs/Monitoring】
Using the command tiup dm start <cluster_name> -N <worker_ip> fails to start, not sure how to troubleshoot the error.
There should be an error when it fails to start, telling you which directory under tiup to check for detailed information. Post that information here, then find the tiup logs and post them as well. After that, locate the dm-worker logs in the deploy directory corresponding to dm-worker, and find the logs at the time point when you tried to start.
What keywords should I search for? There are so many logs, it’s hard to distinguish them.
Just post the logs from five minutes before and after you executed the start command, and we should be able to identify the issue.
Go to the node with the startup exception and check the error log.
The dm-worker.log log will contain relevant exception information.
Check the status of the task with the command: tiup dmctl --master-addr=192.168.2.43:8261 query-status task-192.168.2.42-3306.yaml
Has the task already started?