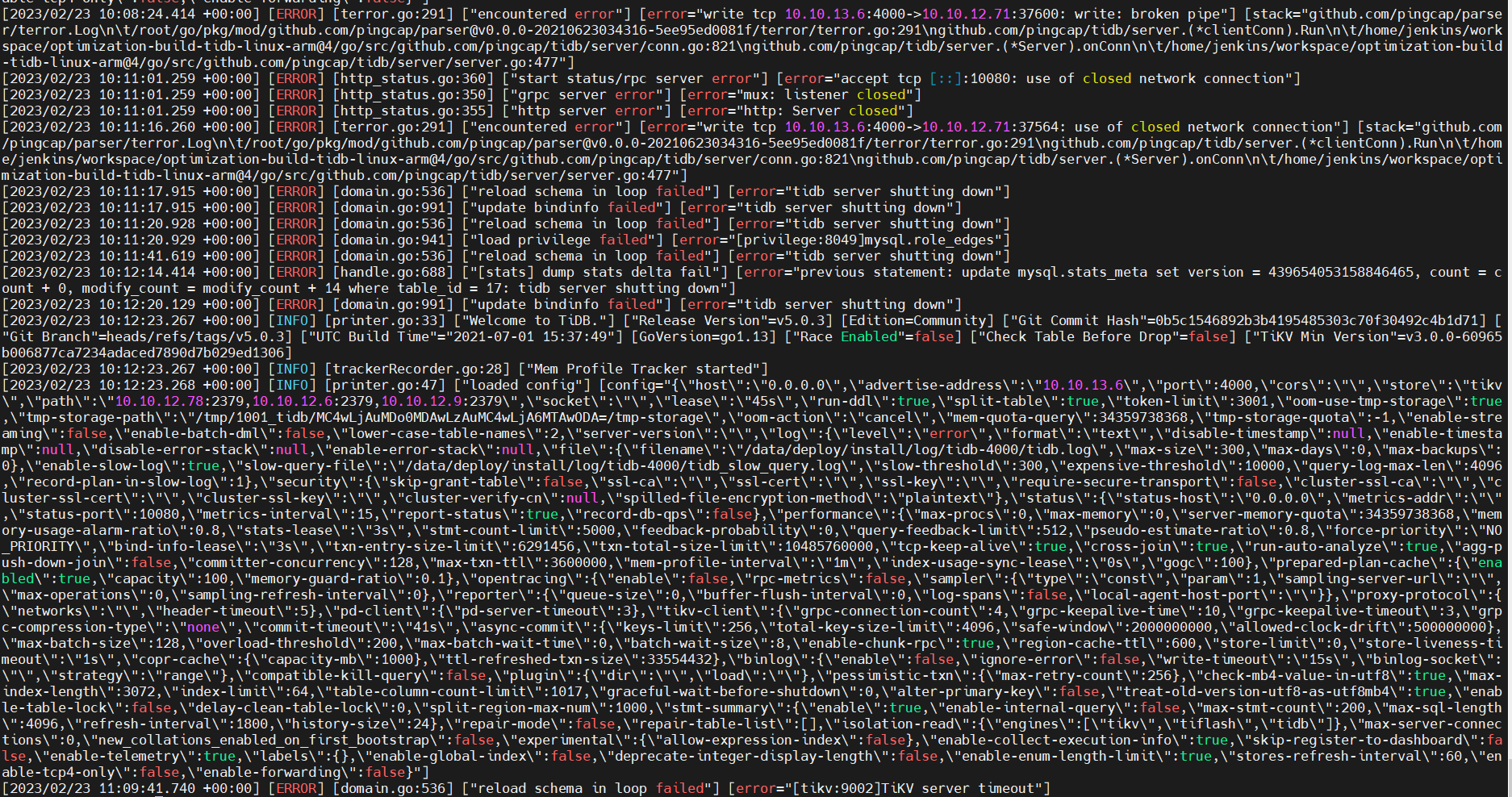
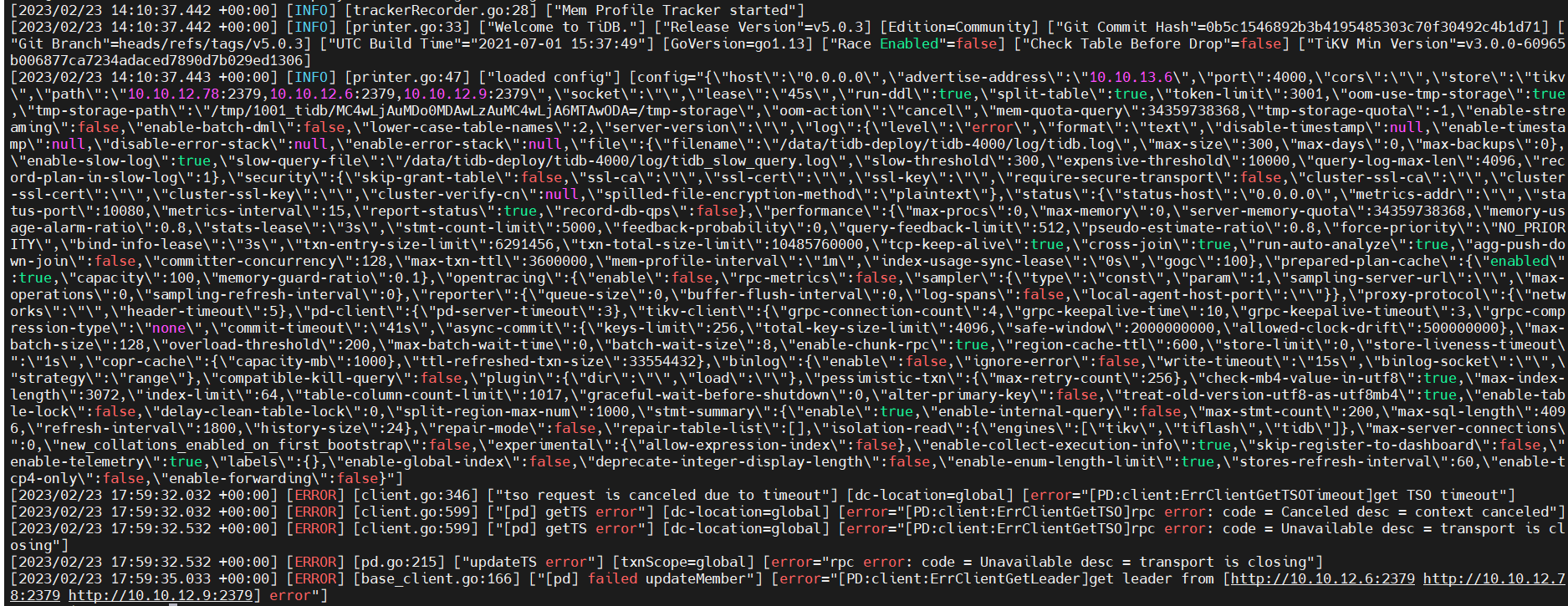
There were originally two TiDB nodes. After I scaled down one node and then scaled up one node to a new machine, the new TiDB node exhibited some abnormal behavior.
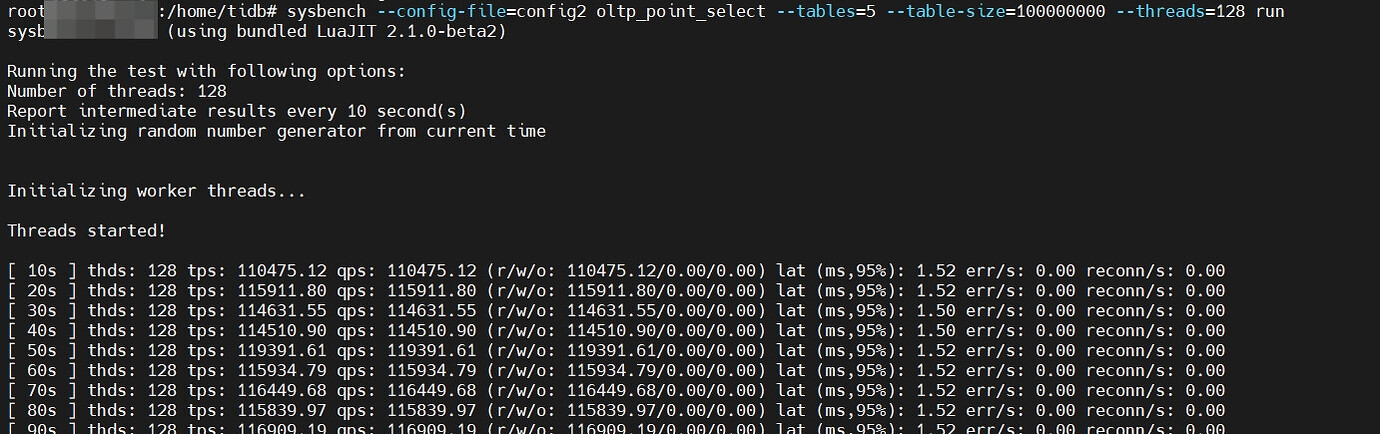
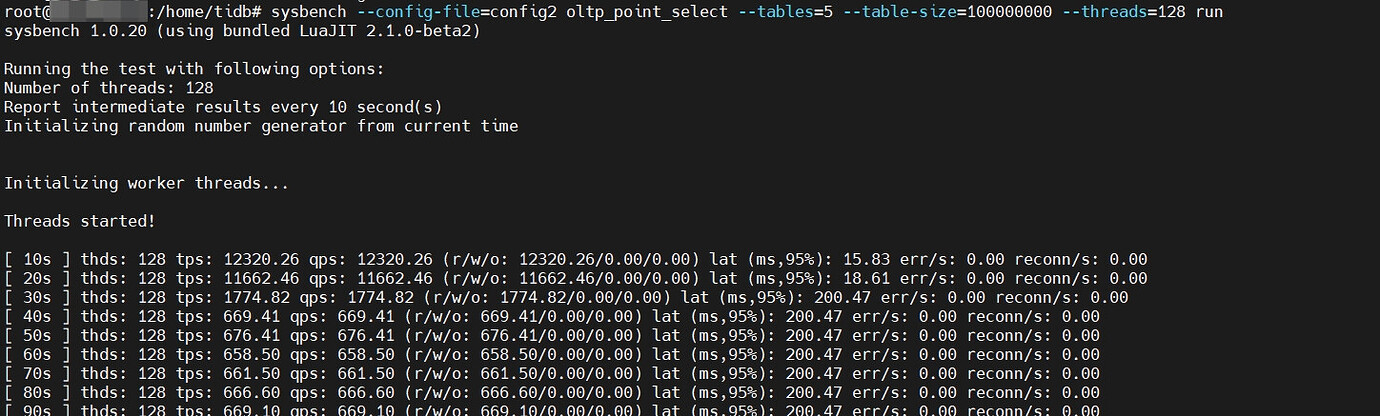
Conducting sysbench tests separately through the two TiDB nodes, the old node had a much higher QPS than the new node, and there were many errors during the new node’s test.
Old node:
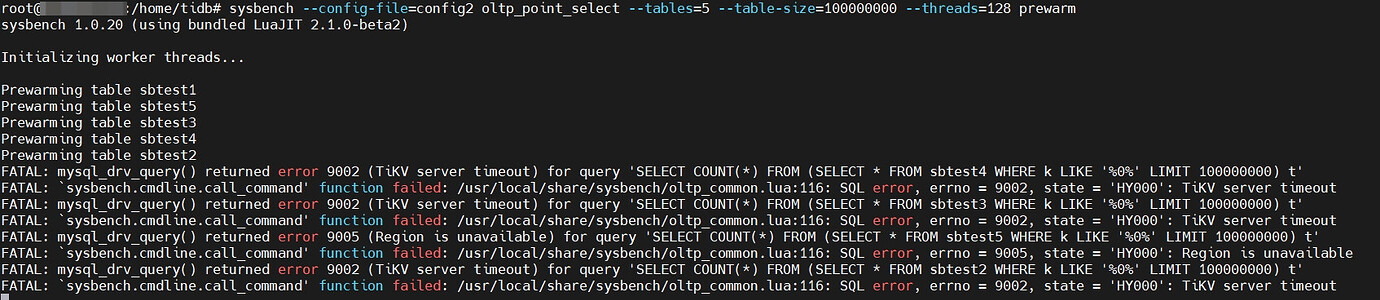
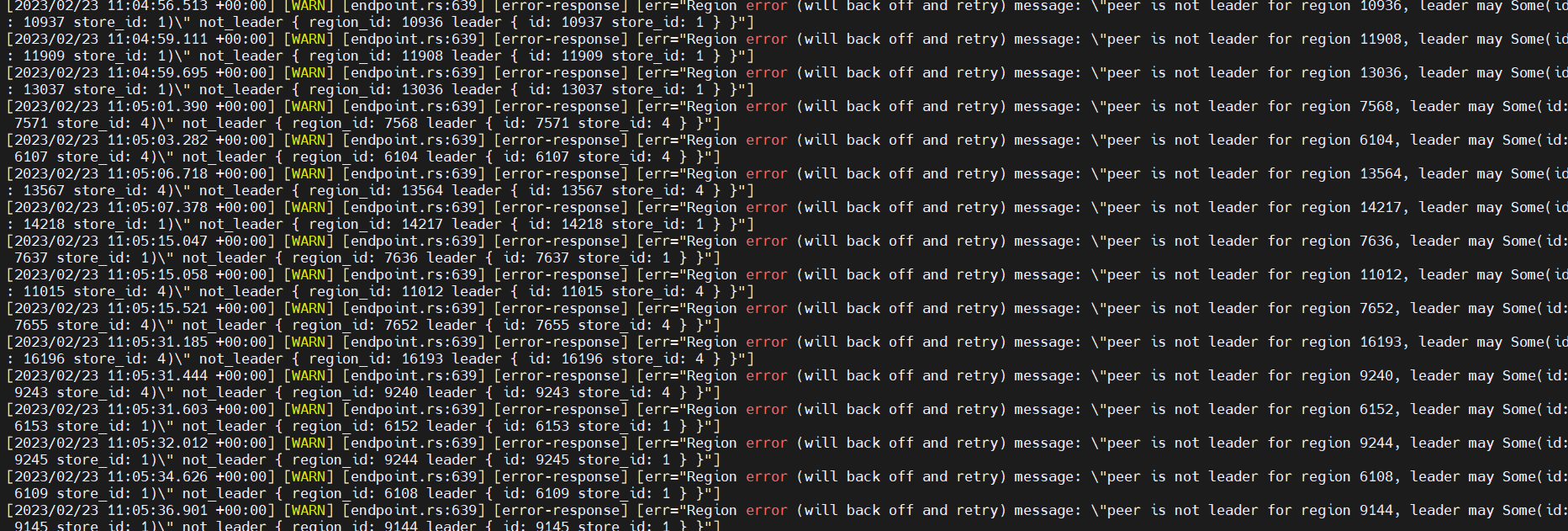
Directly deleted the original cluster, created a new cluster after checking, still encountered the above issue. The error log of the new TiDB node is as follows:
If the issue persists after rebuilding, it might be due to hardware configuration problems with the new machine. Are the bandwidth, IOPS, memory, and CPU up to standard or consistent with the original node?
Are the versions of the various components unified? If not rebuilt, it might be a cache issue with TiDB itself. If rebuilt, it feels like a resource issue or a version issue.
From configuration one to configuration three, the newly added machine in configuration three has only one NUMA node, which is equivalent to half of the first three machines.