Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tiflash5.4.2升级6.1.2异常
【TiDB Usage Environment】Production Environment / Test / Poc
Production Environment
【TiDB Version】
Tidb 5.4.2
tikv 5.4.2
tiflash 5.4.2 upgraded to 6.1.2
【Reproduction Path】What operations were performed when the issue occurred
Some tiflash nodes were upgraded to 6.1.2
【Encountered Issue: Issue Phenomenon and Impact】
Some tiflash instances failed to start and frequently restarted
【Resource Configuration】
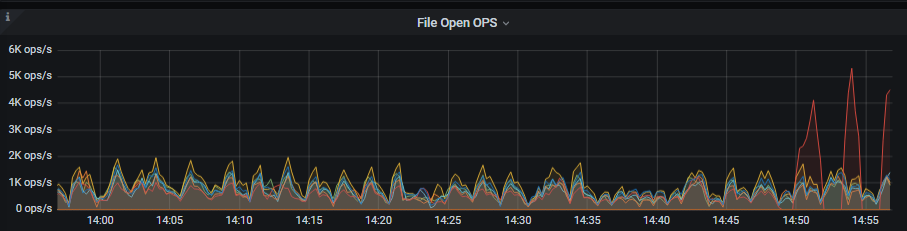
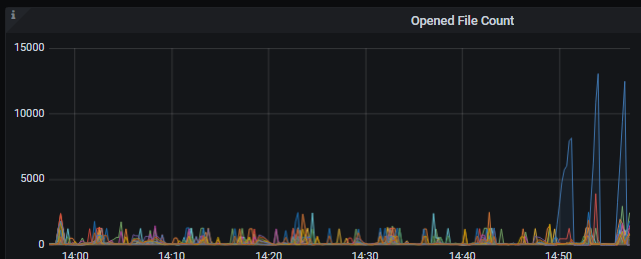
【Attachments: Screenshots/Logs/Monitoring】
[2022/11/09 16:39:34.654 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 109247004, message: NOT_FOUND”] [thread_id=55]
[2022/11/09 16:39:34.655 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 109646432, message: NOT_FOUND”] [thread_id=34]
[2022/11/09 16:39:34.660 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 126129822, message: NOT_FOUND”] [thread_id=33]
[2022/11/09 16:39:34.662 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 131281910, message: NOT_FOUND”] [thread_id=35]
[2022/11/09 16:39:34.665 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 132981372, message: NOT_FOUND”] [thread_id=37]
[2022/11/09 16:39:34.666 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 127647935, message: NOT_FOUND”] [thread_id=39]
[2022/11/09 16:39:34.784 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 123797949, message: NOT_FOUND”] [thread_id=36]
[2022/11/09 16:39:34.785 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 136227759, message: NOT_FOUND”] [thread_id=40]
[2022/11/09 16:39:34.874 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 89987343, message: NOT_FOUND”] [thread_id=41]
[2022/11/09 16:39:34.874 +08:00] [WARN] [CoprocessorHandler.cpp:143] [“CoprocessorHandler:RegionException: region 89987361, message: NOT_FOUND”] [thread_id=38]
[2022/11/09 16:40:42.454 +08:00] [ERROR] [BaseDaemon.cpp:377] [BaseDaemon:########################################] [thread_id=115]
[2022/11/09 16:40:42.466 +08:00] [ERROR] [BaseDaemon.cpp:378] [“BaseDaemon:(from thread 73) Received signal Segmentation fault(11).”] [thread_id=115]
[2022/11/09 16:40:42.476 +08:00] [ERROR] [BaseDaemon.cpp:406] [“BaseDaemon:Address: NULL pointer.”] [thread_id=115]
[2022/11/09 16:40:42.476 +08:00] [ERROR] [BaseDaemon.cpp:414] [“BaseDaemon:Access: read.”] [thread_id=115]
[2022/11/09 16:40:42.476 +08:00] [ERROR] [BaseDaemon.cpp:423] [“BaseDaemon:Address not mapped to object.”] [thread_id=115]
[2022/11/09 16:40:46.634 +08:00] [ERROR] [BaseDaemon.cpp:570] [“BaseDaemon:\n 0x1ed3dd1\tfaultSignalHandler(int, siginfo_t*, void*) [tiflash+32325073]\n
\tlibs/libdaemon/src/BaseDaemon.cpp:221\n 0x7f4f48fc4630\t [libpthread.so.0+63024]\n 0x7a8fae9\tDB::PageReader::getFileUsageSta
tistics() const [tiflash+128514793]\n \tdbms/src/Storages/Page/PageStorage.cpp:441\n 0x79530d2\tDB::RegionPersister::getFileUsageStatistics()
const [tiflash+127217874]\n \tdbms/src/Storages/Transaction/RegionPersister.cpp:385\n 0x719d741\tDB::AsynchronousMetrics::getPageStorageFile
Usage() [tiflash+119134017]\n \tdbms/src/Interpreters/AsynchronousMetrics.cpp:137\n 0x719cafc\tDB::AsynchronousMetrics::update() [tiflash+119
130876]\n \tdbms/src/Interpreters/AsynchronousMetrics.cpp:206\n 0x719c0aa\tDB::AsynchronousMetrics::run() [tiflash+119128234]\n
\tdbms/src/Interpreters/AsynchronousMetrics.cpp:107\n 0x1d71a21\tvoid* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_st
ruct, std::__1::default_deletestd::__1::__thread_struct >, DB::AsynchronousMetrics::AsynchronousMetrics(DB::Context&)::‘lambda’()> >(void*) [tiflash+30874145]\n
\t/usr/local/bin/…/include/c++/v1/thread:291\n 0x7f4f48fbcea5\tstart_thread [libpthread.so.0+32421]”] [thread_id=115]
[2022/11/09 16:40:49.568 +08:00] [WARN] [CoprocessorHandler.cpp:134] ["CoprocessorHandler:LockException: region 132424683, message: "] [thread_id=34]
[2022/11/09 16:40:52.336 +08:00] [WARN] [CoprocessorHandler.cpp:134] ["CoprocessorHandler:LockException: region 132424683, message: "] [thread_id=46]