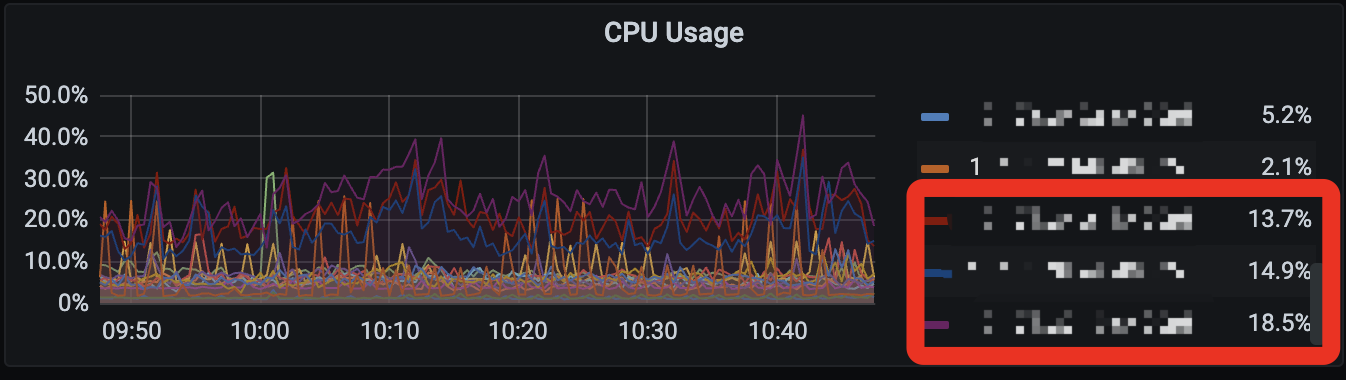
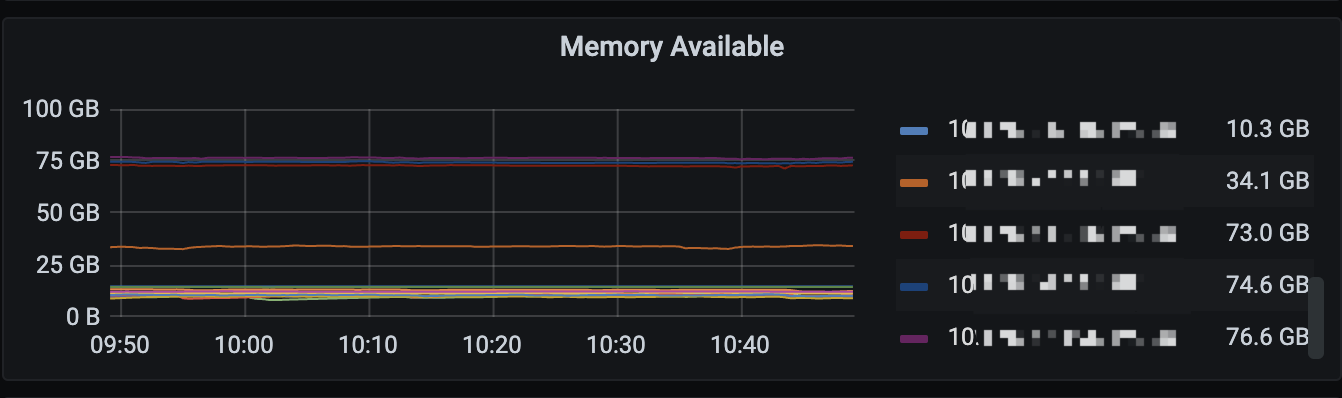
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 900w表添加索引超过一天还没执行完,如何排查?
[TiDB Usage Environment] Online
[TiDB Version] v5.2.2
[Encountered Problem] Adding an index to a 9 million row table has not completed after more than a day. Running admin show ddl jobs, the ROW_COUNT stops changing after reaching a certain value. Filtering the tidb.log with the ddl keyword shows the following:
[2022/08/24 09:07:20.332 +08:00] [INFO] [reorg.go:284] [“[ddl] run reorg job wait timeout”] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next]
[2022/08/24 09:07:20.336 +08:00] [INFO] [ddl_worker.go:886] [“[ddl] schema version doesn’t change”] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:20.337 +08:00] [INFO] [ddl_worker.go:727] [“[ddl] run DDL job”] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[2022/08/24 09:07:25.401 +08:00] [INFO] [reorg.go:284] [“[ddl] run reorg job wait timeout”] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next]
[2022/08/24 09:07:25.404 +08:00] [INFO] [ddl_worker.go:886] [“[ddl] schema version doesn’t change”] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:25.405 +08:00] [INFO] [ddl_worker.go:727] [“[ddl] run DDL job”] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[2022/08/24 09:07:30.429 +08:00] [INFO] [reorg.go:284] [“[ddl] run reorg job wait timeout”] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next]
[2022/08/24 09:07:30.432 +08:00] [INFO] [ddl_worker.go:886] [“[ddl] schema version doesn’t change”] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:30.436 +08:00] [INFO] [ddl_worker.go:727] [“[ddl] run DDL job”] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[2022/08/24 09:07:35.467 +08:00] [INFO] [reorg.go:284] [“[ddl] run reorg job wait timeout”] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next]
[2022/08/24 09:07:35.470 +08:00] [INFO] [ddl_worker.go:886] [“[ddl] schema version doesn’t change”] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:35.471 +08:00] [INFO] [ddl_worker.go:727] [“[ddl] run DDL job”] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[Reproduction Path] Executing admin cancel ddl jobs jobid and re-executing the index addition still results in the above phenomenon.
How can I troubleshoot which stage the DDL is stuck at and how to resolve it?