Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiDB集群副本调整(由三副本调整为一副本)
[Test Environment for TiDB] Testing
[TiDB Version] v7.5
[Reproduction Path]
[Encountered Issue: Problem Phenomenon and Impact] The historical data is approximately 2PB. The data needs to be imported into TiDB on a monthly basis and then backed up to a tape library. With the default cluster configuration of 3 replicas (the total storage space of the target TiKV cluster must be greater than (data source size multiplied by the number of replicas multiplied by 2), the final capacity would be (2 * 3 * 2 = 12PB). This is too large. Can it be set to 1 replica, with an overall plan of (2 * 1 * 1.2 = 2.4PB) capacity? Is this achievable? What are the impacts?
Are you planning to use it for cold data archiving and storage?
Yes, you can think of it that way.
Modification method:
set config pd replication.max-replicas=1;
Check;
show config where NAME like ‘%max-replicas%’;
It is recommended to set up a test environment and try it out. I haven’t noticed any issues when running on a single machine. Setting it to 1 will automatically adjust to 1 replica.
Okay, I’ll give it a try. I found some information that says the final backup size is equal to the data size. I’ll test it out.
Backup and Restore FAQ | PingCAP Documentation Center
How large is the backup data, and will there be replicas of the backup?
During the backup, the backup file for each Region is generated only at the Leader of that Region. Therefore, the backup size is equal to the data size, and there will be no extra replica data. So the final total size is approximately the total amount of TiKV data divided by the number of replicas.
However, if you want to restore data from the local backup, since each TiKV must be able to access all backup files, there will be replicas equal to the number of TiKV nodes during the final restoration.
This is a physical backup. If you want to back up to tape, I think flat files (csv) are better. Use dumpling for logical backup, export to csv format, and you can add where conditions for historical data.
TiKV has compression, and with the default 3 replicas, it won’t require 12P of space, probably just 3-4P. If you really want to use a single replica, you can modify it as mentioned above, but it’s hard to say if there will be any strange issues with a single replica.
Setting it to single-replica storage, although technically feasible, cannot ensure high availability.
Have you considered what would happen if a machine goes down and cannot be recovered, resulting in data loss? How is this addressed from a business perspective?
Is your 2PB data space the size of the disk files?
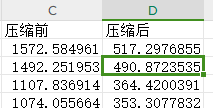
We previously migrated from MySQL, and even with 3 replicas in TiDB, the final data only occupied 70% of the disk space compared to MySQL, saving space.
The compression algorithm will be related to the specific data structure, data distribution, sparsity, etc. It is recommended that you test with real data to verify and analyze the final possible total space occupied.
For such a large amount of data, it is advisable to plan for the long term, and all judgments should be based on the test results verified in the actual environment.
Based on the compression algorithm, it won’t take up that much storage space. I suggest importing a portion of the data and then calculating and evaluating it.
I checked the information, and Dumpling is not suitable for exporting large amounts of data.
What is your upstream database? There should be corresponding data transfer tools available. First, check if there are any physical export tools, as these tools are often efficient and suitable for large-scale data migration tasks.
A single replica might encounter strange issues. It is recommended to use three replicas. With three replicas, 2P of data should roughly correspond to 3P of disk space. You can try it with one month’s data first.
If the upstream is MySQL, 2PB stored in TiDB with 3 replicas would generally be at most 3-4PB, not three times as much. TiDB’s underlying storage is different and it compresses the data. If you only use one replica, any node failure would directly render your database unusable, so it’s not recommended to use it this way.
The risk is relatively high, it is recommended to consider other solutions.
It is not very suitable to export too much at once, but since it is historical data, you can export it in batches. Dumpling can add where conditions.
Cold data archiving, using CDC to sync to MySQL would be great.
It is not recommended to switch the number of replicas online in the production system. It is suggested to create a cold data backup to free up space.
How did the original poster’s test go?
Is the data already in TiDB? If not, when data is imported into TiDB, it will be automatically compressed. The compression ratio is approximately 3:1. This is based on the size of the tables I have in production. If your data is 2PB, after compression and replication into 3 copies, it might still be a bit over 2PB.