Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 增加一台TiKV节点后,集群延迟变高,请教如何解决
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] v4.0.7
[Encountered Problem: Problem Phenomenon and Impact]
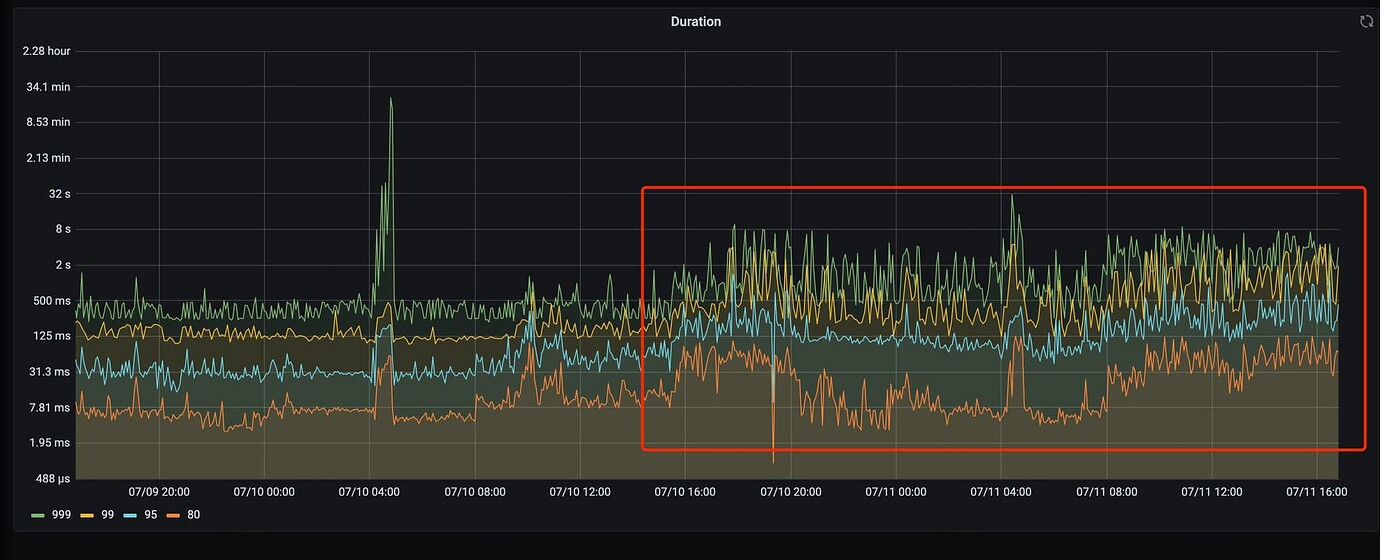
Added a TiKV node to the cluster, data is being balanced, and latency is very high. The following adjustments were made but had no effect:
Slow down
set config pd schedule.leader-schedule-limit=1;
set config pd schedule.merge-schedule-limit= 2;
set config pd schedule.max-pending-peer-count= 1;
set config pd schedule.replica-schedule-limit= 1;
set config pd schedule.max-snapshot-count = 1;
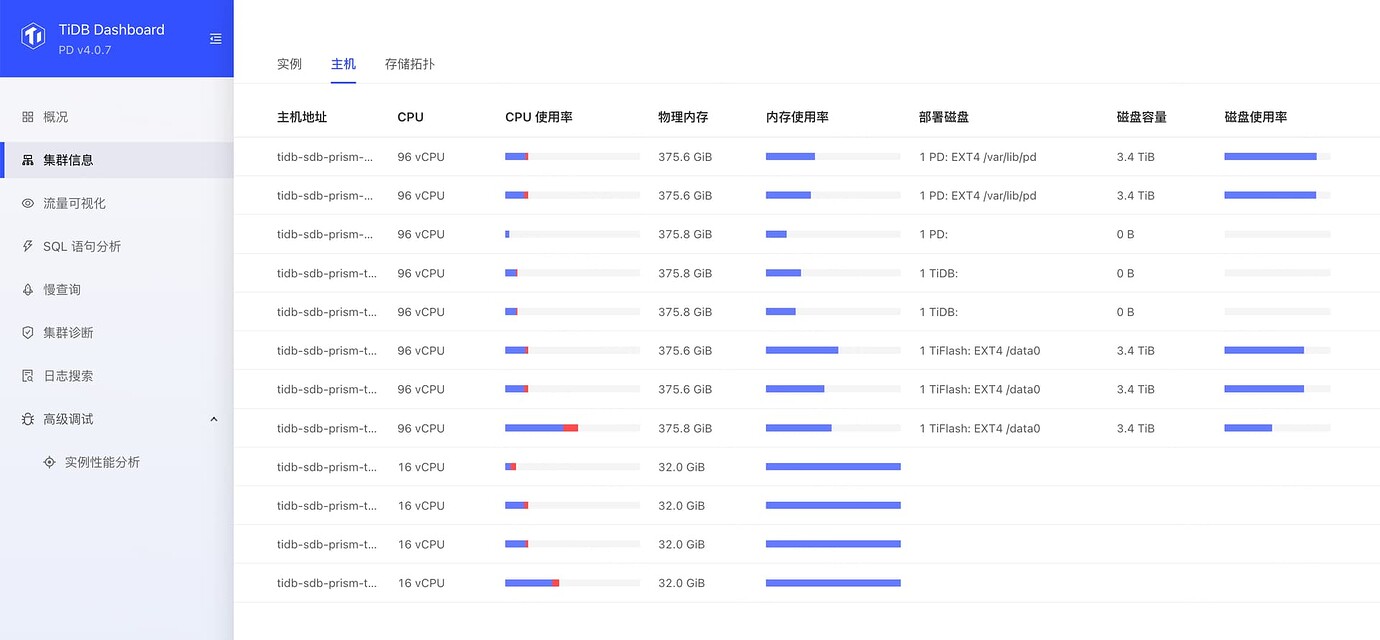
[Resource Configuration] Enter TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]