Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: analyze table 之后,统计信息还是会有不准的情况
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] 5.4.3
[Reproduction Path] Operations performed that led to the issue
[Encountered Issue: Problem Phenomenon and Impact]
The most frequently used TiDB version is 5.*, and I remember encountering situations many times during SQL tuning where the execution plan was inaccurate even after the table statistics were collected.
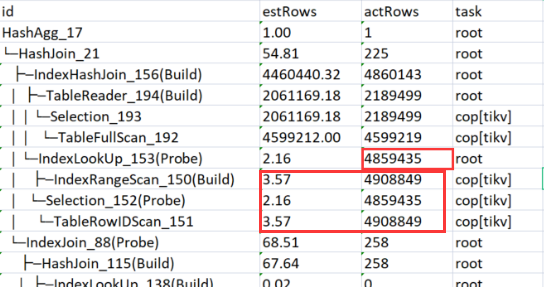
Example: Today, I encountered a subquery with a full table of 140 million rows, needing 40 million rows. Due to inaccurate statistics (just manually collected), it chose to use index back to the table, which was slower. In this case, a full table scan would have been better. The issue was resolved after using ignore index.

Has anyone else encountered situations where the execution plan is still inaccurate after collecting statistics for some tables?
I searched but couldn’t find an issue related to this problem, though I remember it happening many times.
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
Is the prepare_plan_cache enabled? Try turning it off and see if it helps.
I checked,
it’s not enabled.
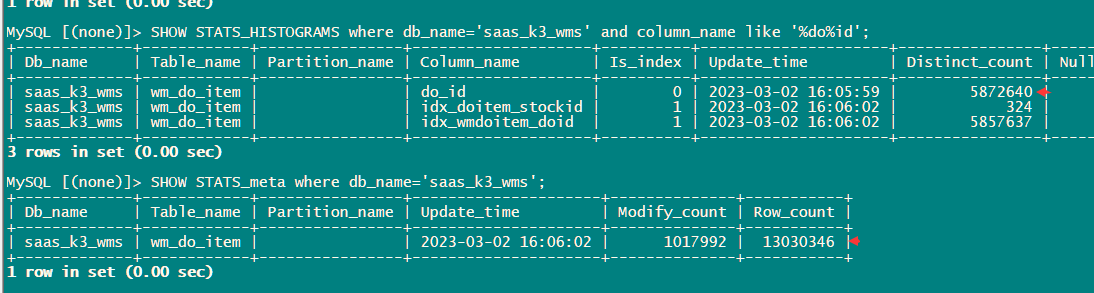
SHOW stats_histograms WHERE table_name=‘t1’;
Let’s take a look at the statistics of the table.
Has the histogram information been collected?
I directly used “analyze table t1”. In theory, it should collect everything.
The image you provided is not visible. Please provide the text you need translated.
plan replayer dump explain analyze select xxxx; Export the information
What version is your database? I’m using 6.1.1 to import.
The current version is 5.4.3, but I have also encountered this issue in other version 5 releases.
Could you share the table structure? How many indexes does this table have? On which fields are they?
I don’t quite understand, the table structure and statistics are unrelated, right?
show stats_buckets displays the histogram information of a column. If it doesn’t show up, use the column as a WHERE condition to execute an SQL query, and then check the range of your condition against the buckets.
There is no problem with the statistical information query.
It feels like it is directly estimated by row_count / distinct_count.
I don’t understand, why is there no do_id information in stats_histograms?
Are you referring to the column name?