Excuse me, teachers, when using DM to import data from MySQL to TiDB, after exporting the full data from MySQL and importing it into TiDB, I found that the tables in TiDB did not collect statistical information. This is very confusing. What could be the reason?
When DM imports full data into TiDB, it uses the lightning TiDB mode. Could this be related?
The statistics of TiDB and MySQL are different, right? Importing data should not automatically collect statistics; you need to collect them manually, right?
This might indeed be related to the TiDB mode of Lightning. Since v6, DM has defaulted to using Lightning’s TiDB mode to import full data, and the default parameter for Lightning’s TiDB mode is “optional,” which does not collect statistics.
[post-restore] # Configure whether to execute ADMIN CHECKSUM TABLE <table> for each table after the import is completed to verify data integrity. # Optional configurations: # - “required” (default). Executes CHECKSUM check after import completion. If the CHECKSUM check fails, it will report an error and exit. # - “optional”. Executes CHECKSUM check after import completion. If an error occurs, it will log a WARN message and ignore the error. # - “off”. Does not execute CHECKSUM check after import completion. # The default value is “required”. Since v4.0.8, the default value of checksum has been changed from “true” to “required”. # # Note: # 1. Checksum comparison failure usually indicates an import anomaly (data loss or inconsistency), so it is recommended to always enable Checksum. # 2. For compatibility with older versions, you can still set true and false for this configuration item, which have the same effect as required and off. checksum = “required” # Configure whether to execute ANALYZE TABLE <table> for all tables one by one after CHECKSUM completion. # The optional configurations for this setting are the same as checksum, but the default value is “optional”. analyze = “optional”
I imported the MySQL data into TiDB. In theory, during the import process, SQL is executed on TiDB, so the statistics information of TiDB should be updated accordingly.
This has nothing to do with it. This is about whether ANALYZE TABLE <table> operation is executed for all tables one by one after lightning import is completed.
Statistics should be updated by default during the data import process.
TiDB has an automatic statistics collection mechanism, but it doesn’t necessarily trigger right after you perform operations on the table. It depends on the parameters you set for analyze.
If you import data without selecting analyze one by one, you have to wait for automatic collection. Moreover, if you import too many large tables at once, the automatic collection may not be able to complete.
When importing data into TiDB (using TiDB mode of Lightning and executing replace SQL statements for data import), the table data volume in TiDB is continuously increasing. In theory, this should trigger the collection of statistics.
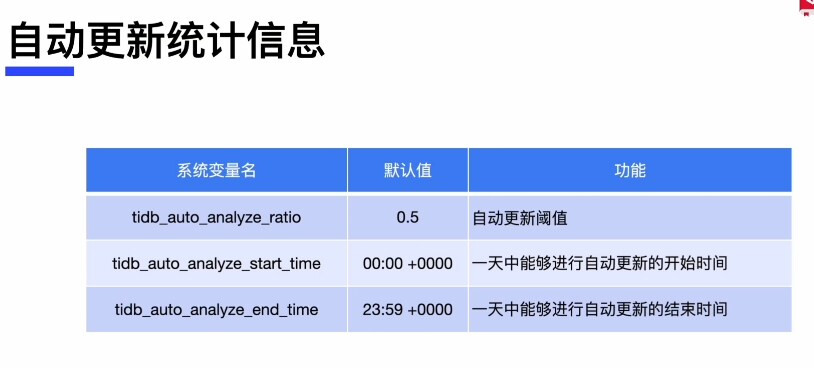
There are two conditions to trigger automatic statistics collection: 1) the table modification threshold reaches the first parameter I mentioned above, and 2) the time falls within the automatic statistics collection interval.
Assuming there is such a situation, during the process of full data import, the table keeps inserting data, causing the statistics not to be automatically collected. Then, during incremental synchronization, the amount of incremental data is relatively small and does not reach the trigger threshold for statistics (0.5), so the table’s statistics have never been automatically collected. Additionally, the table itself has a large amount of data, and the amount of synchronized data is too small to meet the conditions for automatic collection. This should be the reason.
I have suffered from this issue before. Migrated data into TiDB using Lightning at night, and the next morning there were a bunch of slow SQLs. Had to urgently analyze the table.
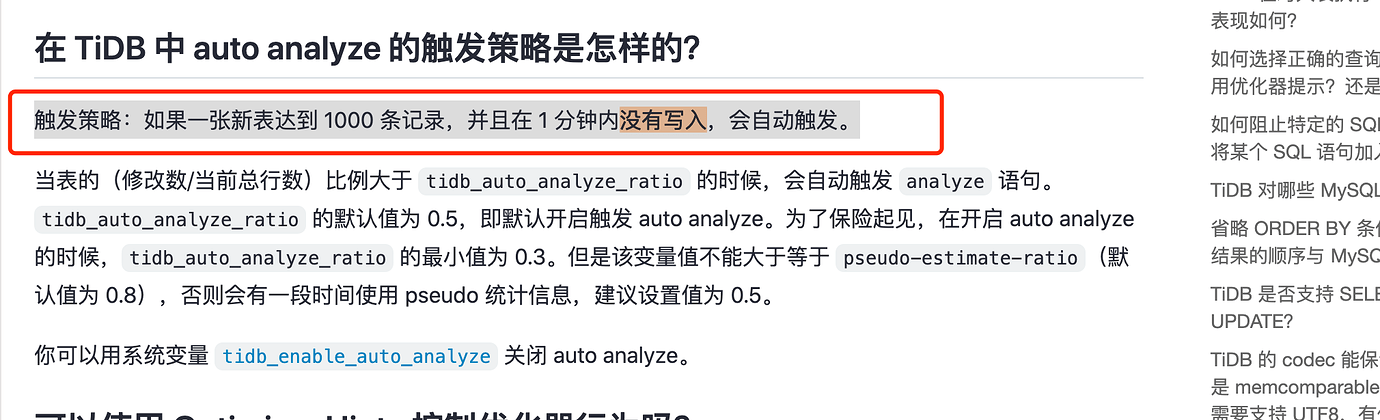
If table data is not written within 1 minute, statistics will be triggered. This design feels a bit rough. I wonder how other databases handle this? Do they have similar mechanisms?