Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: DM 6.1.1开启relay-log后,start-task成功但是relay-log不落盘
【TiDB Usage Environment】Production
【TiDB Version】6.1.1
【Encountered Problem】
The relay-log of dm-worker occasionally does not persist to disk. Using query-status shows that the task status is normal, and synchronization is also normal.
【Reproduction Path】
Unable to reproduce stably, suspect it is related to multiple task failures and multiple executions of resume-task.
【Problem Phenomenon and Impact】
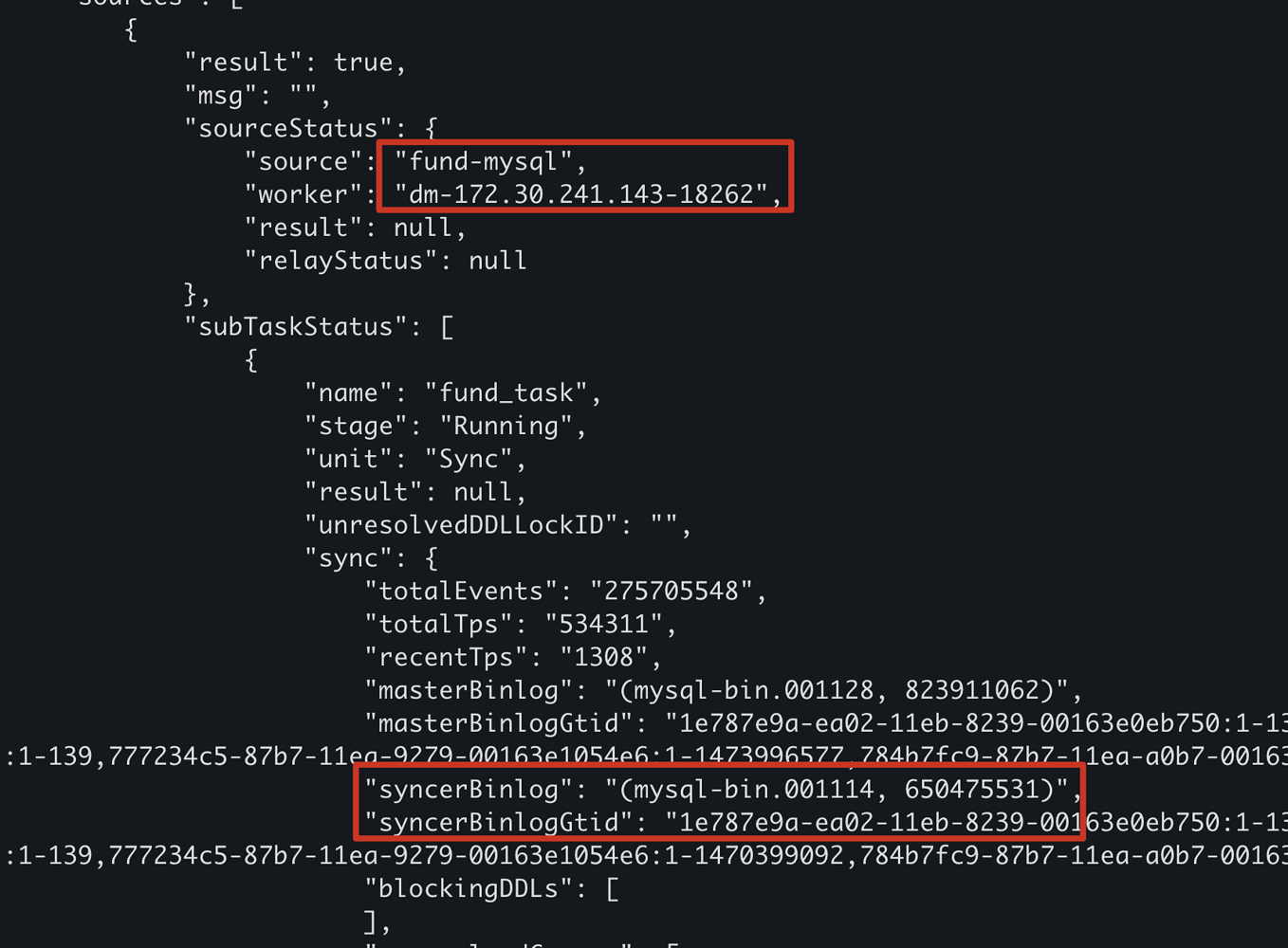
As you can see, the binlog has not continued to persist since 10-21, with the last binlog being mysql-bin.001048.
Here, the task status is normal and has already synchronized to mysql-bin.001114 (there was a primary key conflict downstream, replication stopped for a while, manually executed resume-task to fix it, this issue occurred multiple times, and I executed resume-task multiple times).
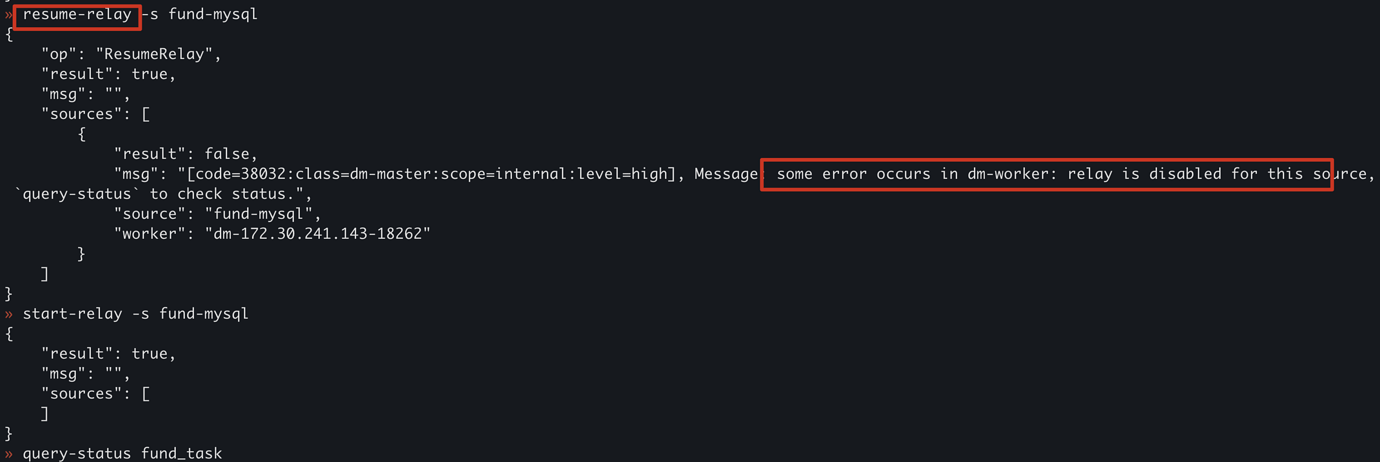
To add, when this issue occurs, you can see that the relayStatus is indeed null, meaning the relay-log is not actually started. At this point, if you execute resume-relay, it will prompt you that the relay-log has not been started yet, so you need to execute start-relay first;
However, at this time, if you execute
query-status, you will find that the task status starts to fail. You must
stop-task first and then
start-task to regenerate a task.
Could you please send us the logs using the clinic service? We need the logs to troubleshoot the issue.
I found the cause of the problem. After further investigation, I discovered that none of the data sources had the relay-log enabled. I remembered that during a previous operation, I mistakenly executed stop-relay & stop-task on all data sources. After that, I only executed start-task and did not execute start-relay, so the relay-log was not being pulled in the first place. 
Additionally, here are two SHELL commands to query abnormal relay data source names:
# 1. Query data sources without relay-log enabled
[tidb@prod-tiup-f01 task]$ tiup dmctl --master-addr 127.0.0.1:8261 query-status --more | jq -r '.sources[] | select(.sourceStatus.relayStatus == null) | .sourceStatus.source'
tiup is checking updates for component dmctl ...
Starting component `dmctl`: /home/tidb/.tiup/components/dmctl/v6.1.1/dmctl/dmctl --master-addr 127.0.0.1:8261 query-status --more
# 2. Query data sources that are in an error state
[tidb@prod-tiup-f01 task]$ tiup dmctl --master-addr 127.0.0.1:8261 query-status --more | jq -r '.sources[] | select(.sourceStatus.relayStatus.stage == "Paused") | {src: .sourceStatus.source, worker: .sourceStatus.worker }'
tiup is checking updates for component dmctl ...
Starting component `dmctl`: /home/tidb/.tiup/components/dmctl/v6.1.1/dmctl/dmctl --master-addr 127.0.0.1:8261 query-status --more
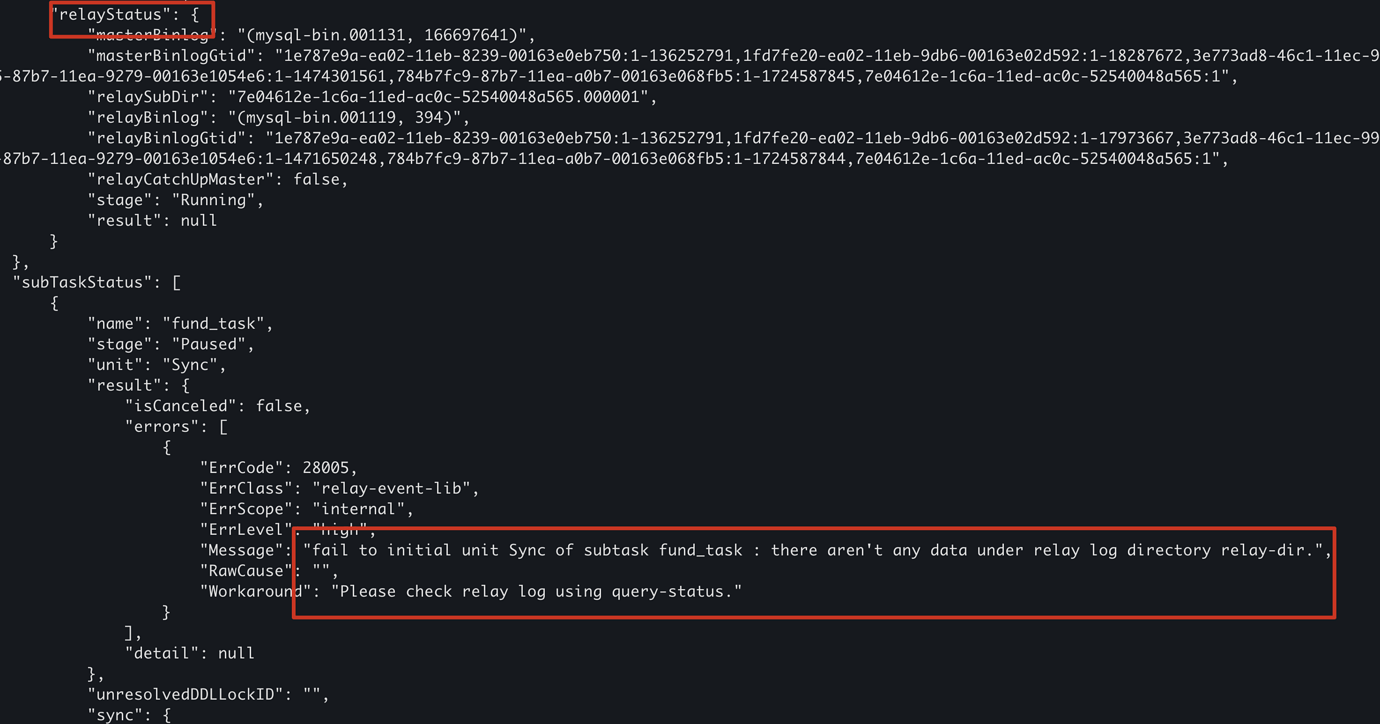
Additionally: If you, like me, have previously enabled relay-log and haven’t enabled it for a long time, directly using start-relay at this point is likely to result in an error:
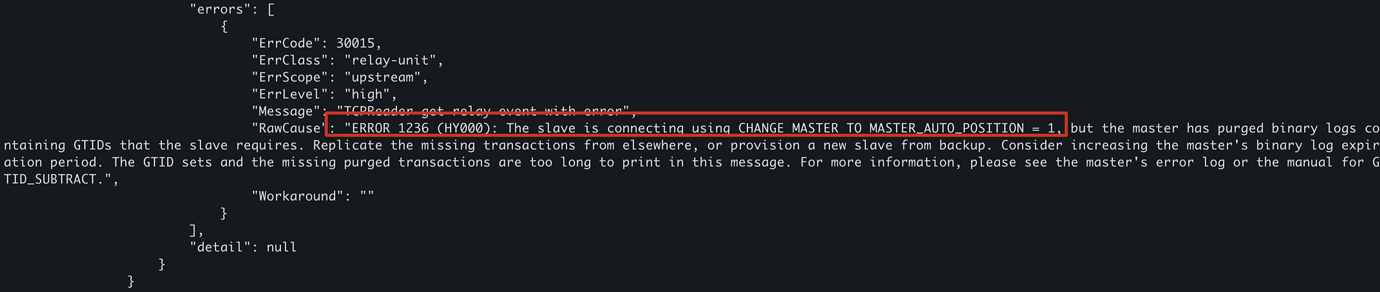
This is because when the dm-worker start-relay, it will request the binlog from MySQL from the last paused point. If the relay-log has been disconnected for a long time, the binlog is likely to have been cleaned up (actually, we don’t need these binlogs, since the task status is normal, these binlogs have already been applied by the task, just not persisted). At this point, you can use the command 2 I provided above to find the dm-worker corresponding to the data source, then go to the deploy directory of DM, delete the relay_log directory, and clean up the previously left metadata. Then stop-relay & start-relay to restart the relay.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.