Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 执行 --force 下线节点后,pd没有删除store信息
[TiDB Usage Environment] Production Environment
[TiDB Version] v4.0.14
[Reproduction Path] The machine node went down due to a power outage. After consulting the documentation, I attempted to repair the cluster by first scaling down and then scaling up. Since it was a three-node deployment, I first scaled up by adding one machine, changing the setup to four nodes. Then, I executed the command tiup dm scale-in <cluster-name> --force to forcibly scale down the problematic node.
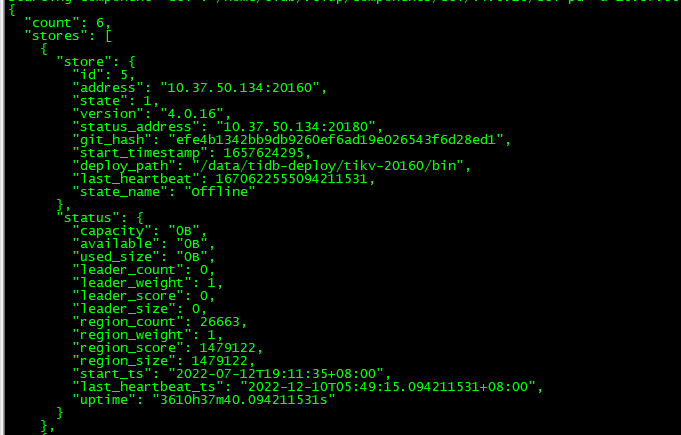
[Encountered Issue: Symptoms and Impact] After executing the operation, the network recovered, and the scaled-down node could be connected again. However, the store of that node still exists in PD, with used_size=0 and region_count having values that gradually decrease over time but at a slow pace. The tiup cluster display command does not show the status of that node, but it is visible in the dashboard as “scaling down.”
Currently, the data in the tidb-data directory of the scaled-down node has been cleared. I want to restore the cluster to its original state. Could the experts please take a look? Thank you.
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]