[TiDB Usage Environment] Production Environment
[TiDB Version] 7.1.2
[Reproduction Path]
A node’s disk had an issue. After recovering the disk and restarting the node, continuous errors occurred. After scaling in with --force and then scaling out, the node did not synchronize replica data from other nodes.
[Encountered Issue: Symptoms and Impact]
After scaling out, the data did not balance, meaning there are now only 2 replicas. It seems the operator is not functioning correctly.
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
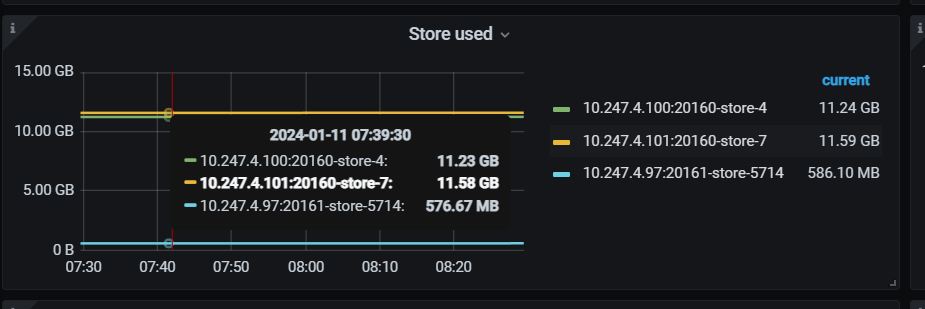
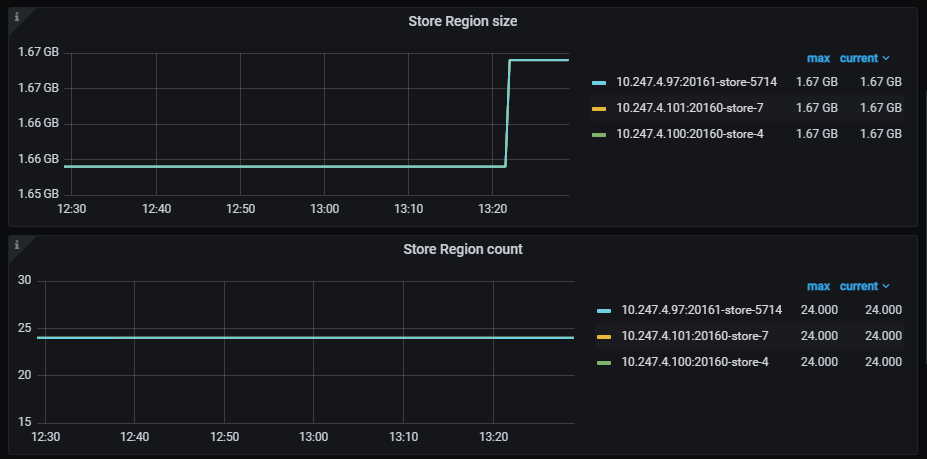
It has been almost 12 hours, and there is basically no balanced data. Mainly, one of the three replicas is missing, and it seems that it cannot automatically replenish the missing replica.
The disk on this 4.97 server is somewhat smaller. This is how I understand it: there are currently only 3 KV nodes, with 3 replicas distributed across different KVs. So even if there are some configuration differences, it shouldn’t affect the number of replicas, and the data should be the same, right?
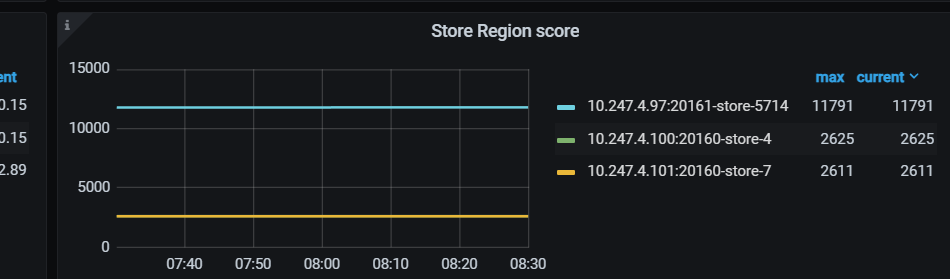
Your understanding is correct; the regions are balanced now. However, the leaders are definitely influenced by the configuration. Generally, nodes with higher configurations will have more leaders and handle more read and write tasks.
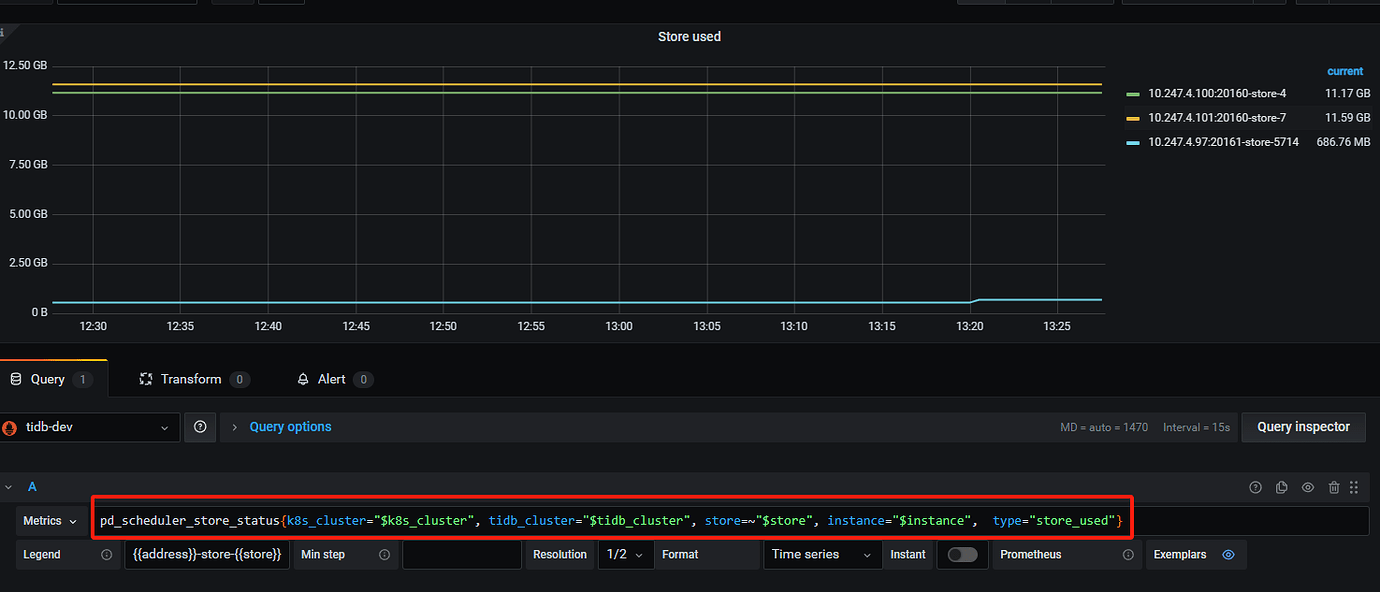
Yes, the number of replicas can be determined from the number of regions. However, why is there such a big difference in storage usage even though the number of replicas is the same?
So, the number of regions cannot confirm whether the replica data has been fully synchronized, right? Then, can it confirm that the node is not missing any data replicas? Could you please tell me how to ensure that the three nodes have the same data replicas?
The three nodes are not identical data replicas, right?
As I understand it, for example, data is divided into three parts (normally close to evenly), each part of the data has 1 primary replica and 2 secondary replicas, and the data is exactly the same.
Primary replica L1, secondary replicas F11, F12
Primary replica L2, secondary replicas F21, F22
Primary replica L3, secondary replicas F31, F32
The general data distribution is as follows:
Node 1: L1 F21 F31
Node 2: L2 F11 F32
Node 3: L3 F12 F22
With this distribution, if any node goes down, the primary replica can be quickly restored from the secondary replicas on the other two nodes, ensuring data accuracy. Only the primary replicas, i.e., L1, L2, and L3, provide external services.
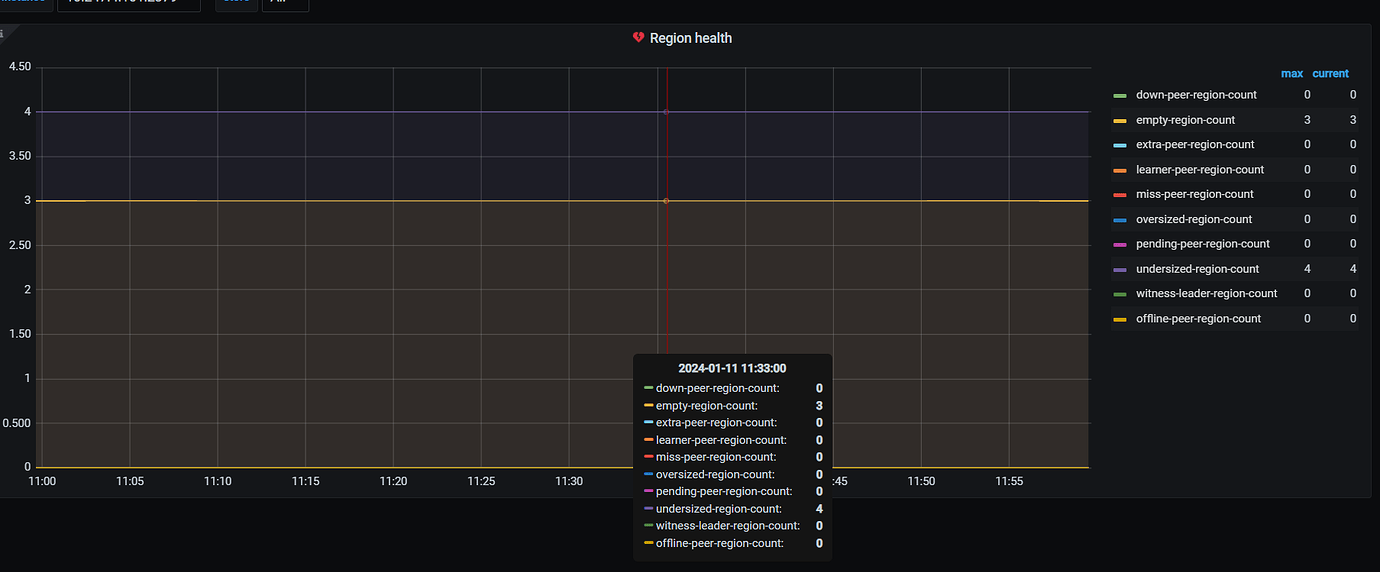
Check the region health in the PD panel.
From the provided monitoring, you have a total of 24 leaders, with 24 regions per node, which is normal. However, there is a significant difference in space usage.