Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: br 迁移 tidb后,写入数据一直报for key ‘PRIMARY’
[Overview] Scenario + Problem Overview
Order Data
Migrating a database from a v5.4.0 cluster to a new v5.4.1 cluster using BR
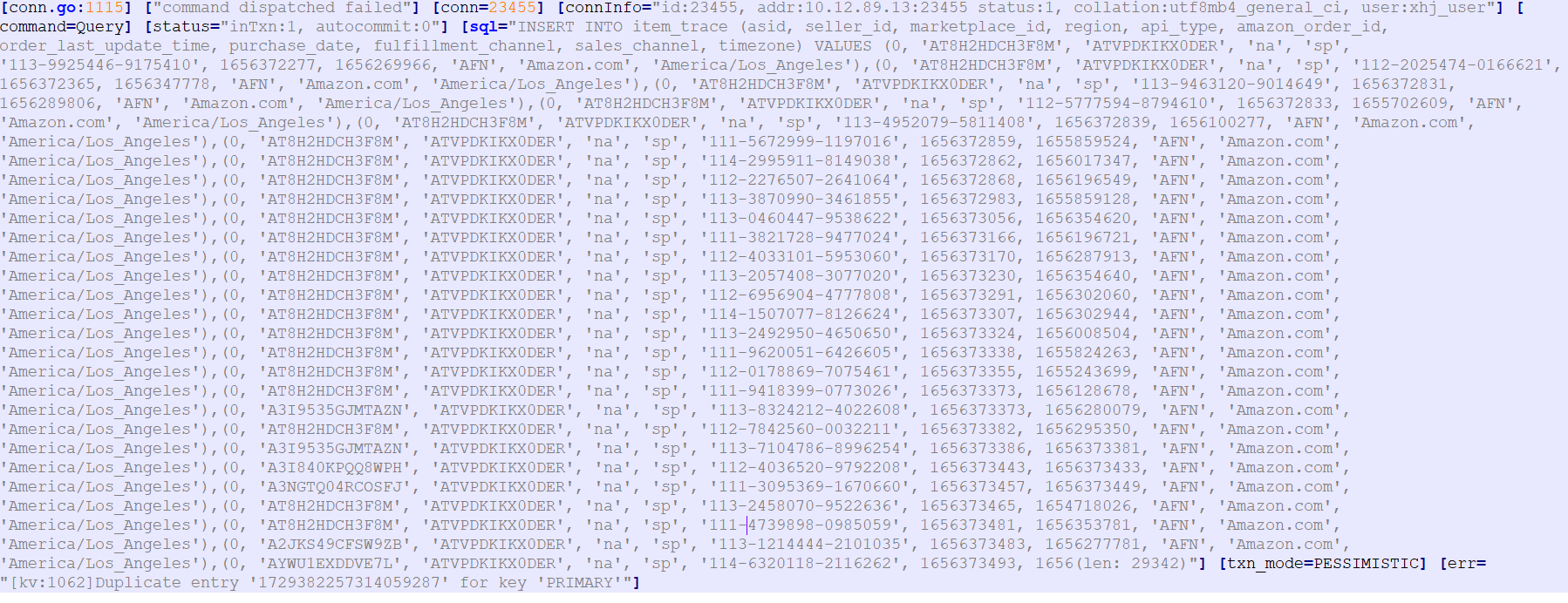
Full and incremental migration completed, business traffic switched, data writes reporting large volumes of “for key ‘PRIMARY’”
TiDB backend continuously logs “for key ‘PRIMARY’”
[tikv:1205]Lock wait timeout exceeded; try restarting transaction"]
Logs:
Monitoring:

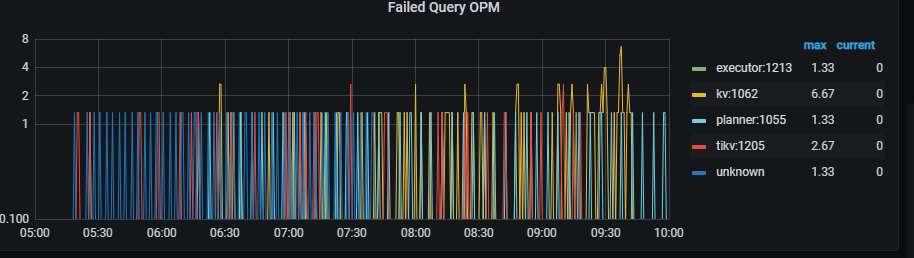
Table Structure:
CREATE TABLE item_trace (
id bigint(20) NOT NULL /*T![auto_rand] AUTO_RANDOM(4) */,
api_type varchar(20) NOT NULL DEFAULT ‘sp’,
asid bigint(20) unsigned NOT NULL DEFAULT ‘0’,
seller_id varchar(100) NOT NULL DEFAULT ‘’,
marketplace_id varchar(50) NOT NULL DEFAULT ‘’,
region char(2) NOT NULL DEFAULT ‘’ COMMENT ‘’,
amazon_order_id varchar(50) NOT NULL DEFAULT ‘’ COMMENT ‘’,
order_last_update_time int(10) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
purchase_date int(10) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
fulfillment_channel varchar(100) NOT NULL DEFAULT ‘’,
sales_channel varchar(100) NOT NULL DEFAULT ‘’,
next_sync_time int(10) NOT NULL DEFAULT ‘0’,
next_token varchar(2500) NOT NULL DEFAULT ‘’,
gmt_modified timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘Data update time’,
gmt_create timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘Data creation time’,
timezone varchar(20) NOT NULL COMMENT ‘Time zone’,
PRIMARY KEY (id) /*T![clustered_index] CLUSTERED */,
UNIQUE KEY uk-order-id (seller_id,marketplace_id,amazon_order_id),
KEY idx_update_time (id,order_last_update_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![auto_rand_base] AUTO_RANDOM_BASE=403971164 */
Problem Points:
After business switch, traffic has been routed to the new cluster.
During batch writes, none of the services’ insert statements explicitly specify the primary key id, but all inserts report primary key id conflicts.
Is it possible that migrating data from v5.4.0 to v5.4.1 causes unspecified primary key id errors?
[Phenomenon] Business and Database Phenomenon
At the time, the business write traffic was very high.
Subsequently switching back to the original v5.4.0 did not result in “for key ‘PRIMARY’” errors.
[Business Impact]
Data write failures leading to a large number of transaction timeouts.
Increased data latency.
[TiDB Version]
v5.4.1