Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 重启tikv一个节点后,tikv服务一直报警call CheckLeader failed,日志一直刷
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] 6.1.2
[Reproduction Path] Operations performed that led to the issue: Restarted TiKV node
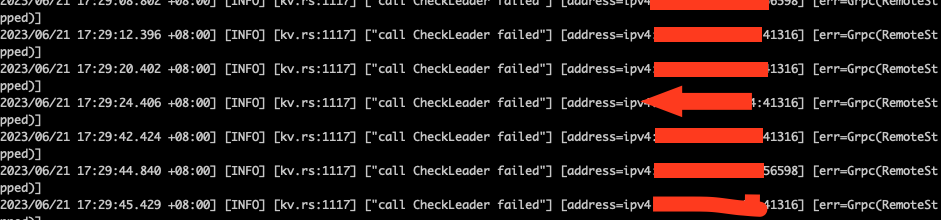
[Encountered Issue: Problem Phenomenon and Impact] TiKV service continuously alarms: call CheckLeader failed
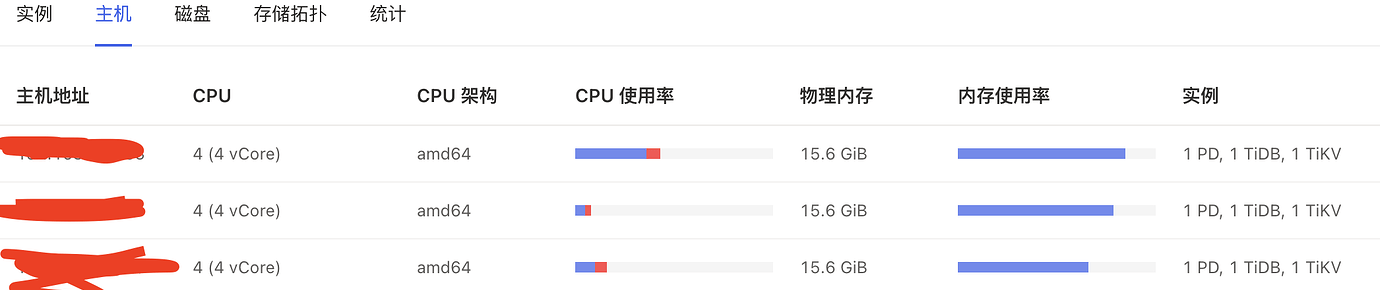
[Resource Configuration] Navigate to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
Try to maintain 3 nodes.
It looks like your machines are not enough for mixed deployment.
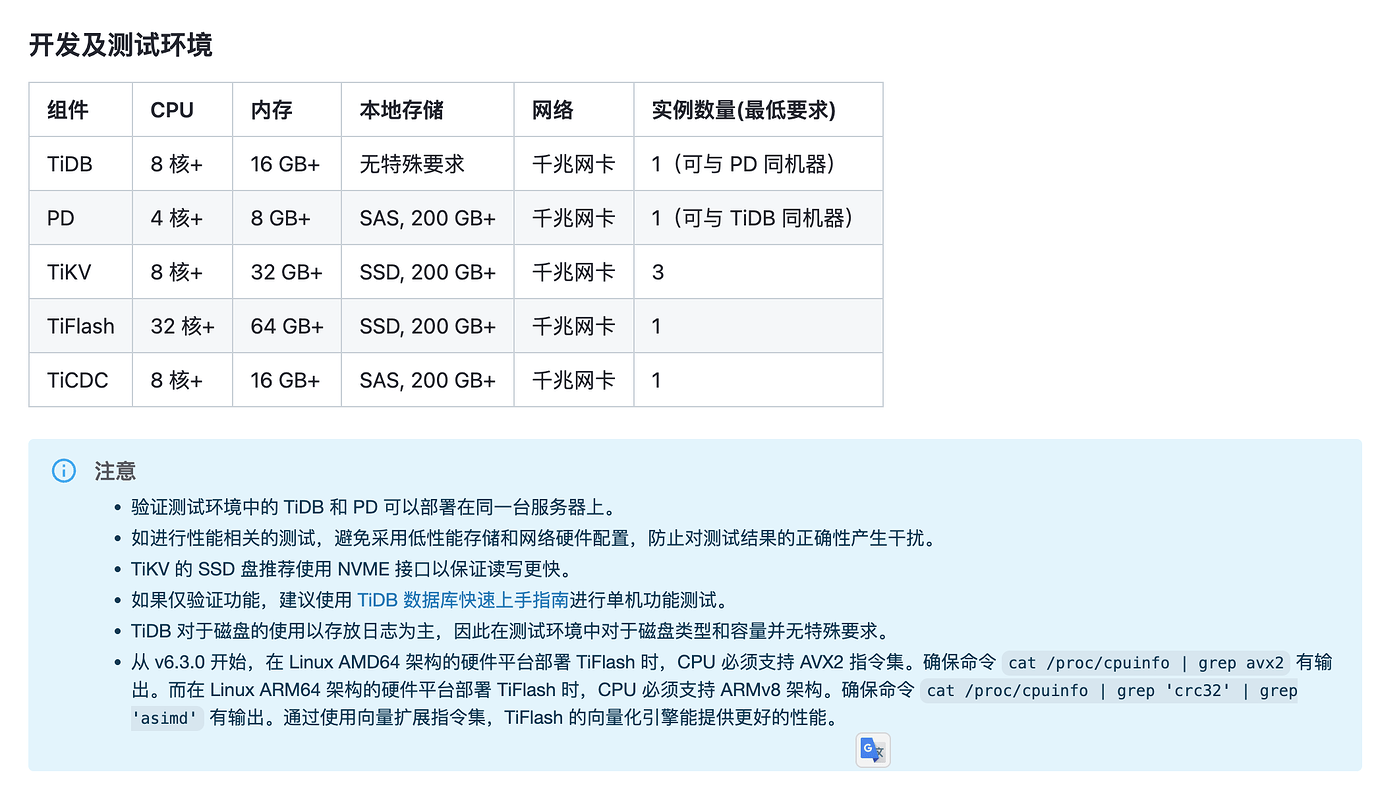
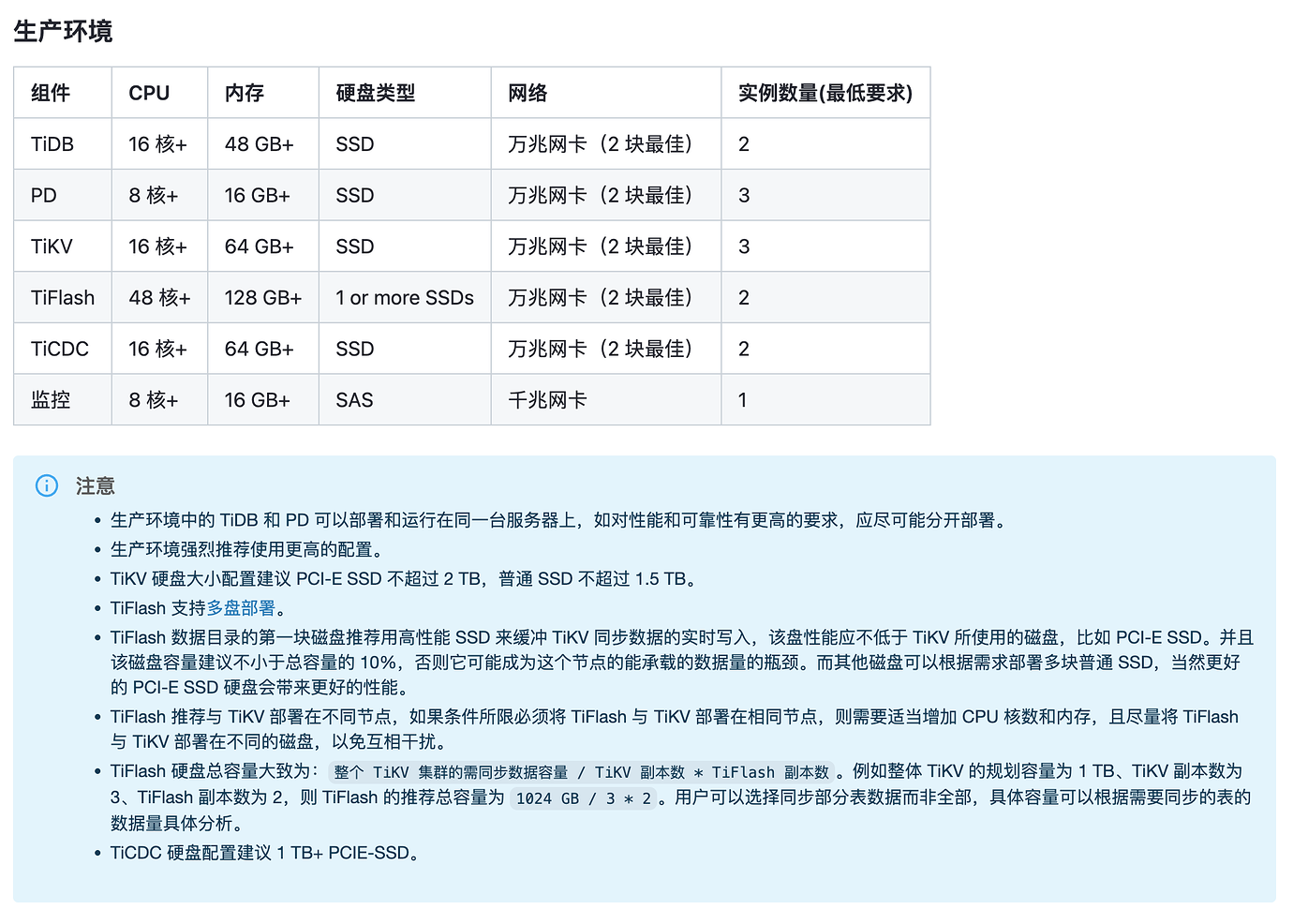
Please refer to the official deployment as much as possible:
This situation may be caused by data inconsistency between the restarted TiKV node and other nodes. You can try the following steps to troubleshoot:
- First, you can check the status of the node using the
pd-ctl tool with the following command:
pd-ctl -u http://{pd_ip}:{pd_port} store
Where {pd_ip} and {pd_port} are the IP address and port number of the PD. If the node status is Tombstone, it means the node has been deleted and needs to be re-added.
- If the node status is
Up, you can try using the tikv-ctl tool to check if the data on the node is consistent with other nodes with the following command:
tikv-ctl --host {tikv_ip}:{tikv_port} --db {db_path} --check-compact
Where {tikv_ip} and {tikv_port} are the IP address and port number of the TiKV node, and {db_path} is the data storage path of the TiKV node. If the data on the node is inconsistent with other nodes, you can try using the tikv-ctl tool to repair the data with the following command:
tikv-ctl --host {tikv_ip}:{tikv_port} --db {db_path} --compact {start_key} {end_key}
Where {start_key} and {end_key} are the start and end key values of the data range that needs to be repaired.
- If the above steps do not resolve the issue, you can try restarting the entire TiDB cluster.
The configuration is a bit low, and the CPU performance is not sufficient.
Add another machine with the same configuration, expand 1 PD and 1 TiDB on this machine, and then scale down the original 3 PD and 3 TiDB that were deployed together with TiKV. If the machine performance is insufficient, it is best to deploy TiKV separately, especially not to place TiKV and PD together.