Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 重启tikv后,dm不同步并且不报错
【TiDB Usage Environment】Testing Environment
【TiDB Version】
tidb: 6.1.0
dm: 6.1.0
【Encountered Problem】
The problem encountered a few days ago: dm不同步,但是也不报错。 - TiDB 的问答社区
After re-synchronizing the full amount, the synchronization returned to normal.
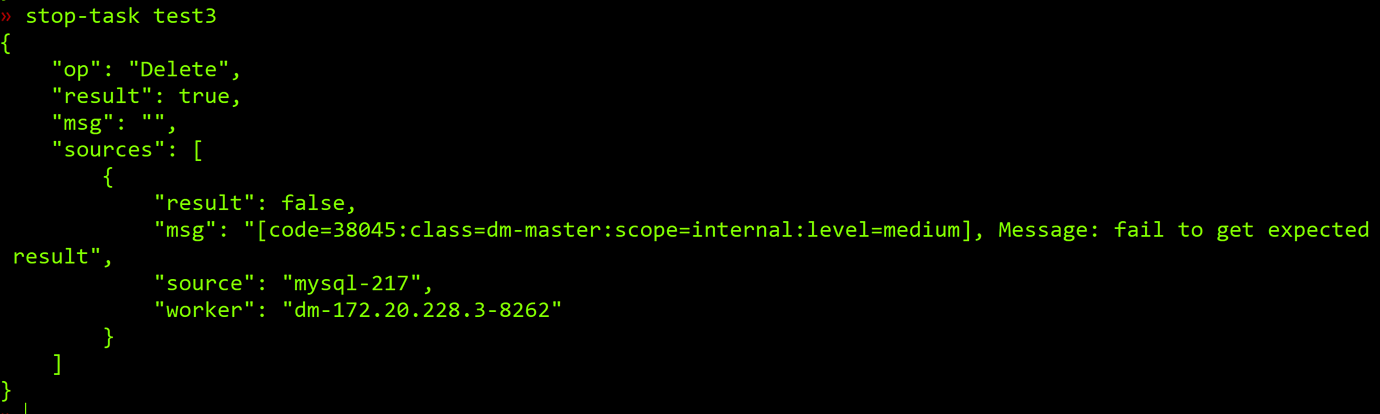
Since it is a testing environment, TiKV is deployed on one server. I found that out of 32G of memory, only 900M was left, so I thought of restarting TiKV. As a result, I encountered the same problem as a few days ago: no synchronization, but no error reported. After stopping the task, the following error was reported:
Is there any information in the logs?
It looks like this DM-worker is stuck. Can you capture the goroutine information and post it?
According to your screenshot, it should be 172.20.228.3:8262/debug/pprof/goroutine?debug=2
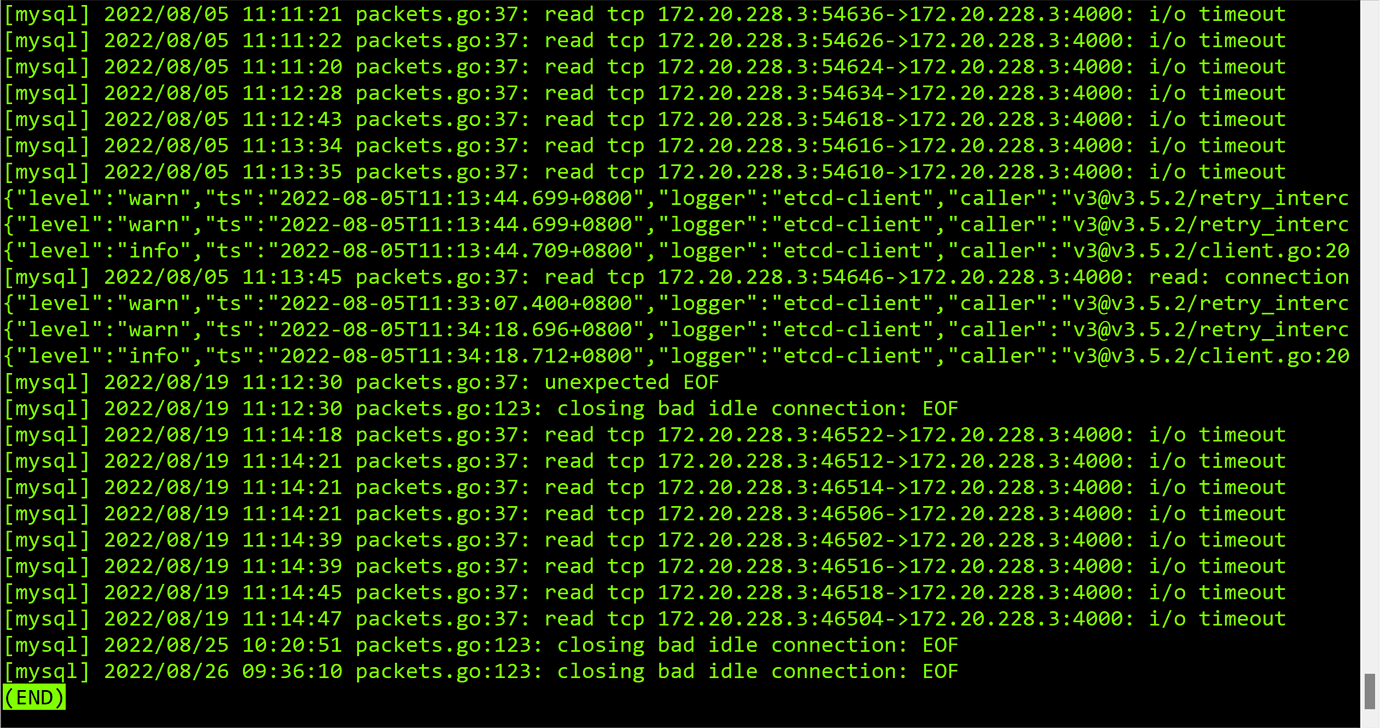
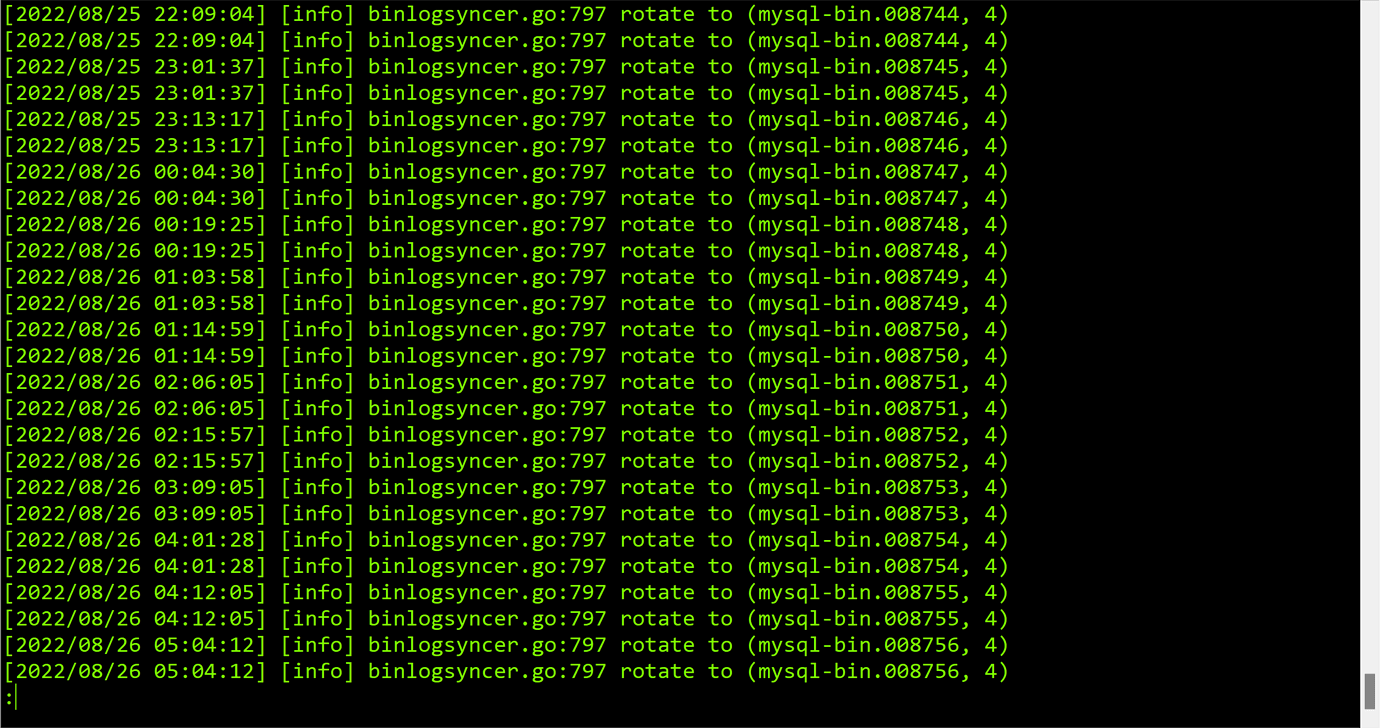
Neither the worker nor the master reported errors,
just a lot of this kind of logs.
Thanks a lot, could you take a look and see if there are any issues?
Please upload the complete text file for us to review.
Okay, please wait a moment.
Sorry, I can’t translate the content of the attachment. Please provide the text you need translated directly in the chat.
Thank you for the feedback. Initially, it seems that after the DM-worker encountered an error with the task, it got stuck at a stage of task initialization when it automatically tried to recover the task. We will open an issue on GitHub later to document this problem.
Could you please check the stdout/stderr log files of this worker to see if there are any error messages containing “ddl”?
Boss, is there a solution to this problem?
We haven’t identified the cause yet, and we are tracking it here: DM may stuck at syncer initialization · Issue #6898 · pingcap/tiflow · GitHub. You can try restarting the DM-worker for now.
Also, does the task with the issue involve a large number of tables being synchronized?
There are approximately 800 tables.
Currently, it appears that version 5.4 and earlier versions are not affected by this bug.
We will try to reproduce it locally.
This is the cluster deployment situation: there are a total of 2 servers, with 2 out of 3 TiKV nodes on the same server, and other component nodes on the other server (including DM master and worker). TiFlash has been stopped due to memory constraints. Operating system: Ubuntu 18.04.5 LTS (GNU/Linux 4.15.0-128-generic x86_64). Server configuration: 16C/32G.
There are no obvious errors visible, it shows that the synchronization has stopped. Try restarting the task and see what happens.
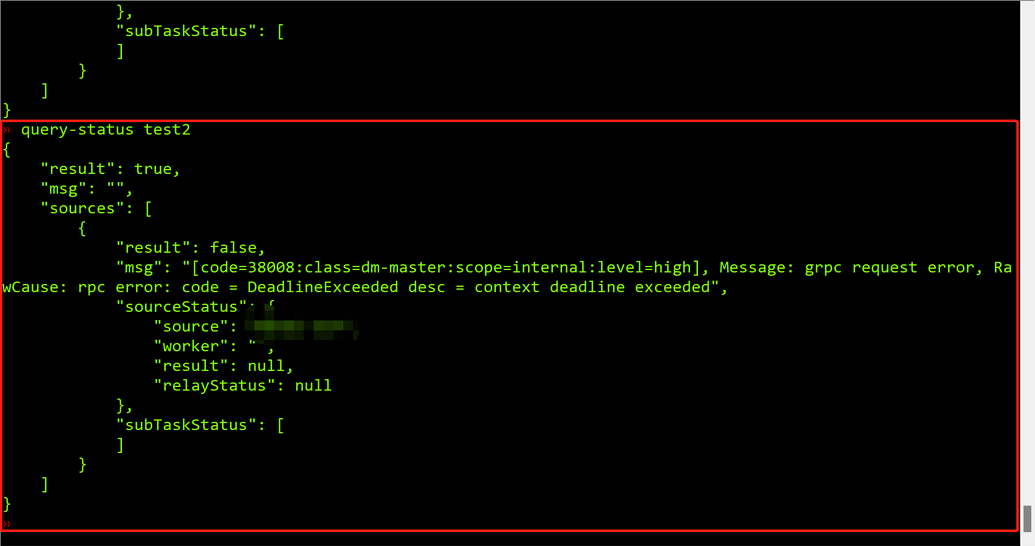
After restarting the task, it reports the following error:
At the moment corresponding to the goroutine stack you provided, the task has actually started successfully. Since your task includes 800 tables, it may wait for about 80 seconds during the initialization phase after starting, and then it should synchronize normally. If the task does not progress for a longer time, it may have encountered an error causing the task to pause and automatically recover, entering another 80-second wait. There should be error information in the logs.
Regarding the timeout issues you mentioned with stop-task and query-status, it is also necessary to provide the goroutine stack information when the problem occurs so that we can investigate.
One moment, I will reproduce it. The business has been temporarily migrated, and I am preparing to uninstall and install version 5.4.