Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiDB oom之后重启虚拟机 启动集群出错
[Test Environment] Testing environment
[TiDB Version]
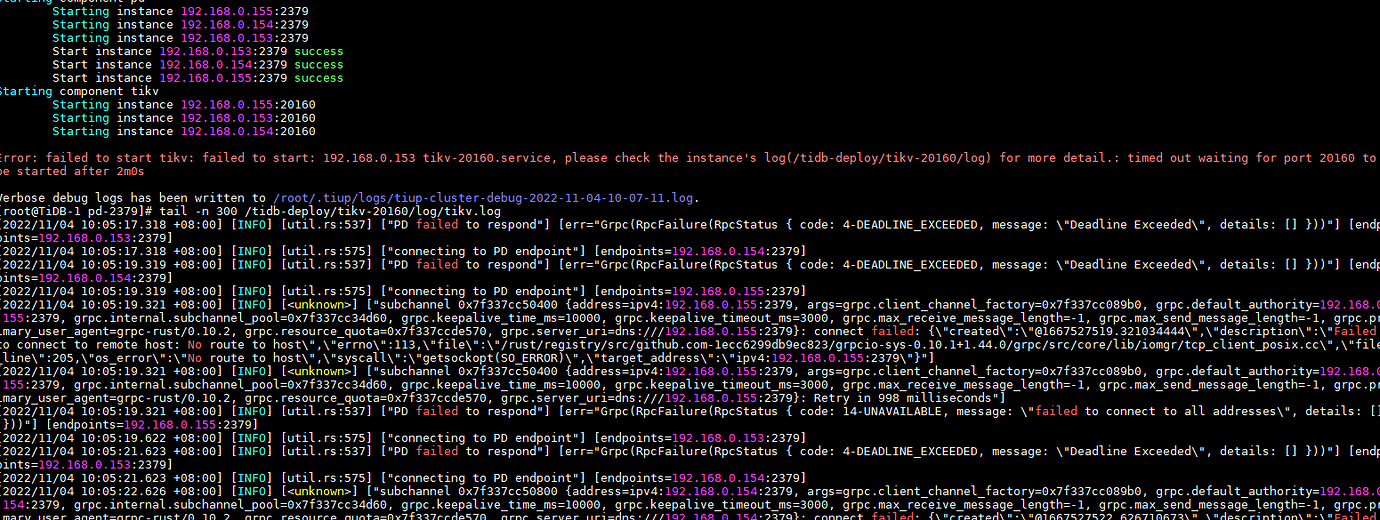
[Encountered Problem] After TiDB OOM, the machine became sluggish and the server was restarted. Upon rebooting and starting the cluster, the following issue appeared as shown in the image below:
[Reproduction Path]
[Problem Phenomenon and Impact]
I think the main reason is that the execution plan is different. You can use explain analyze to see the execution plan and the time spent on each operator.
How did you restart it? The logs describe that PD crashed~
If restarting still can’t restore the PD state, it’s likely that data loss occurred, causing the service to malfunction.
You can only use PD’s unsafe recovery method… (which will probably result in data loss)
Perform the related recovery operations.
Can’t imagine restarting just because of OOM (Out of Memory).
Shouldn’t you avoid restarting all the servers at once? Can’t you manually start each instance now?
Yes, is there any way to fix it?
What is your startup sequence? Try starting PD first, then the TiDB server, and finally start TiKV.
The current startup sequence for a single node is that pd, tikv, and tidb have all successfully started; however, it is inaccessible.
Directly started from the command line, saw a fatal message in TiKV
Didn’t see it in other PD and TiDB
It is recommended to perform data recovery.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.