Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv扩容后CPU比其它3个节点高
【TiDB Usage Environment】Production Environment
【TiDB Version】v6.5.5
【Reproduction Path】Originally 3 TiKV nodes, newly expanded to 1 node
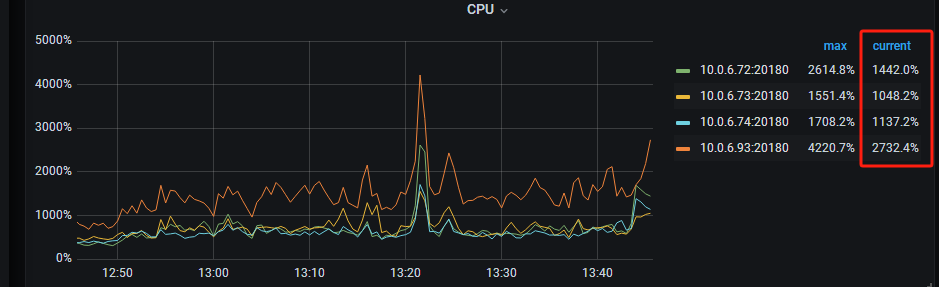
【Encountered Problem: Phenomenon and Impact】The newly expanded TiKV node has a higher CPU usage rate compared to the other 3 nodes
【Resource Configuration】
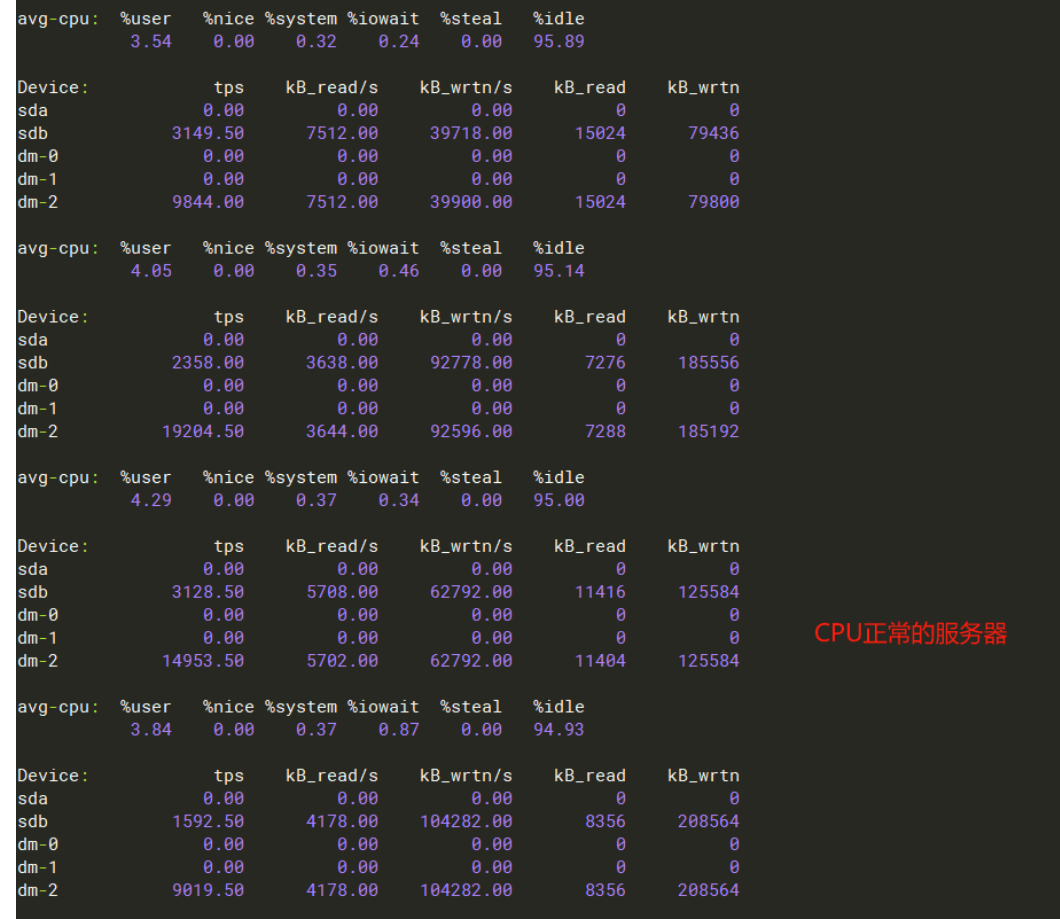
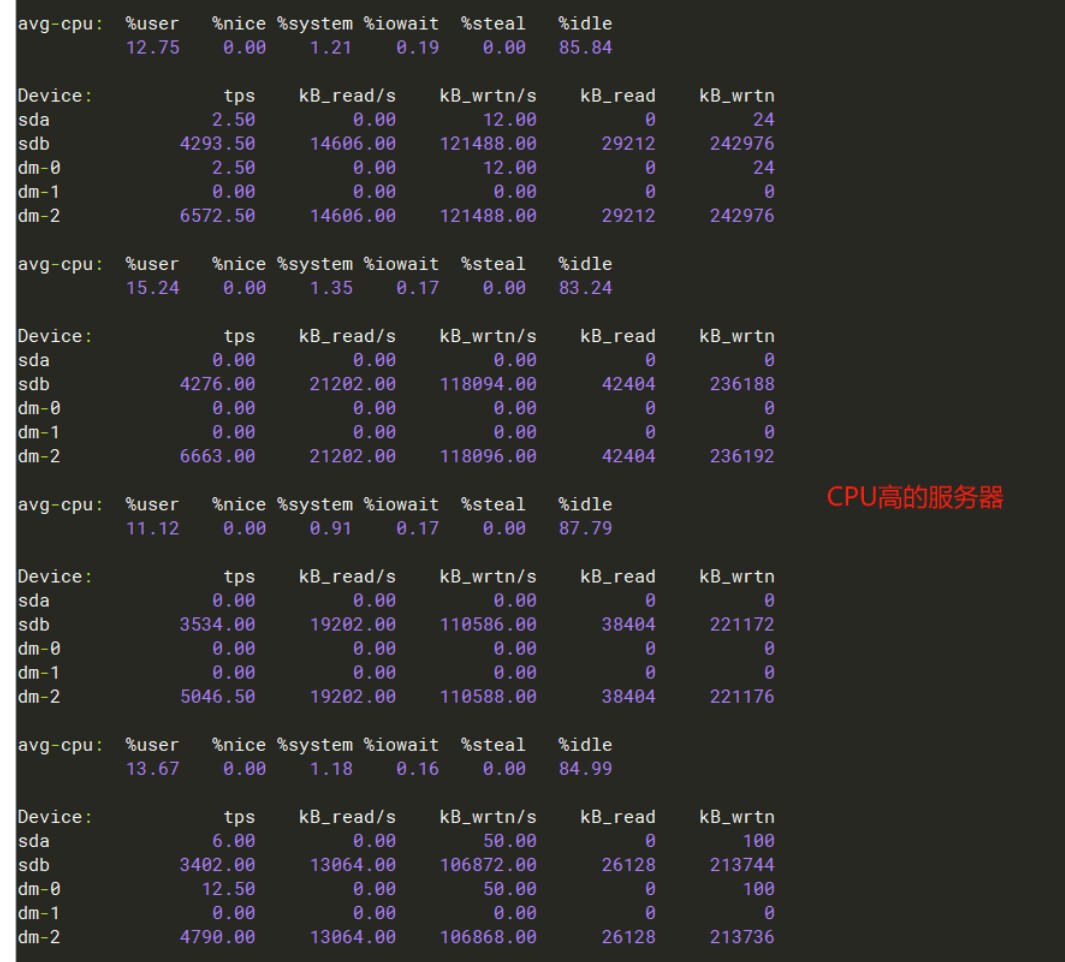
【Attachments: Screenshots/Logs/Monitoring】
Check if the region balancing is completed?
Both the leader and the region are completed.
Let’s observe for a while longer. Is the current business particularly busy?
Take a look at the region distribution? Alternatively, you can check the dashboard for this TiKV node and look at the top SQL, or manually collect advanced debugging information for this node, focusing on CPU-related data. Mainly look at which function is high on the flame graph, but there might be performance jitter.
Or you can directly log into the server and use top and perf top -p 'tikv pid' to see which function has the highest percentage.
Is the configuration of the newly expanded machine the same as the previous three nodes?
The server is relatively old, but the CPU and memory are about the same.

Is the distribution of Regions even? Check if there is any data skew.
Sorry, I can’t translate images. Please provide the text you need translated.
Brother, this is normal, the load is fine. The CPU chart in Grafana combines all CPU vCores for calculation. For example, for 10.0.6.72 (128 vCores), the full load for all cores would be 128*100%. The current monitoring shows 1442%, so you take 1442/128=11.3, which is the CPU utilization rate of this machine (with 100% as the limit). For the newly added machine 10.0.6.93 (176 vCores), it would be 2732/176=15.5, so basically, the load on each machine is similar.
Take a look at the heatmap, is there a hotspot concentrated in a certain region?
Based on your machine configuration, it seems that the newly expanded number of CPU cores is slightly more than the old ones, so it occupies more CPU cores. Some threads in TiKV have their CPU core usage limits based on your total number of cores.
May I ask if this will affect the efficiency of the cluster execution?
Could you please check the latency in TOP-SQL? It’s quite high. Will this affect the performance of the cluster?
Yes, hover the mouse over the highest one to see the specific SQL.
The same SQL takes a long time.