Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 5.1.4升级到6.1.7之后 性能抖动比较严重
[TiDB Usage Environment] Production Environment / Testing / Poc
[TiDB Version]
[Reproduction Path] Frequent jitter after upgrading TiDB from 5.1.4 to 6.1.7
[Encountered Problem: Problem Phenomenon and Impact]
Frequent jitter after upgrading TiDB from 5.1.4 to 6.1.7
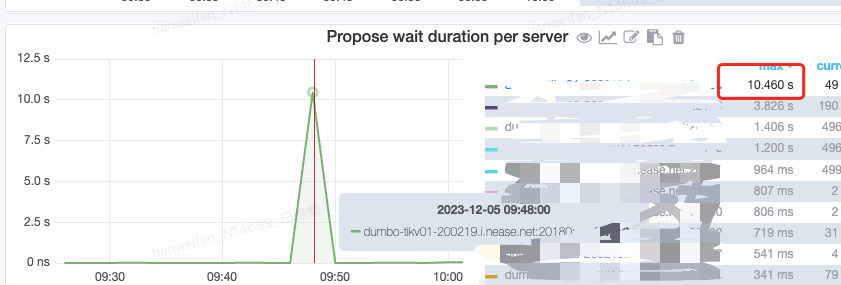
Checking the corresponding monitoring found that the propose wait duration per server on a certain node is very severe
Checking the corresponding TiKV logs found that the time consumption is mainly concentrated on write_raft
Since TiDB 5.4, it supports using Raft Engine as the TiKV log storage engine. After our upgrade, we are currently using raft-engine by default. It is uncertain whether there is any adjustment needed in this area.
Note: From the IO-related situation of the node, the machine is not the bottleneck. IO, CPU, and other resources are relatively idle.
What was the propose wait duration before the upgrade?
Normally, there shouldn’t be any parameters that need adjusting. It should still be an issue with your environment.
wf Regarding the issue of cluster read/write slowdown, you can refer to the following articles for troubleshooting ideas. For complex problems, you may need to confirm each link one by one. Let’s first try to find the cause of the problem and then address it specifically.
The propose wait is relatively high, indicating that there is a performance issue in the process of converting data into raft log streams and writing them into the raft db. Focus on checking if there are any significant anomalies in the raft db of the problematic node.
Other nodes are normal, but only one node is abnormal. It might be an issue with the RocksDB on that node.
If the business is urgent and the impact is significant, you might consider scaling down this node first and, if possible, scaling up other nodes. See if this resolves the issue; the root cause can be analyzed and confirmed later.
I feel like 6 is a bit slow. Upgrade to 7.5 for a pleasant surprise.
No, other nodes also experience jitter, not just one node. It’s just that when troubleshooting, I happened to take a screenshot of a problematic node.
There are quite a few problematic nodes, and different nodes might have this issue at different times.
Before the upgrade, the propose wait duration had minor fluctuations, but it wasn’t as significant as the fluctuations after the upgrade.
Well, the current monitoring and logs all point to the raft log writing process. Let’s focus on analyzing the raft writing situation first.
Yes, because the raft engine is enabled by default after the upgrade, it will not write to raftdb anymore. We still suspect that the raft engine’s writing is causing the jitter. Let’s try shutting it down and restarting to see.
Hmm, try disabling the Raft engine and reverting to the default method to see if there’s any improvement.
Check the version of analyze.
It seems that there is a collection operation during writing…
Check if other metrics on this panel are normal.
Upgraded, the value is 1.
The fluctuation of this metric is quite severe.
Try switching to 2 and observe more.
commit log, append log, network latency, and jitter— which of these experience jitter?
Adjusted, but still jittering. From the log analysis, it seems that the bottleneck is not here.
I just noticed that the jitter is quite severe when writing Raft, but the delay for other append log operations is still acceptable.