Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tikv_storage_async_request指标统计结果分析
[TiDB Version] v6.0.0
[Cluster Parameters]
# Disable cluster hotspot scheduling and region splitting
tiup ctl:v6.0.0 pd config set leader-schedule-limit 0
tiup ctl:v6.0.0 pd config set region-schedule-limit 0
tiup ctl:v6.0.0 pd config set hot-region-schedule-limit 0
tiup ctl:v6.0.0 pd config set hot-region-cache-hits-threshold 60
tiup ctl:v6.0.0 pd config set replica-schedule-limit 0
tiup ctl:v6.0.0 pd config set merge-schedule-limit 0
set config tikv split.qps-threshold=1000000;
set config tikv split.byte-threshold=10000000;
[Encountered Problem]
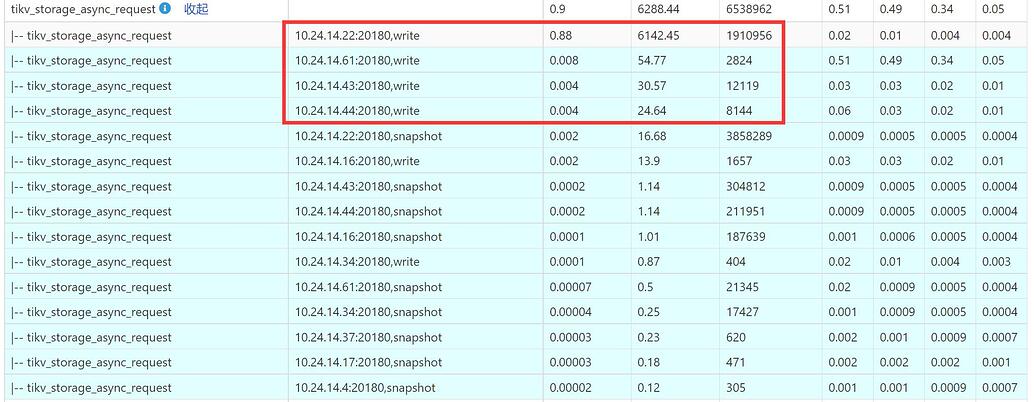
When running a high-conflict experiment, performing select for update on a single row of data, all queries fall on the same region. Observing the statistics on the TiDB dashboard, it can be seen that the number of tikv_storage_async_request requests on the node where the region leader is located (10.24.14.22) is very high.
My question is why do other nodes also have write and snapshot requests?