【TiDB Usage Environment】POC
【TiDB Version】V6.1
【Encountered Problem】
【Reproduction Path】What operations were performed to encounter the problem
【Problem Phenomenon and Impact】
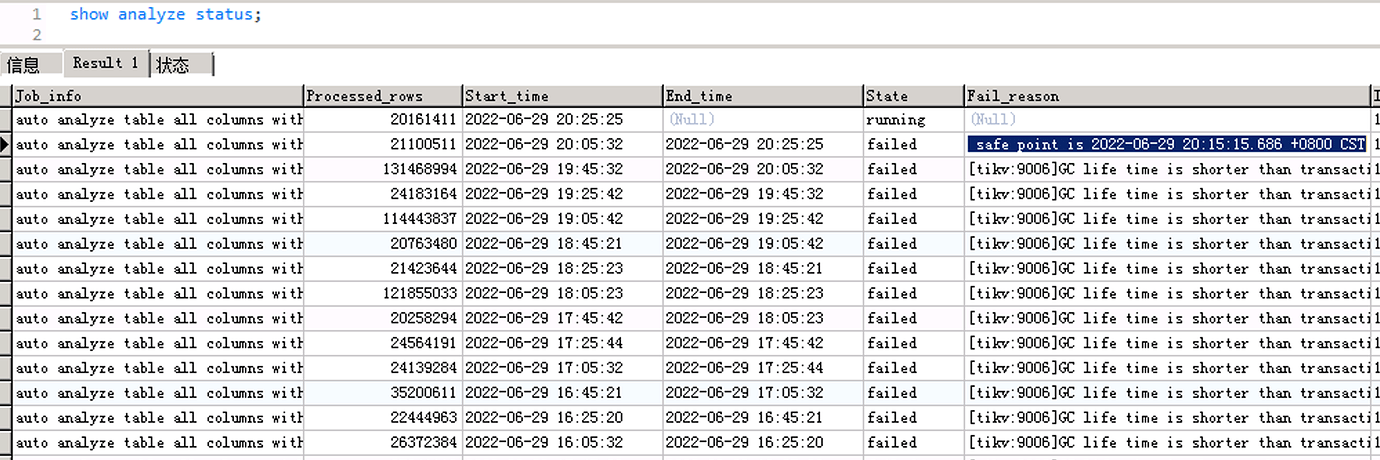
[tikv:9006]GC life time is shorter than transaction duration, transaction starts at 2022-06-29 20:05:32.887 +0800 CST, GC safe point is 2022-06-29 20:15:15.686 +0800 CST
Isn’t this design somewhat unreasonable?
According to the information, version 6.1 should have resolved the GC issue during auto analyze. Previous versions did not consider the runtime of auto analyze during GC. In version 6.1, to prevent auto analyze from blocking GC for a long time, the tidb_max_auto_analyze_time variable was introduced to control the maximum analyze duration. You might need to adjust the GC safepoint time to see if it helps.
I will first adjust the tidb_gc_life_time parameter and observe.
MySQL [(none)]>
MySQL [(none)]> show variables like '%tidb_max_auto_analyze_time%' ;
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| tidb_max_auto_analyze_time | 43200 |
+----------------------------+-------+
1 row in set (0.00 sec)
MySQL [(none)]> show variables like '%tidb_gc_life_time%' ;
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| tidb_gc_life_time | 10m0s |
+-------------------+-------+
1 row in set (0.00 sec)
MySQL [(none)]> set global tidb_gc_life_time='20m';
Query OK, 0 rows affected (0.04 sec)
After several adjustments, I finally saw a few successful attempts.
MySQL [(none)]> set global tidb_gc_life_time='20m';
Query OK, 0 rows affected (0.04 sec)
MySQL [(none)]> set global tidb_gc_life_time='30m';
Query OK, 0 rows affected (0.01 sec)
MySQL [(none)]> set global tidb_gc_life_time='60m';
Query OK, 0 rows affected (0.02 sec)
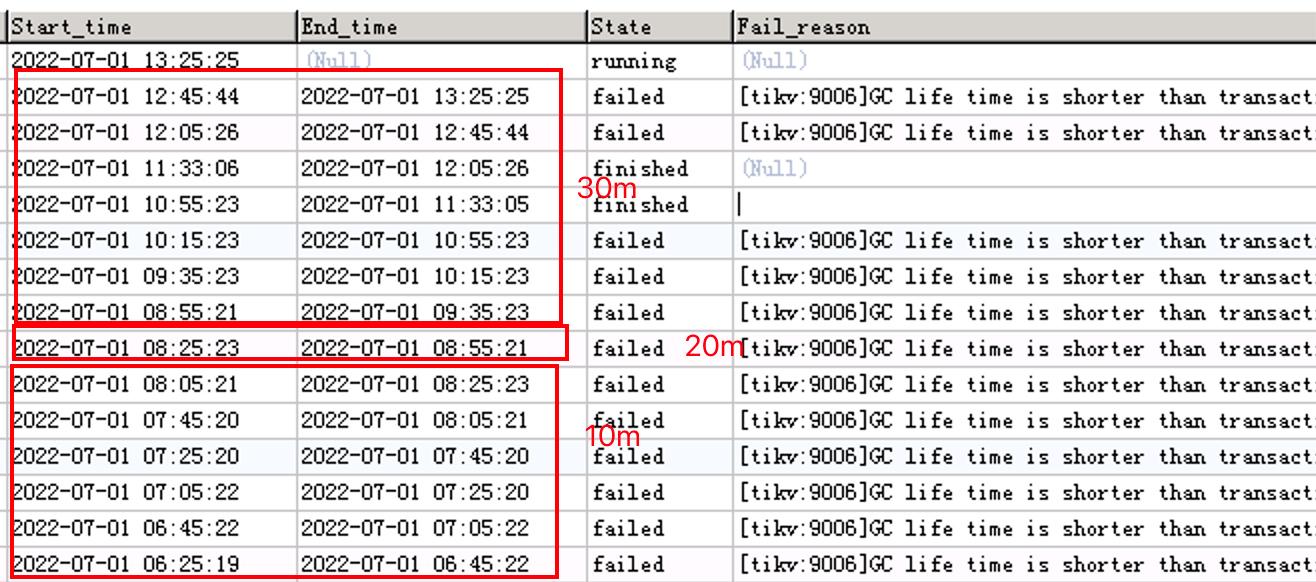
But there’s a problem. When the default tidb_gc_life_time='10m', it takes 20 minutes to report an error.
When set to 20m, it takes 30 minutes to report an error.
When set to 30m, it takes 40 minutes to report an error.
How should this be understood?
Setting it to a few hours in production shouldn’t be an issue, right? For routine maintenance, what is the generally recommended setting? We currently have it set to the default of 10 minutes.
Having too many historical versions can affect read performance, but it ultimately depends on the actual situation. The default of 10 minutes is a bit short.
Check the tidb.log for information other than the GC life time error. The auto analyze is triggered by a certain TiDB server, and the log contains the phrase “auto analyze trigger”.
Manually collected once, took less than 10 minutes to complete. The large table currently has no data changes and hasn’t triggered automatic collection. TiDB experts recommend manually collecting for large tables.
The concurrency for automatic collection is 1. Manual collection can be controlled by several parameters: tidb_build_stats_concurrency and tidb_distsql_scan_concurrency.
The reason for this issue is that we set the default GC time to not be too long (20 minutes), otherwise, too many data versions might affect performance. However, sometimes there are some long-running background tasks, such as analyze in this case, which might exceed 20 minutes when the cluster size is slightly larger. Previously, the analyze task worked on a snapshot of a version, but GC deleted the snapshot that exceeded 20 minutes, causing an error.
This issue is expected to be fixed in version 6.2.
In 6.2, analyze will use the max int64 TSO instead of a snapshot TSO. This will reduce the accuracy of the analyze, but it is acceptable for the analyze scenario.
In older versions, a workaround is to extend the GC time or avoid using auto analyze and instead perform analyze manually.
Master, I noticed that some issues and design docs seem to describe that in version 6.0, internal transactions like auto analyze have been considered in the management of GC, which is why the tidb_gc_max_wait_time variable was introduced later. Is that correct?