Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 批量插入数据问题
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version]
[Reproduction Path] What operations were performed to encounter the issue
I would like to ask, I did a test using Python code to run batch inserts (purely insert). I am inserting 3 billion records into a single table, and currently, after inserting 400 million records, it has become very slow (it takes 15-20 seconds for every 200,000 records). I would like to ask if there are any optimization points or if there are any good tools recommended. Note: The disk is an ordinary SSD, and it does not meet the official requirements.
[Encountered Issues: Issue Phenomenon and Impact]
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
What is the format of the data? If it’s in CSV format, you can use Lightning to import it.
It can be converted to CSV. I have used Lightning before, but it requires manual conversion to CSV and then executing Lightning, which is quite troublesome. So I want to ask if there are any other good methods.
Check if useServerPrepStmts and cachePrepStmts are set to true in the JDBC connection.
Also, pay attention to prepStmtCacheSqlLimit and prepStmtCacheSize, these should be set to a higher value, otherwise just setting the above two values to true won’t be effective.
Are you using batch? If not, start using it.
If you are using it, remember to set rewriteBatchedStatements = true.
It is possible that there is a hotspot. Did you add the parameter to split regions when creating the table? If not, you can use split to split the existing regions, and then continue to insert and see.
So how is the data being inserted now? Is it simply a Python script generating insert statements based on certain logic and then inserting them?
Let’s see if there are any hotspot issues. If it’s just writing, it won’t slow down…
If the disk isn’t good enough, you’ll have to sacrifice write speed and write in smaller amounts. If you write too frequently, the disk IO definitely won’t be able to handle it.
Introduce the cluster hardware configuration, and whether the machines are virtual machines.
Please also use Lightning, insert can’t outperform it.
There really isn’t a batch, I’ll give it a try.
The virtual machine in the self-built data center seems to have disk issues. Indeed, the disk IO can’t handle it.
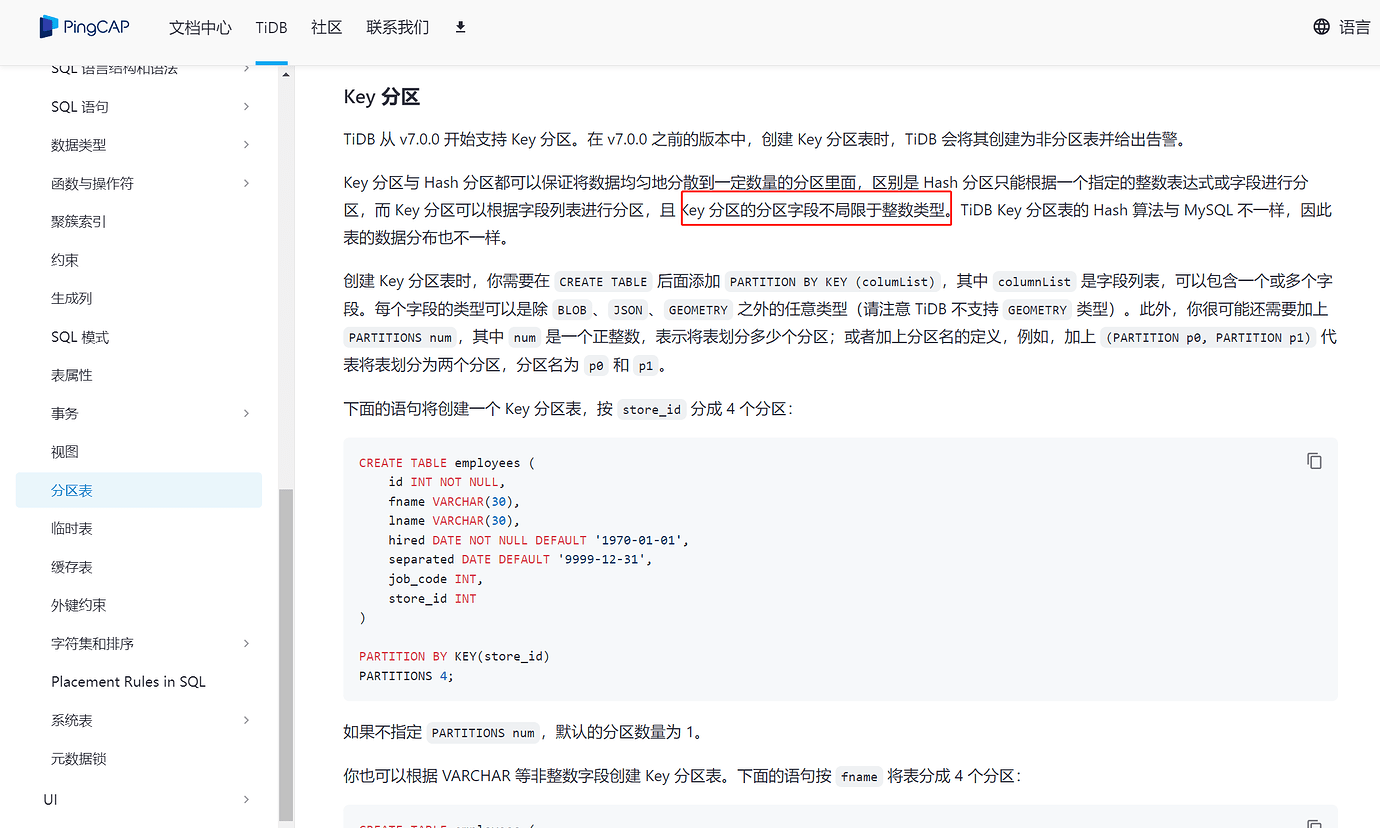
Created a partitioned table,
using random UUID and key partitioning