Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: binlog drainer 开启后总是有时up 有时down
【TiDB Usage Environment】Production\Test Environment\POC Production Environment 【TiDB Version】V5.4.0 【Encountered Problem】The binlog drainer is sometimes up and sometimes down after being enabled 【Reproduction Path】What operations were performed to cause the problem` It started right after deployment
【Problem Phenomenon and Impact】Unable to synchronize data
【Attachments】
-
Relevant logs, configuration files, Grafana monitoring (https://metricstool.pingcap.com/)
-
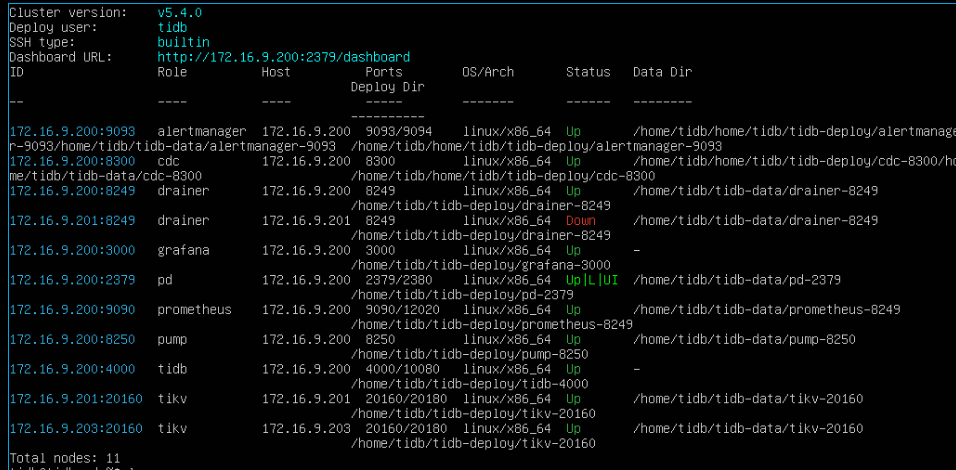
TiUP Cluster Display information
-
TiUP Cluster Edit config information
-
TiDB-Overview monitoring
-
Corresponding module’s Grafana monitoring (if any, such as BR, TiDB-binlog, TiCDC, etc.)
-
Corresponding module logs (including logs from 1 hour before and after the issue)
If the question is related to performance optimization or troubleshooting, please download the script and run it. Please select all and copy-paste the terminal output results for upload.
Please provide the drainer logs. It seems to be in a state of repeated restarts.
I once encountered an issue where the primary database executed operations to add primary keys and unique indexes, but the drainer did not have syncer.to.read-timeout set. This caused the primary key statement sent to the replica to succeed, but the frontend timed out. As a result, it repeatedly continued to send primary key and unique index operations, manifesting as repeated up and down actions.
I have tried tiup cluster reload multiple times, and each time it starts successfully. However, when I check the drainer process status, it keeps alternating between up and down.
Is there an issue with the configuration file? I see the error says the table does not exist. Does the downstream have this table?
ERROR] [server.go:291] [“syncer exited abnormal”] [error=“failed to add item: table gas1.xj_inspection_records: table not exist”]
I have deployed two drainer nodes, each connected to a different MySQL. One of them has the gas1.xj_inspection_records table, while the other does not. Could this cause the issue?
If you want one to be synchronized and the other not, you need to filter out this table in the configuration file of the unsynchronized drainer.
If I want to synchronize all the tables in the database, how should I write this format?
For all the tables in the database, you only need to configure the databases that need to be synchronized.
replicate-do-db
However, if there are tables in the upstream database that do not need to be synchronized to the downstream, you need to use ignore-table to filter them out.
Thank you, the issue has been resolved.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.