Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: Binlog报错异常退出
【TiDB Usage Environment】Testing Environment
【TiDB Version】tidb3.0.0 tidb5.2.4
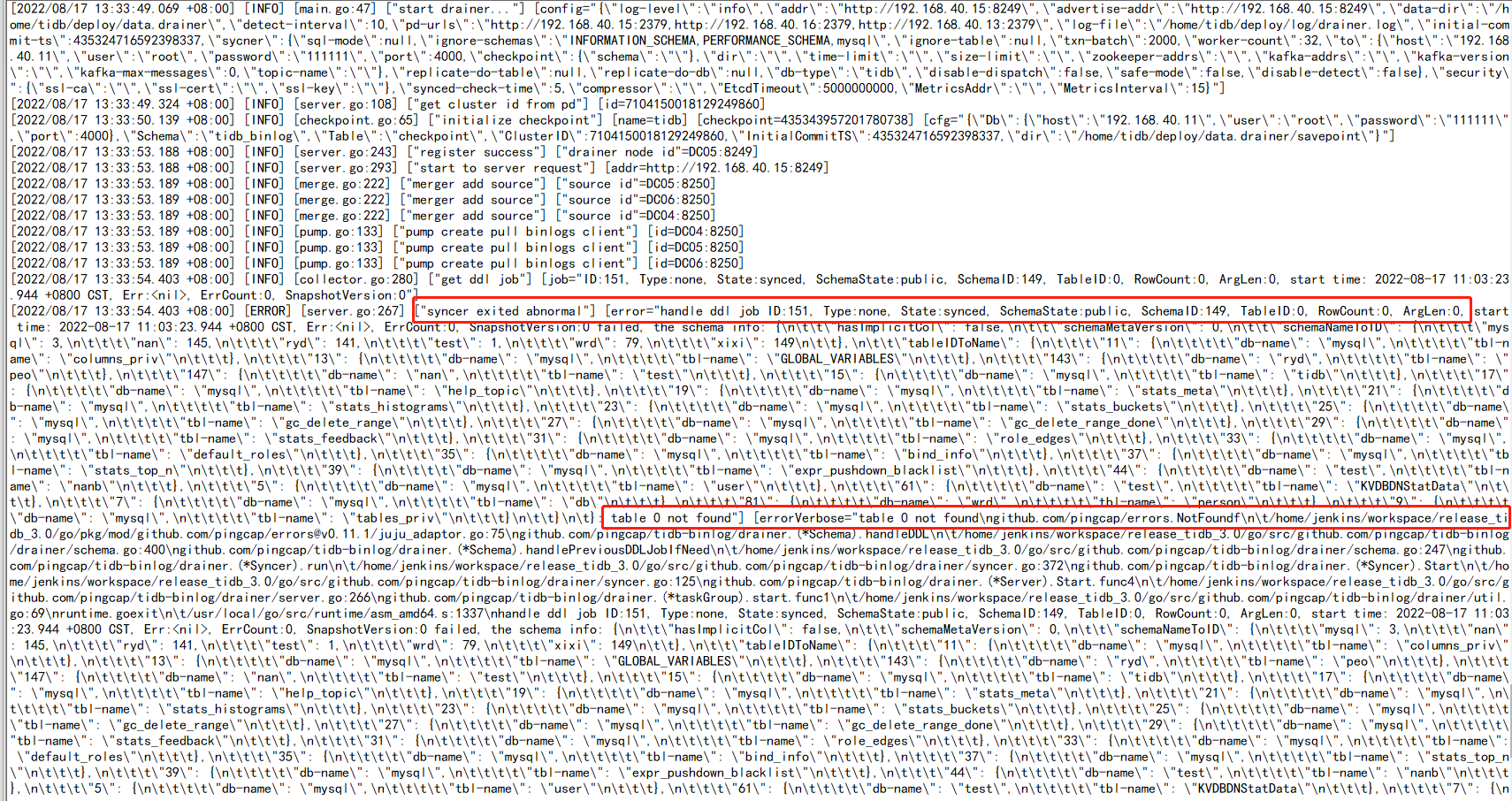
【Encountered Issue】After performing table creation operations in the upstream cluster, it was found that the downstream cluster binlog did not synchronize. Checking drainer showed an abnormal exit.
On the drainer server, sudo systemctl restart drainer-8249.service
The service starts normally, but the error persists, and drainer still exits.
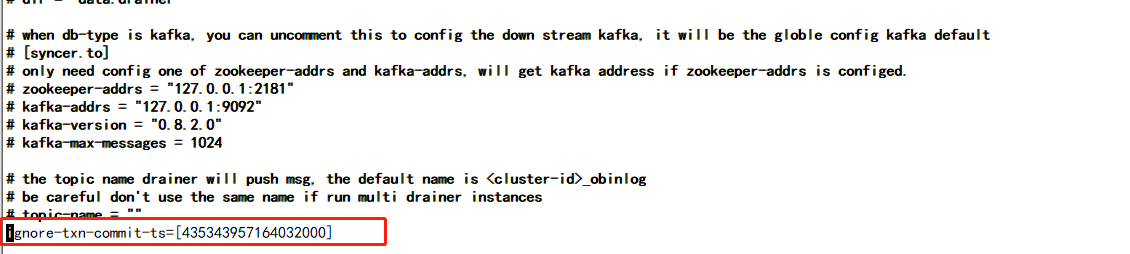
I want to skip this DDL operation, so I added ignore-txn-commit-ts in drainer.toml, but there is no such timestamp in drainer.log.
Manually execute the DDL directly on the downstream, and then restart the drainer.
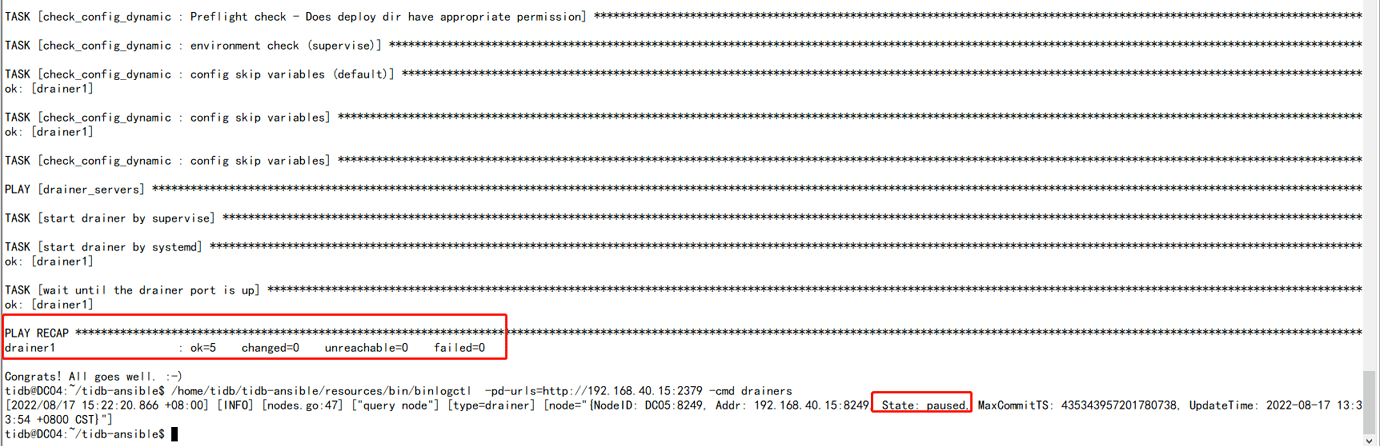
I deleted the newly created table upstream and downstream just now, then restarted the drainer on the drainer server, but the logs still report the same error. When I used ansible-playbook to restart on the TiDB server, it indicated a successful restart, but the actual status is still not up.
After restarting the drainer server, it still reports the same error and exits. Please take a look!
What is the version of binlog?
You can try converting this time and then add it to ignore-txn-commit-ts and restart to see if it works.
Could you please tell me how to convert this time to a timestamp?
Binlog is included with TiDB v3.0.0.
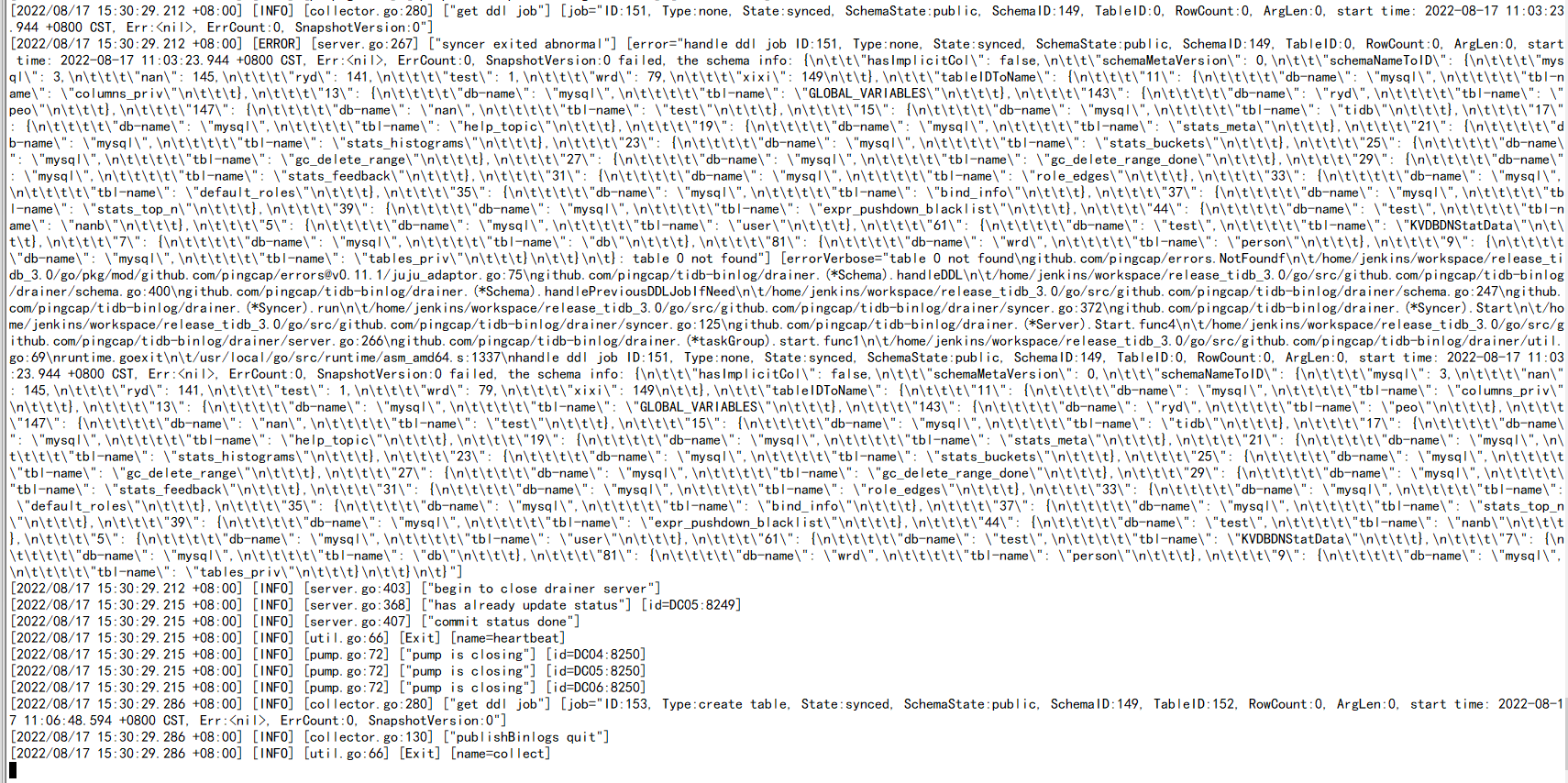
After converting with Python and adding it to the drainer configuration file, the drainer still exits after restarting. 
Try setting checkpoint-tso + 1 to ignore as well.
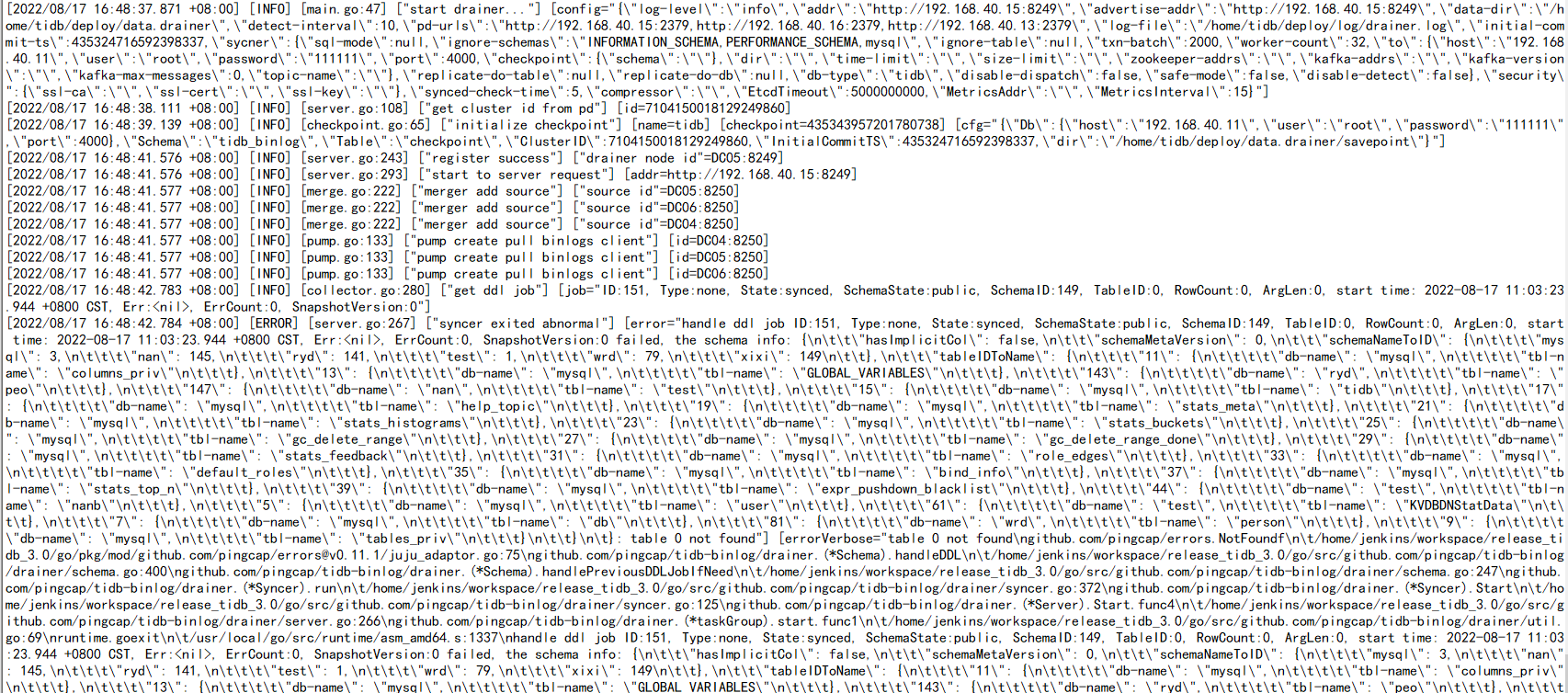
It still doesn’t work. After restarting, the drainer still exits.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.