【TiDB Usage Environment】Test Environment
【TiDB Version】Upstream Cluster v3.0, Downstream Cluster v5.2
【Encountered Problem】
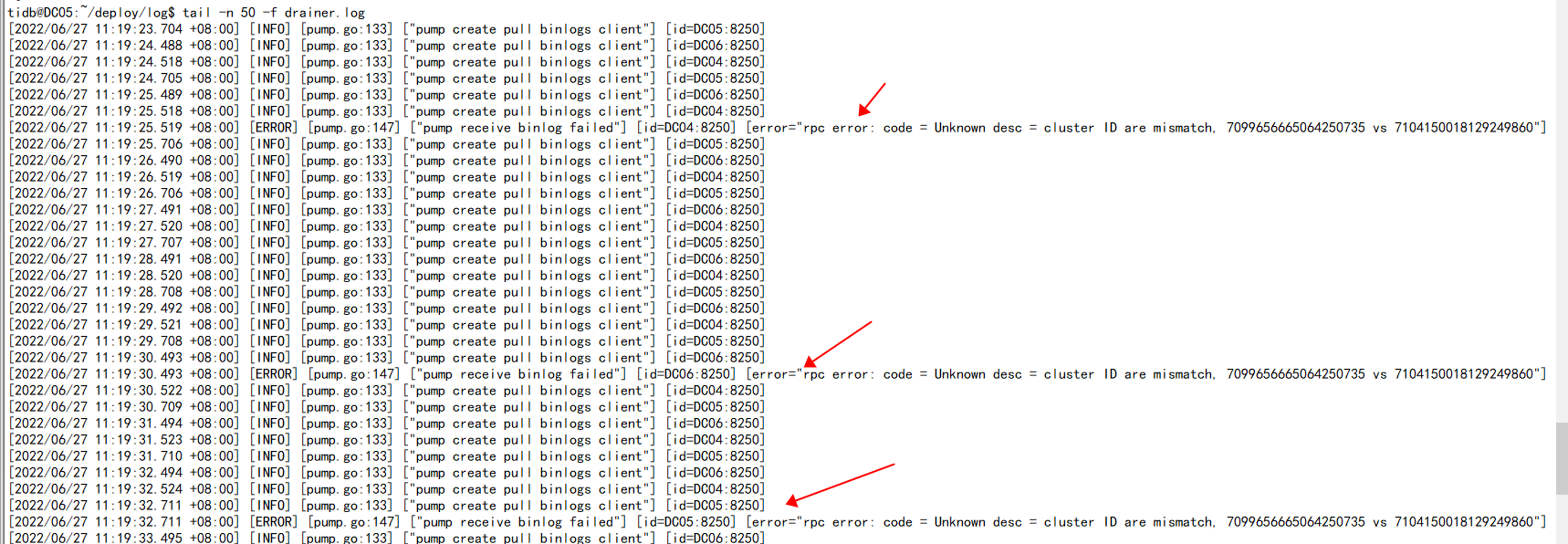
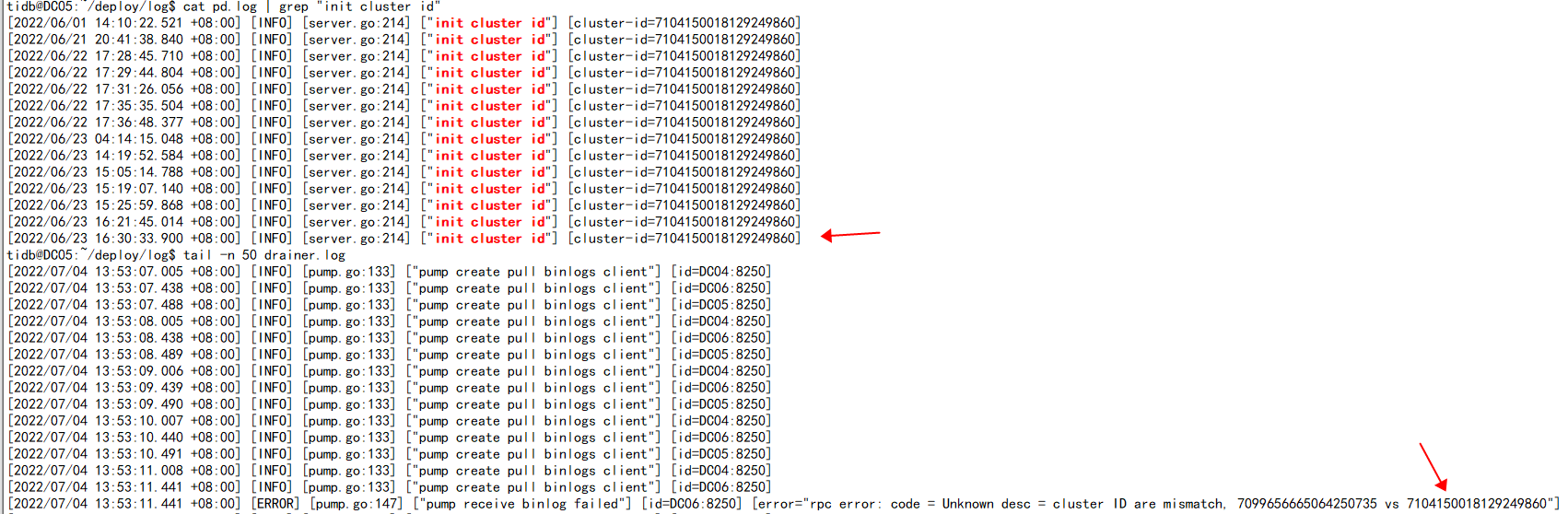
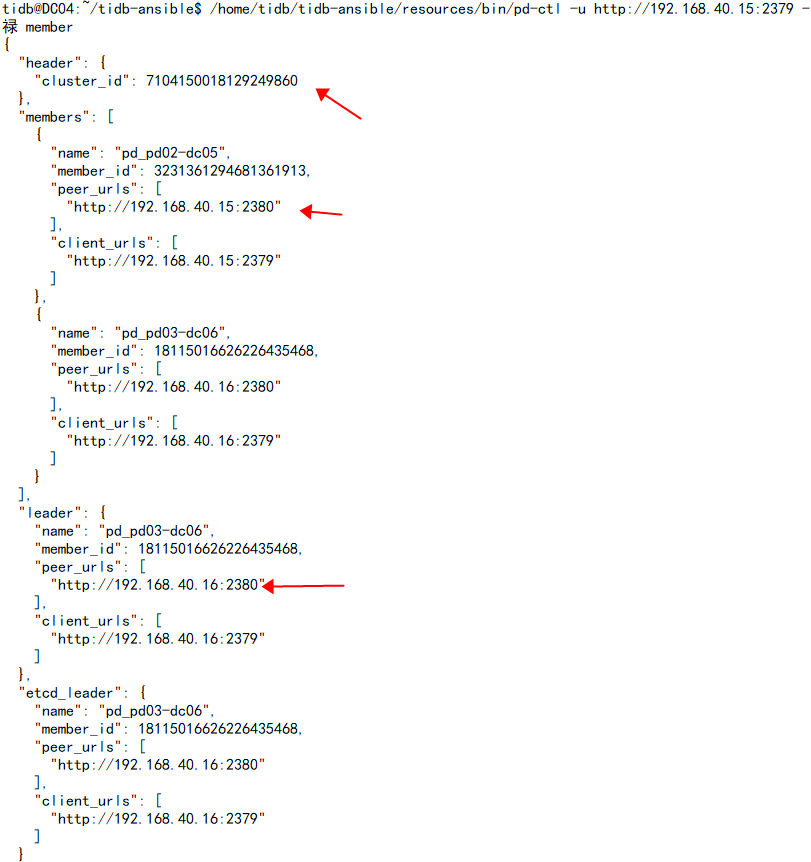
After performing an insert operation on the upstream cluster, there is no synchronization observed in the downstream cluster. Checking the drainer.log log shows the error [ERROR] [pump.go:147] [“pump receive binlog failed”] [id=DC04:8250] [error=“rpc error: code = Unknown desc = cluster ID are mismatch, 7099656665064250735 vs 7104150018129249860”].
The binlog configuration is normal. The binlog worked for two days before, but then it stopped synchronizing incremental data. I deleted the pump, drainer, and binlog configurations, restarted the cluster, and reconfigured the pump, drainer, and binlog files. After restarting the TiDB cluster, incremental synchronization was normal again. However, after two days, incremental synchronization failed. Checking the drainer logs, I found the error as shown above.
It looks like the cluster ID is conflicting. Could you please advise on how to specify a new cluster ID to ensure drainer synchronization works correctly?
I checked, the clusterID is obtained from PD. It is recommended to rebuild the drainer after recording the checkpoint. Directly fixing it is not easy and carries significant risk.
I am testing the scaling in and out of nodes (tikv, pd, tidb) between two clusters (TiDB(3.0.3)\TiDB(5.2.4)). Several issues have arisen during the process.
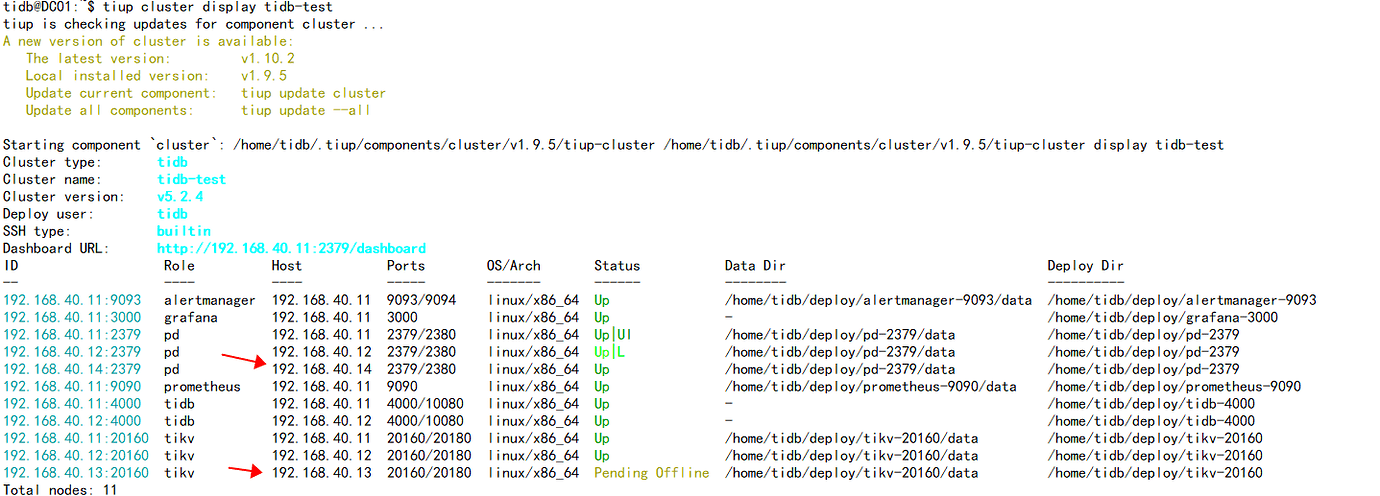
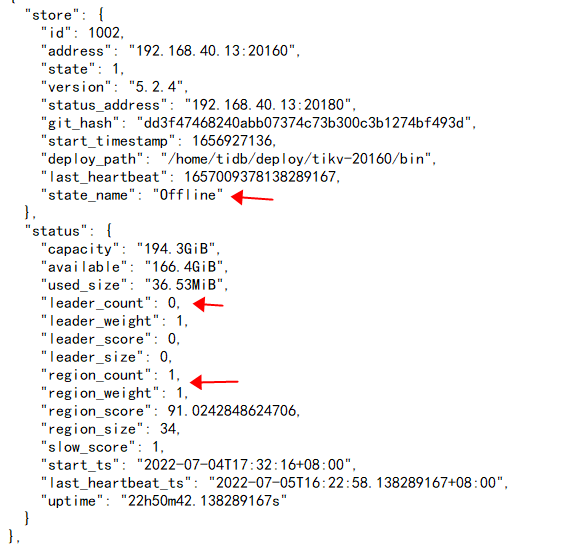
Currently, I scaled in the pd (192.168.40.14) of v3.0.3 and then scaled it out to the v5.2.4 cluster, and the test was normal. However, when I scaled in the tikv (192.168.40.13) of v5.2.4, it has been in the Pending Offline state for a week, with some data in the test cluster.
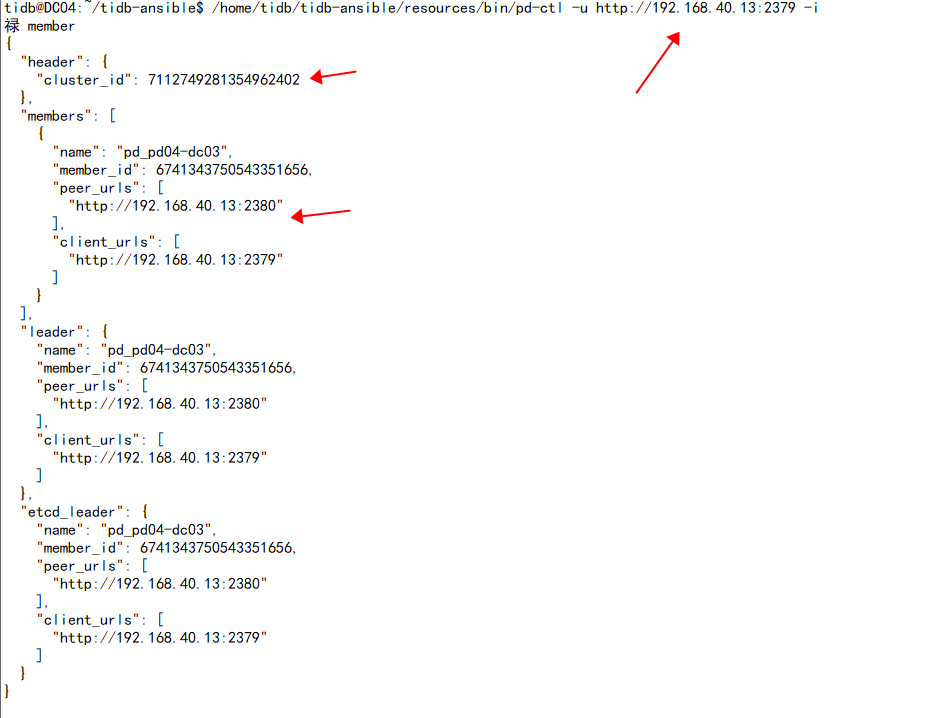
When I scaled in the pd (192.168.40.13) of v5.2.4 and then scaled it out to the v3.0.3 cluster, the issue you mentioned in your screenshot occurred. I could only see it by specifying 192.168.40.13 using pd-ctl, and the cluster_id was different.
For servers from other clusters, please ensure the data directory is cleared before expansion. If clearing the data is inconvenient, please use another directory.
Hello, I used tiup cluster scale-in <cluster-name> --node IP:20160 in the v5.2.4 cluster and it showed that the scale-in was successful, but it has been in the offline state and has not changed to the Tombstone state. This is because there are still peers on the store, and it should automatically transfer the leader and region to become the Tombstone state. However, after executing the scale-in command, the data has not been transferred. How can I change the state?