Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: BR 备份报错,为啥有的集群没问题
tidb 5.0.3
(There are two other clusters online, one is 5.0.1 and the other is 5.1.1. The backup tasks have been running for a year without any issues. Last night, I backed up this cluster for the first time, which is version 5.0.3. Later, I used dumpling to back up locally, but it also got interrupted.  See the screenshot at the bottom. Do I need to increase the maximum SQL execution time?)
See the screenshot at the bottom. Do I need to increase the maximum SQL execution time?)
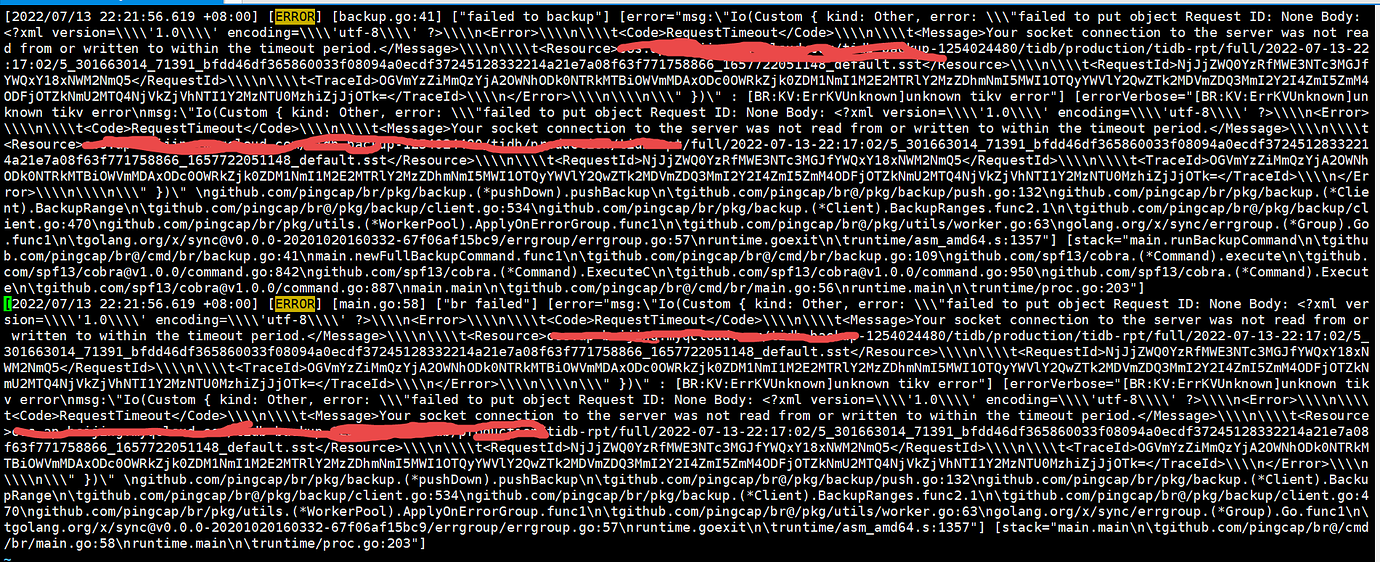
Error message:
br version:
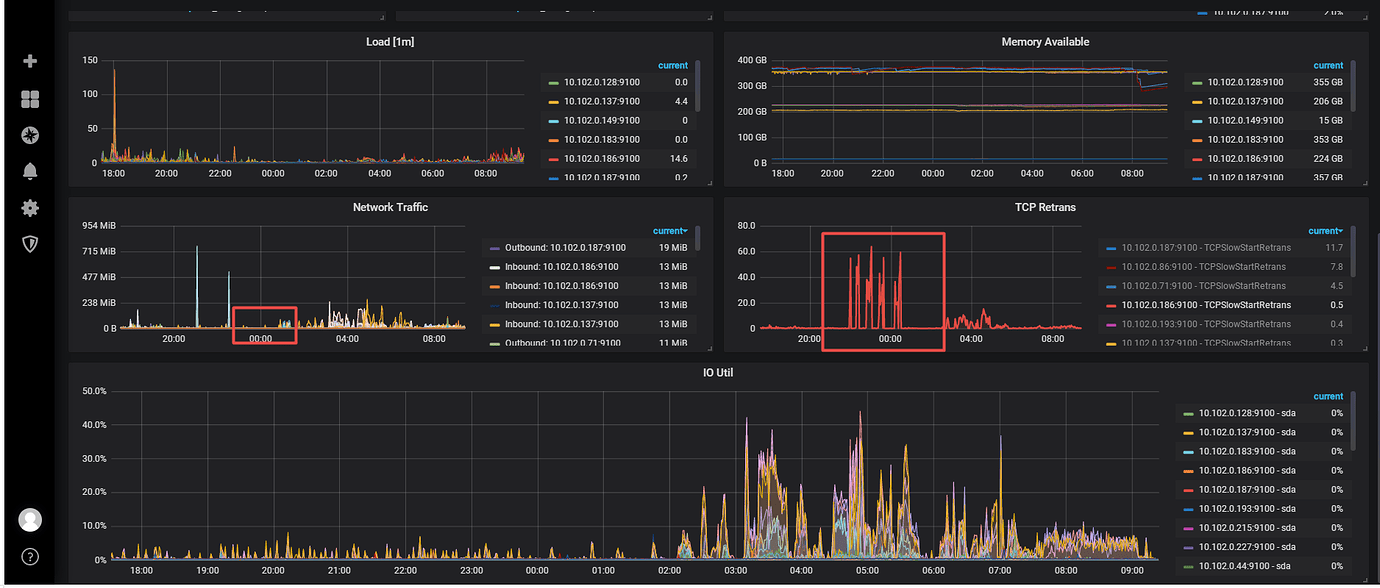
I noticed from the monitoring that the tcp retransmissions are a bit high, but the network card traffic is not large at this point. This coincides with the time I was backing up.
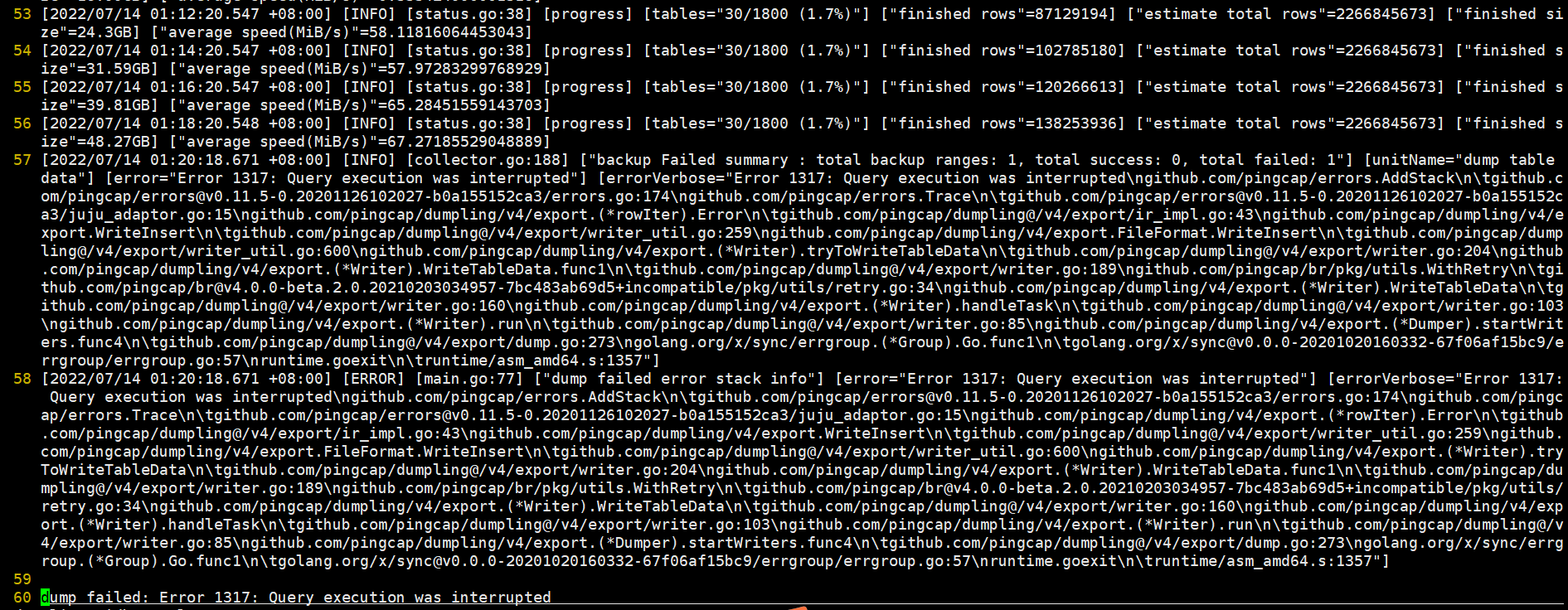
dumpling interruption error:
I checked the logs, and the table in dumpling’s SQL has an ID with the auto_random attribute. The data volume is 250 million. My maximum SQL execution time is 10 minutes, which should have exceeded the time limit and got KILLed, causing the dumpling task to be interrupted. Not sure if this is the logic.
BR full backup timed out and failed. How long has the backup job been running? Is this the first time it has occurred? Was there a network anomaly between BR and TiKV at that time?
Later, using this new version, I ran it twice and both times it got stuck on this error.
This cluster is running a backup for the first time; it hasn’t been backed up before. The cluster has been running for a long time. It’s on Tencent Cloud hosts, and there are no anomalies in internal network communication. After 10 PM, there’s no traffic. The backup has been retried several times but always gets stuck on this error after running for about 10 minutes.
I noticed that the TCP retransmissions are relatively high, coinciding with my backup attempts. I see that the network card traffic isn’t significant.
Where is the backup stored, and is the network communication okay during this process?
Is the backup directory using NFS?
On COS, Tencent Cloud’s object storage. Their product communication is via the internal network.
There are no issues with the access to this storage on the nodes where TiKV is located, right? Permissions, paths, etc.?
Administrator privileges were granted, the data file was written, and the backup was interrupted after running for more than 10 minutes.
It seems there was a similar bug before. Let’s see if other experts can help you.
The TiDB cluster and backup storage are across different clouds, and the dedicated line is unstable. There were network communication issues during the backup process, causing the task to time out and be interrupted.
We previously also synchronized a large amount of data from Alibaba Cloud’s ECS server to OSS. Even within the same cloud, if the throughput is too high, there will be limitations, and the synchronization will be directly disconnected.
This topic was automatically closed 1 minute after the last reply. No new replies are allowed.