About the Author: Li Li, Product Manager at PingCAP.
TL;DR
This article introduces how to use Generative AI to build a user assistance robot that uses a corporate-specific knowledge base. In addition to the industry’s commonly used knowledge base response method, it also attempts to judge toxicity under the few-shot method. Eventually, the robot has been applied to various channels facing global customers of the company, with a dislike ratio of less than 5% after user usage.
The Magic of Generative AI Unveiled
Since 2022, Generative AI (hereafter referred to as GenAI) has spearheaded a global revolution. From the buzz created by MidJourney and DALL-E in generating imagery from text, to the phenomenal attention garnered by ChatGPT through its natural and fluent conversations, GenAI has become an unavoidable topic. Whether AI can support better living and work in more general scenarios became one of the core topics in 2023.
The rise of development tools such as LangChain signifies that engineers have begun to mass-produce applications based on GenAI. PingCAP has also conducted some experiments and accomplished some works, such as:
-
Ossingisht’s Data Explorer: A project that generates SQL to explore Github open-source software projects using natural language
-
TiDB Cloud’s Chat2Query: A project that uses the in-cloud database to generate SQL using natural language
After building these applications, the author began to contemplate whether the capabilities of GenAI can be used to construct more universal applications, providing bigger value for the users.
Considering the Demand
With the global growth of TiDB and TiDB Cloud, providing support for global users has become increasingly important. As the number of users grows exponentially, the number of support staff will not increase rapidly. Hence, how to handle the large volume of users becomes an urgent matter to consider.
Based on the actual experience of supporting users, according to our research on the user queries in the global community and the internal ticket system, over 50% of the user issues could actually be addressed by referring to the official documentation. It’s just that the vast volume of content makes it difficult to find. Therefore, if we can provide a robot armed with all the necessary knowledge from the official TiDB documentation, perhaps it could help users utilize TiDB more effectively.
The Gap between Generative AI and Demand Fulfillment
After identifying the demand, it’s also necessary to understand the characteristics and limitations of GenAI to determine whether it can be applied to this particular demand. Based on the work completed so far, the author is able to summarize some features of GenAI. Here, GenAI primarily refers to GPT (Generative Pre-trained Transformer) type models, with text dialogue as the main focus, and GPT will be used to describe in the following context of this article.
Capabilities of GPT
-
Ability to understand semantics. GPT possesses a strong capability in comprehending semantics, essentially able to understand any given text without obstacles. Regardless of the language (human or computer languages), the level of textual expression — even in a multilingual mixture, or texts with grammatical or vocabulary errors, it can interpret user queries.
-
Logical reasoning ability. GPT has a certain degree of logical reasoning power. Without the need for additional special prompt words, GPT can perform simple inference and uncover deeper contents of a question. With certain prompt words supplemented, GPT can demonstrate stronger inferential capabilities. The methods to provide these prompt words include Few-shot, Chain-of-Thought (COT), Self-Consistency, Tree of thought (TOT), and so on.
-
Attempting to answer all questions. GPT, especially the Chat type, like GPT 3.5, GPT 4, will always try to respond to all user questions in a conversational form, as long as it aligns with the preset value perception, even if the answer is “I cannot provide that information.”
-
General knowledge capability. GPT itself possesses a vast amount of general knowledge, which is highly accurate and covers a broad range.
-
Multi-turn dialogue capability. GPT is set up to understand the meanings of multiple dialogues between different roles, meaning it can utilize the method of further questioning in a conversation without having to repeat all the historical key information in every dialogue. This behavior aligns very well with human thinking and conversational logic.
Limitations of GPT
-
Passive triggering. GPT requires an input from the user to generate a response. This implies that GPT would not initiate interaction on its own.
-
Knowledge expiration. This specifically refers to GPT 3.5 and GPT 4. The training data for both cease in September 2021, which means any knowledge or events post this date are unknown to GPT. It is unrealistic to expect GPT to provide new knowledge itself.
-
Illusion of specialized fields. Although GPT possesses excellent abilities in general knowledge, in a specific knowledge domain, such as the author’s field of database industry, most of GPT’s answers are more or less erroneous and cannot be trusted directly.
-
Dialogue length. GPT has a character limit for each dialogue round. Therefore, if the content provided to GPT exceeds this character limit, the dialogue will fail.
Gap in Implementation of Requirements
The author intends to use GPT to realize an “enterprise-specific user assistant robot,” which means the following requirements:
-
Requirement 1: Multiturn dialogues, understanding the user’s queries, and providing answers.
-
Requirement 2: The content of the answers regarding TiDB and TiDB Cloud must be accurate.
-
Requirement 3: Can’t answer content unrelated to TiDB and TiDB Cloud.
Analyzing these requirements:
-
Requirement 1: can basically be met, based on GPT’s “ability to understand semantics,” “logical reasoning ability,” “try to answer questions ability,” and “context understanding ability.”
-
Requirement 2: can’t be met. Due to GPT’s “knowledge obsolescence” and “illusion of segmented fields” limitations.
-
Requirement 3: can’t be met. Due to GPT’s “ability to attempt to answer all questions”, any question will be answered, and GPT itself does not restrict the answering of non-TiDB related questions.
Therefore, in the construction of this assistant robot, it is mainly about solving problems with requirement two and requirement three.
Correct Answering in Sub-Domains Knowledge
Here, we are to address the second requirement.
The task of enabling GPT to answer user’s queries based on specific domain knowledge is not a new field. My previous optimization for Ossinsight - Data Explorer uses such specific domain knowledge, helping boost the execution rate of natural language generated SQL (i.e., the SQL generated can successfully run and produce results in TiDB) by over 25%
What needs to be employed here is the spatial similarity search capability of vector databases. This typically involves three steps:
Storing Domain Knowledge in a Vector Database
The first step is to put the official documents of TiDB and TiDB Cloud into the vector database.
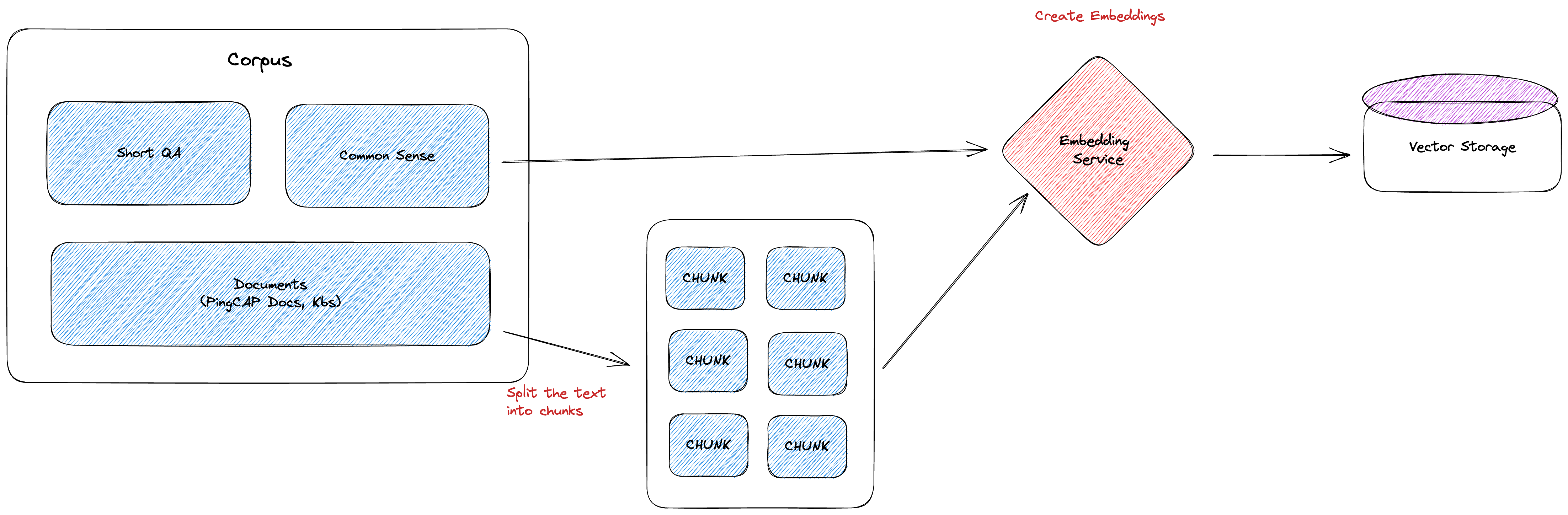
Once the documents have been retrieved, the text content is put into the Embedding model to generate the corresponding vector of the textual content, and these vectors are placed into a specific vector database.
In this step, two points need to be checked:
-
If the quality of the document is poor, or the format of the document does not meet the expectations, a round of preprocessing will be carried out on the document in advance to convert it into a relatively clean text format that can be easily understood by LLM.
-
If the document is long and exceeds the single conversation length of GPT, the document must be trimmed to meet the length requirement. There are many methods of trimming, such as trimming by specific characters (e.g., commas, periods, semicolons), trimming by text length, and so on.
Searching for Relevant Content from the Vector Database
The second step is to search for relevant text content from the vector database when the user poses a question.
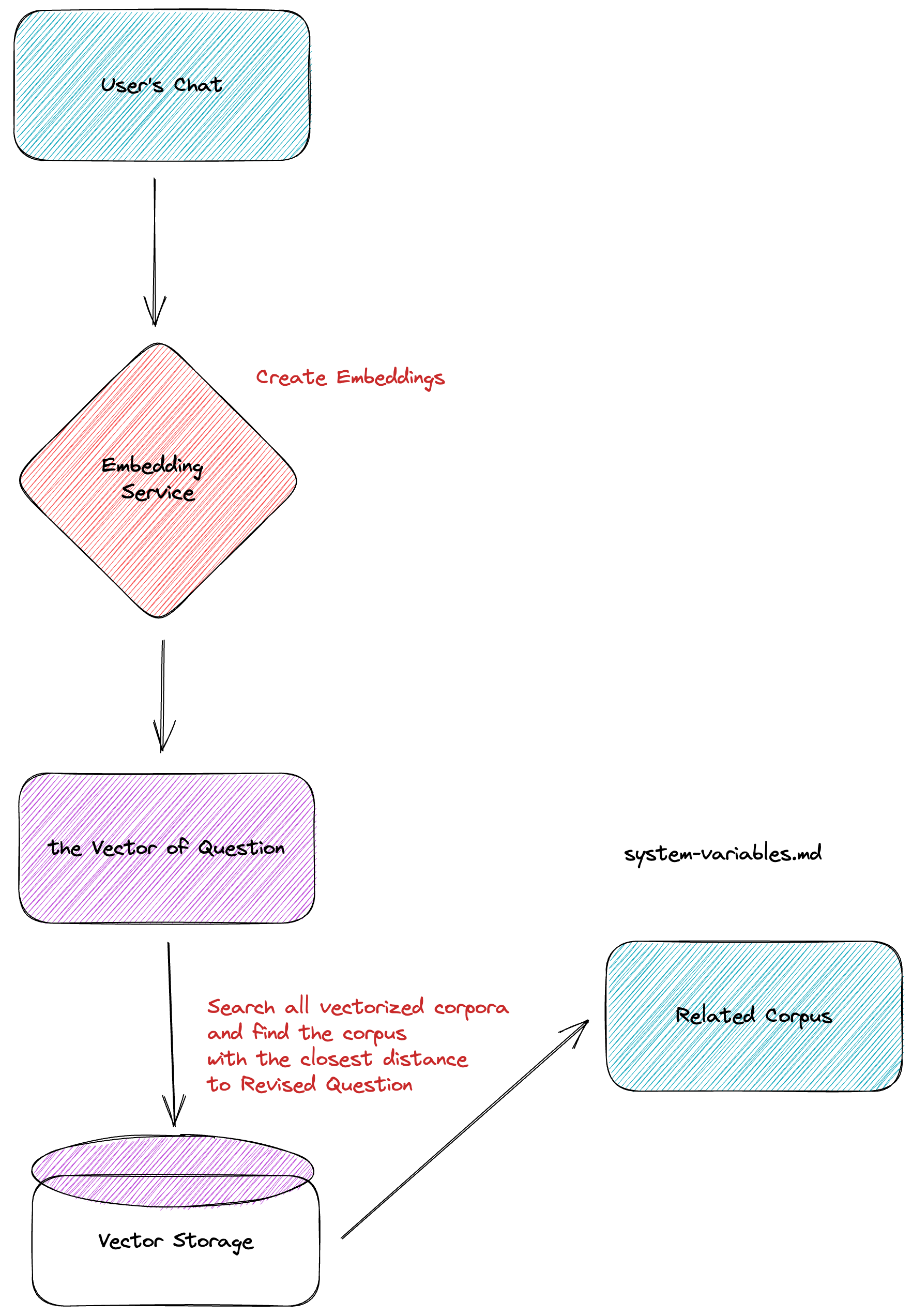
When a user initiates a conversation, the system will convert the user’s conversation into a vector through the Embedding model and put this vector into the vector database to perform a search with the existing data. During the search, we use similarity algorithms (such as cosine similarity, dot-product, etc.) to calculate the most similar domain knowledge vectors and extract the text content corresponding to these vectors.
A user’s specific question may require multiple documents to answer, hence during the search, we retrieve the top N (currently N equals 5) documents with the highest similarity. These top N documents can satisfy the need for spanning multiple documents, all of which will contribute to the content provided to GPT in the next step.
Relevant content and user queries are presented to GPT together.
The third step is assembling all the pertinent information and submitting it to GPT.
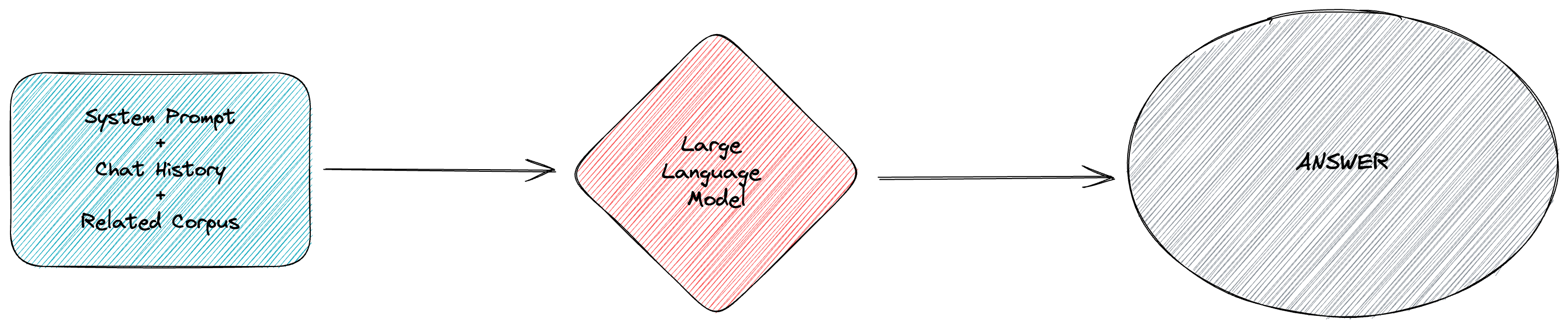
The task objective and relevant domain knowledge are incorporated into the system prompts and the chat history is assembled based on past dialogues. Providing all the content to GPT allows for a domain-specific response based on this acquired knowledge.
Upon completing the above steps, basically, we can meet the second requirement - answering questions based upon specific domain knowledge. The correctness of the answers is greatly improved compared to directly querying GPT.
Limiting the Response Field
Here we aim to address the issue raised in Demand Three.
As this robot is intended to serve as a business support capability for users, we expect it to only answer questions related to the company itself, such as those about TiDB, TiDB Cloud, SQL issues, application construction problems, etc. If inquiries go beyond these scopes, we hope the robot will decline to respond, for instance to questions about the weather, cities, arts, etc.
Given that we previously mentioned GPT’s aptitude to “attempt to answer all questions”, it is within GPT’s own setting that it should respond to any question in a manner that aligns with human values. Therefore, this restriction cannot be built with the help of GPT, and must be attempted on the application side.
Only by accomplishing this requirement can a service actually go live to serve its users. Regrettably, at present, there isn’t any satisfactory industrial solution for this. Indeed, the majority of application designs do not even address this aspect.
Concept: Toxicity
As mentioned earlier, GPT attempts to tailor its responses to align with human values, a step referred to as “Alignment” in model training. It prompts GPT to deny answering questions related to hate and violence. If GPT doesn’t comply with the condition and ends up answering hate or violence-related questions, it is deemed as having displayed toxicity.
Therefore, with regard to the robot that I’m about to create, the scope of toxicity has effectively expanded. Namely, any responses not pertaining to the company’s business can be considered as being laced with toxicity. Under this definition, we can draw upon the previous work done in the field of detoxification. Johannes Welbl from DeepMind (2021), among others, advises utilizing language models for toxicity detection. Now, with the considerable advancements in GPT’s capabilities, it has become possible to use GPT itself to judge whether a user’s question falls within the company’s business scope.
To limit the answer domain, two steps are necessary.
Determination within a limited domain
The first step is to evaluate the user’s initial inquiry.
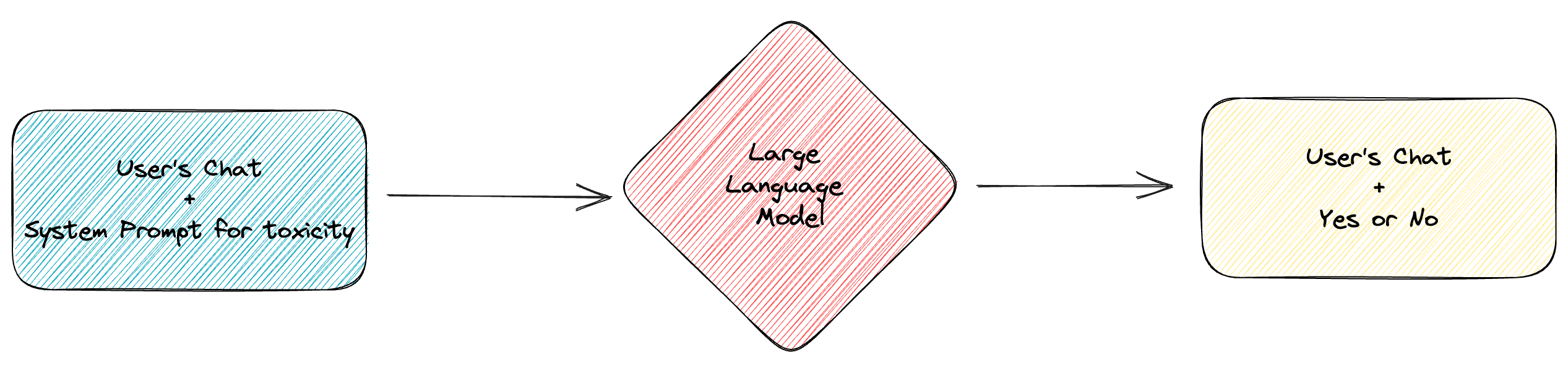
Here, it’s necessary to use the few-shot method to construct prompts for toxicity detection, enabling GPT to determine if the user’s inquiry falls within the scope of enterprise services when multiple examples are at hand.
For instance, some examples are:
<< EXAMPLES >>
instruction: who is Lady Gaga?
question: is the instruction out of scope (not related with TiDB)?
answer: YES
instruction: how to deploy a TiDB cluster?
question: is the instruction out of scope (not related with TiDB)?
answer: NO
instruction: how to use TiDB Cloud?
question: is the instruction out of scope (not related with TiDB)?
answer: NO
After the judgment is completed, GPT will input ‘Yes’ or ‘No’ for subsequent proceedings. Note, here ‘Yes’ signifies ‘toxic’ (not relevant to the business), and ‘No’ means ‘non-toxic’ (relevant to the business).
Post-Judgment Processing
In the second step, after obtaining whether the result is toxic or not, we branch the processes into two: toxic and non-toxic, for the handling of abnormal and normal processes respectively.

The normal process is the Correct Answering in Sub-Domains Knowledge, as mentioned above. The focus here is on the explanation of the abnormal process flow.
When the system discovers that the generated content is “Yes”, it will guide the process into the toxic content reply process. At this time, a system prompt word that refuses to answer the user’s question and the corresponding question from the user will be submitted to GPT, and finally, the user will receive a reply that refuses to answer.
Upon completing these two steps, Requirement Three is essentially completed.
Overall Logical Framework
Thus, we have developed a basic assistant robot, which we named TiDB Bot, that can be provided to users and has specific enterprise domain knowledge.
TiDB Bot Test Stage Results
Starting from March 30, TiDB Bot began internal testing, and officially opened to Cloud users on July 11.
During the 103 days of TiDB Bot’s incubation, countless communities and developers provided valuable feedback on the test product, gradully making TiDB Bot usable. During the test phase, a total of 249 users accessed the bot, sending 4570 messages. By the end of the test stage, 83 users had given 266 pieces of feedback, with negative feedbacks accounting for 3.4% of the total amount of information conveyed and positive feedbacks accounting for 2.1%.
In addition to the direct users, there were also communities who suggested ideas and proposed more solutions. Thank you to all the communities and developers, without you, the product launch of TiDB Bot would not have been possible.
Further Plans
As the number of users steadily increases, there still remain significant challenges whether in terms of the accuracy of recall content or toxicity judgment. Therefore, the author has been optimizing the accuracy of TiDB Bot in actual service provision, to gradually enhance the effectiveness of its answers. These matters will be introduced in future articles.