[TiDB Usage Environment] Production Environment
[TiDB Version]
[Reproduction Path] What operations were performed when the issue occurred
[Encountered Issue: Issue Phenomenon and Impact]
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
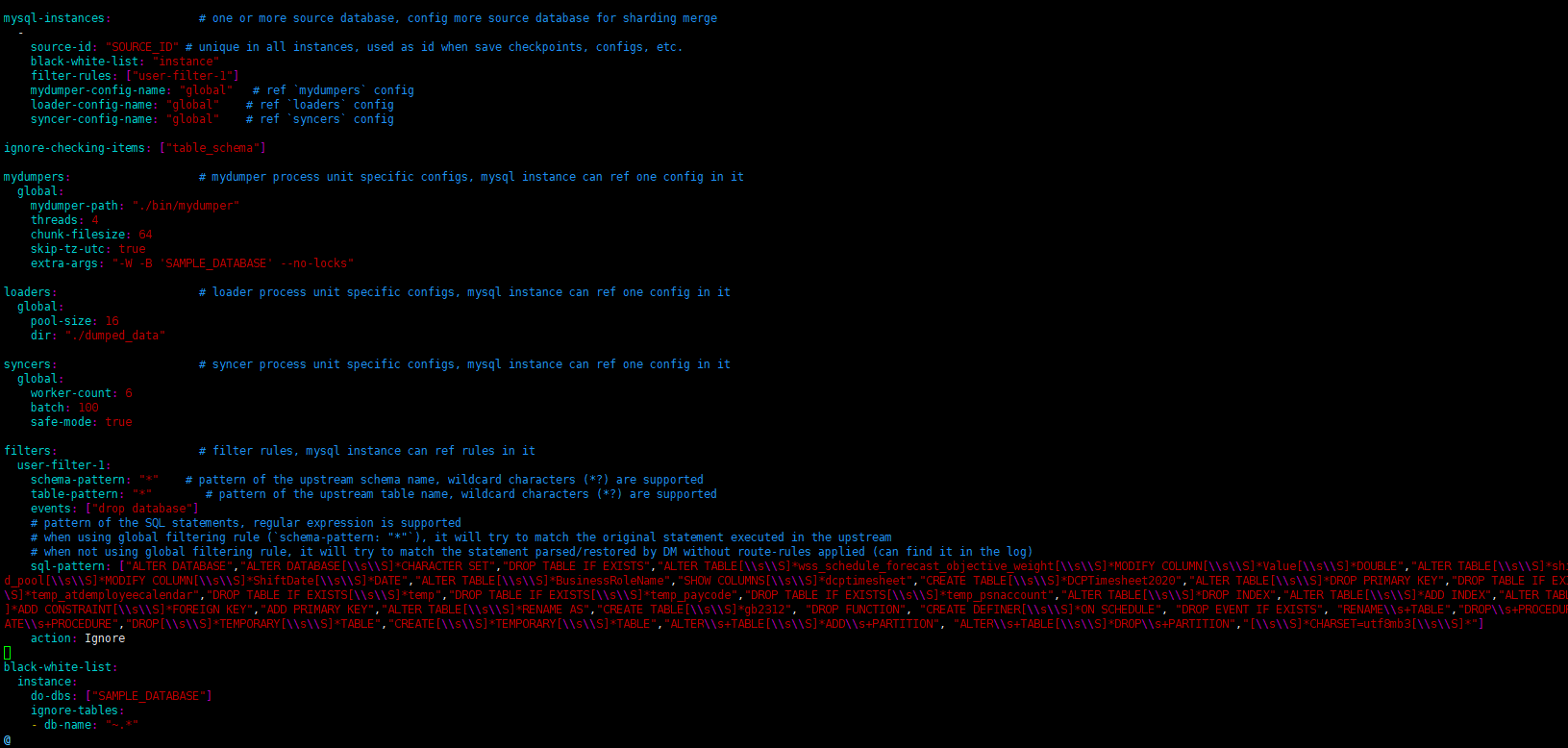
[Attachments: Screenshots/Logs/Monitoring]
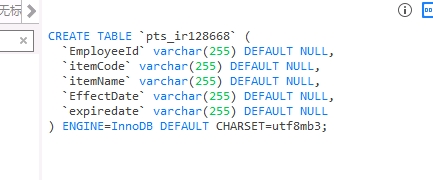
Table Structure
Data duplicates after a long time
Error:
DM task might restart, or a switch might occur. There will be a period of safemode mode, during which some data will be replayed multiple times for safety.
A switch occurred, specifically what does it mean? Could master-slave switching also cause it? Or restarting the worker? Or could resuming the task also cause it?