Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TIDB 在模糊查询场景是否也能用到计算下推特性
【TiDB Usage Environment】Production Environment
【TiDB Version】V6.5.8
【Encountered Problem: Phenomenon and Impact】Can TiDB use the compute pushdown feature in fuzzy query scenarios, for example:
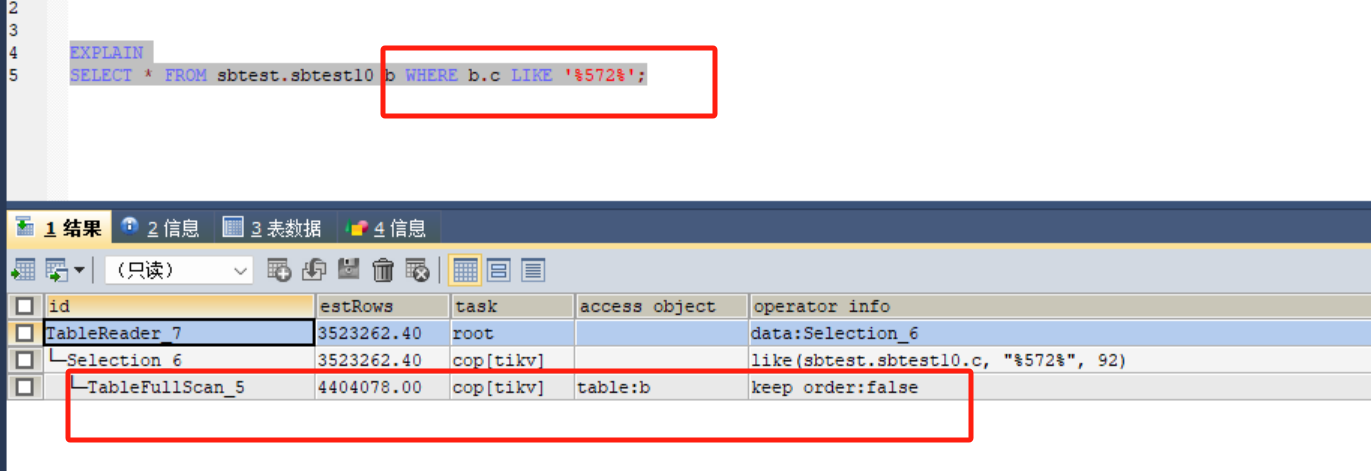
select col1, col2 from tab where col3=xxx and col4 like ‘%aaaa%’ order by col5 asc. In this kind of fuzzy query with percentage signs at both ends, after testing, it was found that [execution plan TableRangeScan at the scale of ten thousand rows], the execution time of TiDB indeed does not show a significant improvement compared to native MySQL. Has anyone encountered this?
TiDB has a significant advantage when dealing with large amounts of data and numerous TiKV instances.
According to the documentation, it should support pushdown.
The best use case for TiDB is systems with relatively large amounts of data, usually tens of millions, hundreds of millions of rows, and data scales at the TB level. If it’s a scenario that a single MySQL instance can handle, you might as well consider using MySQL.
Well, distributed systems require large amounts of data and can’t handle everything.
From the row retrieval perspective, it’s around a million rows, but the performance difference compared to MySQL is not significant. 
I have seen the official documentation, but there are several scenarios for LIKE fuzzy queries. It is estimated that the scenario without % at the beginning will be faster, while the effect will not be obvious if there are % at both ends.
The official documentation is supported.
 It’s possible, but we still need to confirm it through practice.
It’s possible, but we still need to confirm it through practice.
Tested it in real scenarios, the improvement is not significant.
I just tried it, and it indeed doesn’t support it. The scenario with a percentage sign in front is not supported, but the scenario with a percentage sign on the right is supported. The results of explain analyze are different.
Why did it stop working after testing for so long? LIKE is quite common and should work.
Executing this on TiKV also requires a full table scan. This kind of query is quite suitable for pushing down to TiFlash.
Yes, I have also noticed this issue.
There are several modes, and mainstream databases should behave consistently. %target_value will not use the index, but target_value% can use the index.
 Actually, our development guidelines state that we should avoid using like ‘%target value’ as much as possible.
Actually, our development guidelines state that we should avoid using like ‘%target value’ as much as possible.
Avoided it in advance, haha. For this kind of fuzzy query, it seems that a search-oriented database product is still needed.
If it can be solved at the application layer, don’t bother the DBA.
Why wasn’t it pushed down?
Wasn’t this pushed down to TiKV for filtering?
After testing, we found that [the execution plan TableRangeScan is at the level of tens of thousands of rows], and the execution time of TiDB is indeed not significantly improved compared to native MySQL.
That’s for sure. With data at the level of tens of thousands of rows, TiDB probably only has one region, so the pushdown effect of multiple TiKV nodes in TiDB cannot be reflected. Adding the TiDB layer might even decrease efficiency…
If you have data at the level of hundreds of millions of rows and many TiKV nodes, you will see a significant improvement.
Does the “cop[tikv]” in the task field indicate that the index has been pushed down?