Catalyst is a series B Software-as-a-Service (SaaS) startup that provides a powerful customer success platform to help companies achieve success with their customers. With Catalyst, companies can centralize their customer data, get a clear picture of their customer health, and scale experiences that drive retention and growth.
Data workload characteristics
Catalyst is a platform dealing with a large amount of data. It consolidates data from a wide range of sources including Salesforce, Mixpanel, and PostgreSQL, and puts it into the Catalyst ecosystem for processing, analytics, and actionable insights.
Catalyst works with three major types of data: transactional objects, read-only objects, and time-series objects.
- Transactional objects mainly include internally created notes and tasks and externally collected data objects from Salesforce, Zendesk, and others.
- Read-only objects mainly refer to ticket objects collected from platforms including Jira and Zendesk.
- Time-series objects are among Catalyst’s most important and tricky data types. When the Catalyst team was looking for a new database, one of their main requirements was whether it could handle these kinds of objects.
Previous data architecture and its bottlenecks
It took a while for Catalyst to find the best database and data architecture.
In the beginning, Catalyst used PostgreSQL to handle all the data it collected externally. However, as its business grew and the data sources expanded quickly, PostgreSQL wasn’t able to keep up with its needs. Catalyst initially tried to remedy this by storing the data as JSON documents, but query performance was heavily impacted.
Then, the team turned to pre-caching. They adopted Elasticsearch to store the results in order to respond to customers’ queries more quickly. However, because Elasticsearch doesn’t support SQL-style JOINs, Catalyst had to precompute literally everything before storing it in Elasticsearch. Due to the increased amount of data being stored, costs skyrocketed.
Time to re-architect and introduce new stacks
To address their existing issues and scale for future growth, the Catalyst team decided to redesign their entire data processing and storage system. That’s when they found TiDB.
Catalyst’s new architecture has five data layers: data ingest, data lake, Spark layer, data serving, and web application. Raw data enters through the ingest layer and continues into the data lake. The Spark layer combines objects, performs pre-computations, and enriches the data to make sure it all makes sense. The data serving layer stores preprocessed data for customer queries, as such, it is the most important layer because it directly impacts end user experience. It is also where Catalyst needed a new data stack and where TiDB eventually won its place. The layers below the data serving layer do not have to be in real time. However, at the data serving layer, Catalyst requires sub-second latency so customers can quickly get their results.

Requirements for the new stack
In order to serve its ever-growing number of customers, Catalyst urgently needed a database that can:
Withstand hybrid transactional and analytical workloads. Catalyst has to deal with transactional and read-only objects, and time-series data. They need a solution, either a single database or a database combination, that can handle both transactional and analytical workloads.
Respond at speed. The new database solution must be more agile than Catalyst’s previous solution—especially in query speed and user interface performance. It must respond to queries in subseconds and has low update latency.
Handle complicated and highly customized data. Catalyst’s customers can customize many settings including queries, data transformations, and relationships, both inside the Catalyst platform and on data source platforms such as Salesforce and Zendesk. The combination of custom objects integrated with many custom fields can be quite complicated. The new solution has to be able to handle such situations.
Be highly available. Catalyst needs to be very responsive to their customers. Keeping their system up is Catalyst’s top priority. In some cases when Catalyst was down, they got hit up by customers within tens of seconds. Therefore, the new database solution must be highly available to help Catalyst survive possible disasters.
Be horizontally scalable. Scalability is another must-have. Catalyst deals with a huge volume of data, and the volume will keep expanding. The database solution must easily scale to an enormous size.
Be strongly consistent. Data consistency is another requirement. But given that it is extremely hard to keep strong consistency throughout the entire system due to so much data processing going up the flow, Catalyst accepts eventual consistency.
TiDB stands out during performance testing
Catalyst was careful with their choices of a new database; they investigated TiDB along with two other options: Aurora coupled with AWS Timestream, and YugaByte coupled with AWS Timestream. These options are combinations of an Online Transactional Processing (OLTP) database and a time-series database.
Testing and prototyping three candidates
Catalyst tested the three candidates by running large real-world datasets from their internal Salesforce and Jira instances. Under this heavy load, they simultaneously and continuously ran a subset of queries. The query response speed was among the most important evaluation criteria.
TiDB outperforms the other candidates
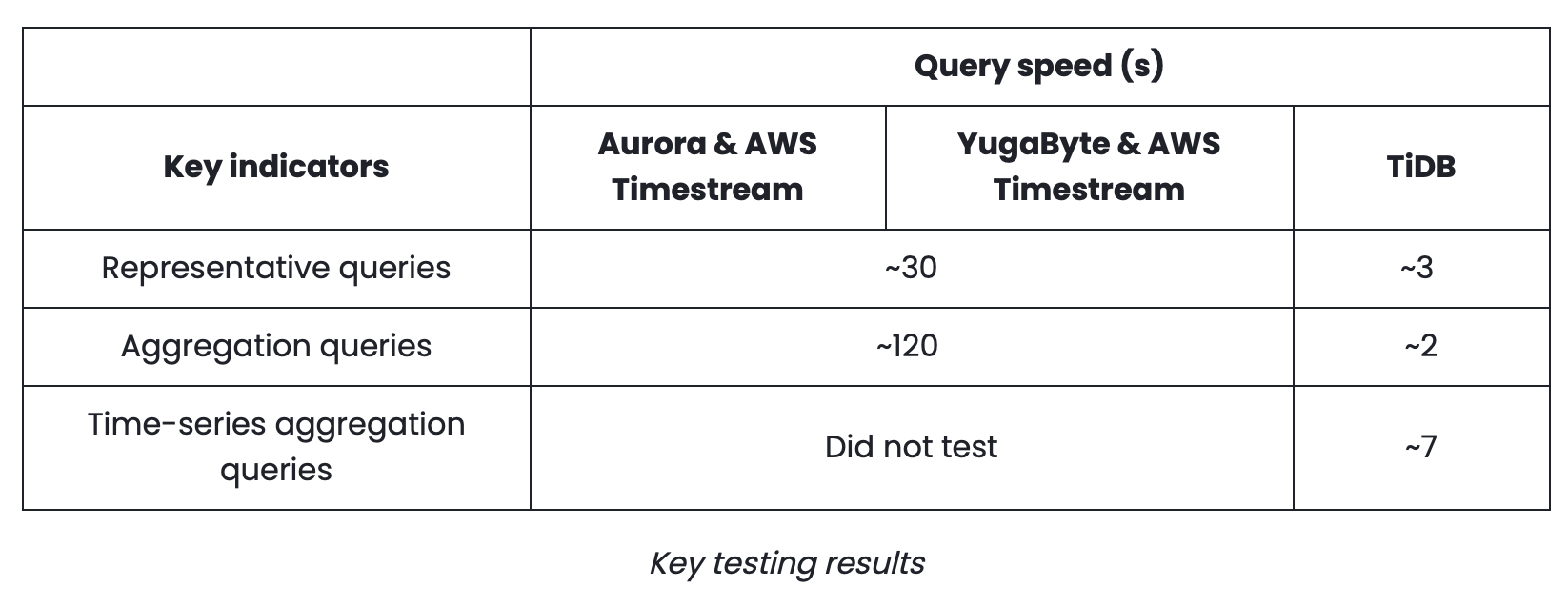
TiDB responded to both representative and aggregation queries in seconds—much faster than the other options. In regards to time-series aggregation queries, TiDB was also agile enough to return results in about 7 seconds. The following table summarizes some key testing results.
The types of queries were:
- Representative queries: the queries that customers were most interested in.
- Aggregation queries: primarily computations based on complicated JOINs.
- Time-series aggregation queries: Catalyst did not test the time series aggregation queries on Aurora and Yugabyte solutions because of limited time and because TiDB’s performance was impressive enough for them.
Why did Catalyst choose TiDB?
Outstanding query response time
Depending on the type of query, TiDB’s response time was 10 to 60 times faster than its competitors. This is the most important reason Catalyst chose TiDB.
Perfect support for online DDL
TiDB supports online data definition language (DDL) operations and performs them fast without impacting the online business. TiDB offers worry-free schema changes and allows Catalyst to add or drop indexes much faster, especially for large tables. This is particularly useful when they encounter slow queries and need to quickly add an index to improve performance. With online schema change, Catalyst doesn’t have to block online business or reserve a long maintenance window.
A single database with hybrid capabilities
TiDB is a Hybrid Transactional and Analytical Processing (HTAP) database. Of the three options Catalyst evaluated, TiDB is the only one that can handle both the object data and time series data in a single tech stack. Not only is this highly efficient, but it also saves Catalyst a lot of time, effort, and money.
Horizontal scalability
TiDB is also highly scalable horizontally. This perfectly meets Catalyst’s business need to respond to expanding data volume. TiDB also separates its computing and storage resources, which allows Catalyst to scale out the two resources separately. This also helps them control their costs.
Fast and automatic failover
TiDB uses the Raft consensus algorithm to ensure that data is highly available and safely replicated throughout storage in Raft Groups. TiKV is TiDB’s storage server, and data is redundantly copied between TiKV nodes and placed in different availability zones to protect against machine or data center failure. This ensures Catalyst’s system uptime. In addition, TiDB offers a choice of multiple disaster recovery solutions, each of which applies to different scenarios with flexible costs.
TiDB offers full managed services
Catalyst has a small DevOps team, so they prefer a fully-managed database solution to relieve the burden on the team and control the costs. TiDB Cloud, the fully-managed service of TiDB, meets this need.
Cloud agnostic
For flexibility, Catalyst straddles two clouds: some workloads run on the Google Cloud Platforms (GCP) and some run on Amazon Web Services (AWS). Therefore, they need a cloud-agnostic database solution that supports both platforms. TiDB Cloud is exactly such a solution.
Summary
Catalyst previously used PostgreSQL to handle their customer data. But soon their system hit an upper limit. They redesigned their data architecture and urgently needed a new database to serve data to their customers.
By adopting TiDB, Catalyst is able to provide better customer experience with faster query responses, a more resilient system, amplified data storage, processing, and analytical capabilities. Catalyst also reduced their overall storage, operation, and maintenance costs.
Catalyst previously used PostgreSQL to handle their customer data. But soon their system hit an upper limit. They redesigned their data architecture and urgently needed a new database to serve data to their customers.
By adopting TiDB, Catalyst is able to provide better customer experience with faster query responses, a more resilient system, amplified data storage, processing, and analytical capabilities. Catalyst also reduced their overall storage, operation, and maintenance costs.
This customer story is created based on a talk given by Andy Trimble at the Virtual HTAP Summit 2022.
![]() Ready to supercharge your data integration with TiDB? Join our Discord community now!
Ready to supercharge your data integration with TiDB? Join our Discord community now! ![]() Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!
Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!