Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: CDC创建成功,但是TSO 没变化不同步
Source version 4.0.2 TiDB, CDC. Target version 5.0.0 TiDB.
The task was created successfully, but the specified TSO has not changed.
Creating CDC:
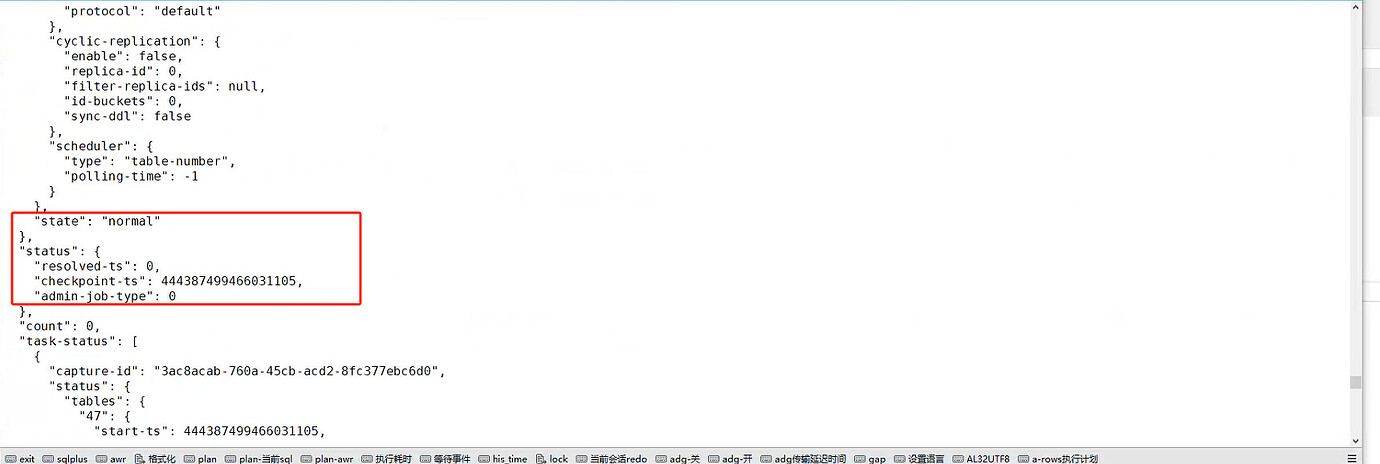
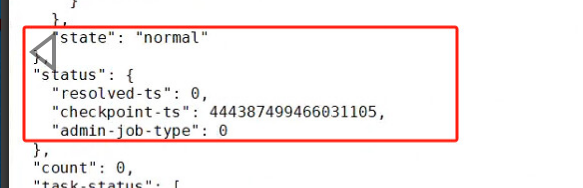
Querying the task:
This job shows that the task is in progress. However, the TSO has not changed at all.
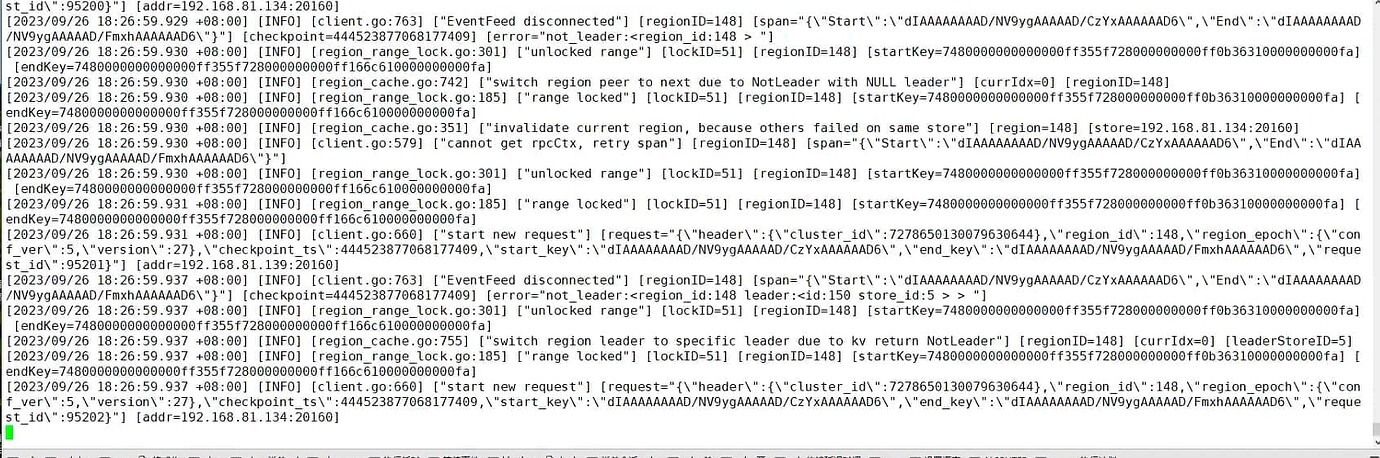
CDC log:
How long is your GC time set?
May I ask how many tables are there in the database you need to synchronize?
The source end is set to 720h.
I restored from a BR backup of the source end. It’s a test environment, so there was almost no data during this period. There are 10 tables. No filtering was done. Synchronized all of them.
No changes for 2 minutes.
Is there any data change upstream? Try stopping the CDC task and creating a new one.
Already removed and rebuilt once. Still the same issue. The logs keep indicating:
[2023/09/26 18:39:32.840 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=33.277955ms]
[2023/09/26 19:00:02.437 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=40.100595ms]
[2023/09/26 19:00:06.577 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=152.972321ms]
[2023/09/26 19:00:06.587 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=84.737071ms]
[2023/09/26 19:00:06.866 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=266.915521ms]
[2023/09/26 19:00:06.872 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=205.5529ms]
[2023/09/26 19:00:06.872 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=65.919414ms]
[2023/09/26 19:00:06.872 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=52.121604ms]
[2023/09/26 19:00:07.073 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=98.202912ms]
[2023/09/26 19:00:07.330 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=308.268864ms]
[2023/09/26 19:00:07.331 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=205.100336ms]
[2023/09/26 19:00:07.331 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=39.295962ms]
[2023/09/26 19:00:07.331 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=64.511015ms]
[2023/09/26 19:00:07.331 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=185.150581ms]
[2023/09/26 19:24:42.064 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=41.583631ms]
Is anyone there??? Please help take a look~~~ Bump this up, I’m bumping~ I’m bumping~~ I’m bumping bump bump.
A KV IP with 134 refused the connection, check the status of this KV.
That was the initial error. I found that the virtual machine kept prompting OOM and killing processes. So I increased the memory for all three KV instances and restarted them. The connection refused error is gone now.
Run cdc cli changefeed list --pd=ip:6379 to check if the task status is normal. If it is normal, just wait.
Normally, this is version 4.0.2. So it only outputs an ID value without a status prompt. You can only use this: tiup cdc:v4.0.2 cli changefeed query -s --pd=http://192.168.81.132:2379 --changefeed-id=e1b66543-4d9d-41c2-85b0-fb4d83fe42f4
The result shows normal, but the resolved-ts value sent to the target end is always 0.
CDC only became a formal feature starting from version 4.0.6. The previous versions were all trial versions. It is recommended to upgrade the TiDB version.
Upgraded from version 4.0.2 to 4.0.9. Synchronized automatically.
Try upgrading the version.
Found the issue, it’s related to the parameter --sort-engine=“unified”. Versions below 4.0.9 cannot use the unified parameter; it defaults to memory, and unified must be specified manually. The backend logs report an unrecognized unified parameter.
It’s better to use a newer version; the old versions indeed have many issues.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.