Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: cdc报ErrRegionsNotCoverSpan错误下游写入异常
Version: v5.2.3 arm
Issue:
At around 14:00, CDC encountered an exception. Upon inspection, downstream writes were found to be 0, and the cdc cli reported the following error:
"code": "CDC:ErrRegionsNotCoverSpan",
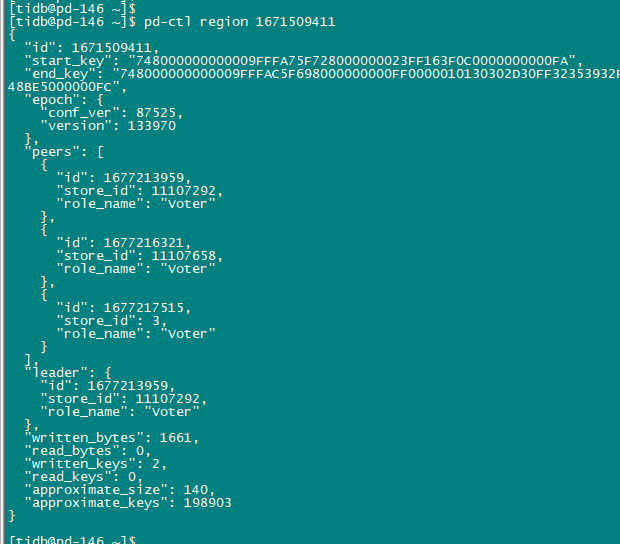
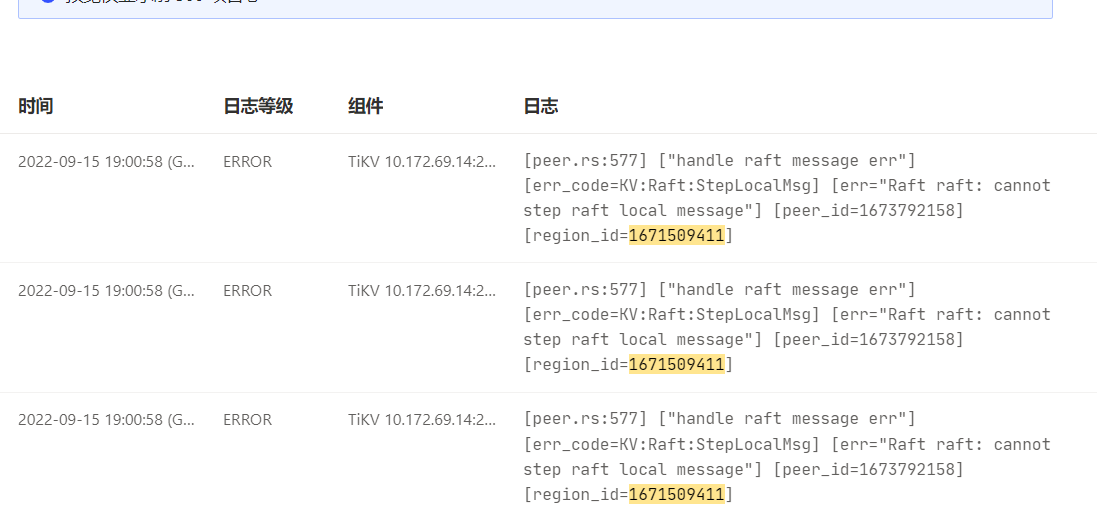
"message": "[CDC:ErrReachMaxTry]reach maximum try: 100: [CDC:ErrRegionsNotCoverSpan]regions not completely left cover span, span [748000000000009fffa15f72800000001affb9c99b0000000000fa, 748000000000009fffa15f730000000000fa) regions: [id:1671509411 start_key:\"t\\200\\000\\000\\000\\000\\000\\237\\377\\241_r\\200\\000\\000\\000\\032\\377\\273\\013\\307\\000\\000\\000\\000\\000\\372\" end_key:\"t\\200\\000\\000\\000\\000\\000\\237\\377\\254_i\\200\\000\\000\\000\\000\\377\\000\\000\\001\\00100-0\\3772592\\377003\\377391_8\\3771_\\377010806\\3770\\3775681895\\377\\37725_81140\\377\\3770000032\\377_\\377010810\\37747\\377472_\\000\\377\\000\\000\\000\\373\\003\\200\\000\\000\\377\\000\\0014\\213\\345\\000\\000\\000\\374\" region_epoch:\u003cconf_ver:80829 version:132267 \u003e peers:\u003cid:1675591530 store_id:11107291 \u003e peers:\u003cid:1675593220 store_id:56722 \u003e peers:\u003cid:1675595947 store_id:11107657 \u003e ]"
Based on the error message, I found the following known issue: ScanRegions total retry time is too short · Issue #5230 · pingcap/tiflow (github.com). This issue might not be fixed in version 5.2, so I restarted the CDC, and it returned to normal. After a while, it resumed writing data downstream. Around 18:00, I checked again and found that downstream writes were intermittent. After two more restarts, it returned to normal, but after a while, it became abnormal again.
After the last two CDC restarts, checking the changefeed status still showed the same error.
After waiting for CDC to start writing data downstream, checking the CDC status still showed the above error. It seems that the downstream write issue is not related to this error.
146 node logs
cdc.log.tar.gz (13.3 MB) cdc-2022-09-23T20-28-40.335.log.gz (18.3 MB)
151 node logs
cdc-2022-09-23T13-36-18.561.log.gz (17.1 MB) cdc-2022-09-23T17-52-35.450.log.gz (19.2 MB)
152 node logs
cdc-2022-09-23T17-32-17.523.log.gz (16.9 MB)