Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 集群admin show ddl异常
[TiDB Usage Environment] Test
[TiDB Version] 4.0.8
[Reproduction Path] Operations performed that led to the issue
Initially, when executing admin show ddl jobs and insert, the cluster prompted:
Error 1105: tikv aborts txn: Txn(Mvcc(DefaultNotFound { key: [109, 68, 66, 58, 50, 57, 50, 52, 51, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247, 0, 0, 0, 0, 0, 0, 0, 104, 84, 97, 98, 108, 101, 58, 50, 57, 255, 50, 54, 56, 0, 0, 0, 0, 0, 250]
Also, executing create/drop directly hangs and cannot proceed. Restarting tidb-server or adding new nodes fails to start, with the startup prompt:

After performing mvcc online repair on the cluster and repairing up to 3 TIKV nodes, executing admin commands prompts:
![]()
The current tidb-server prompts:

Writing to the table prompts that the database does not exist, and only select/update/delete can be performed, but not insert.
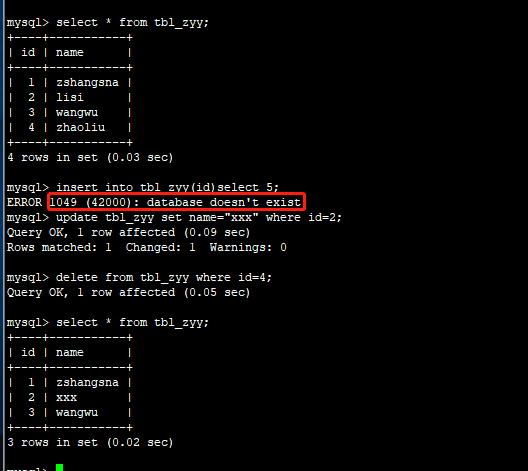
The current tidb-server log that has not been restarted:
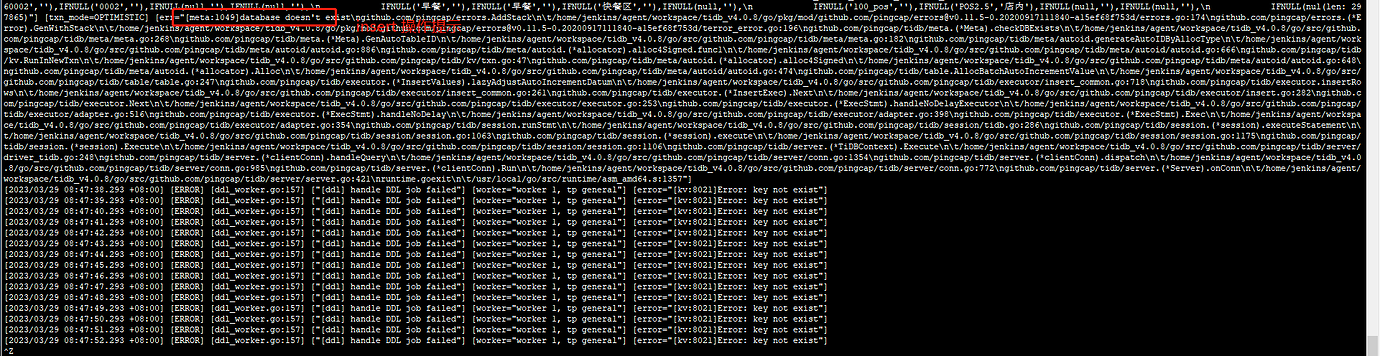
[Encountered Issues: Symptoms and Impact]
1. Restarted tikv
2. MVCC online repair
3. Scaling tidb-server
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
