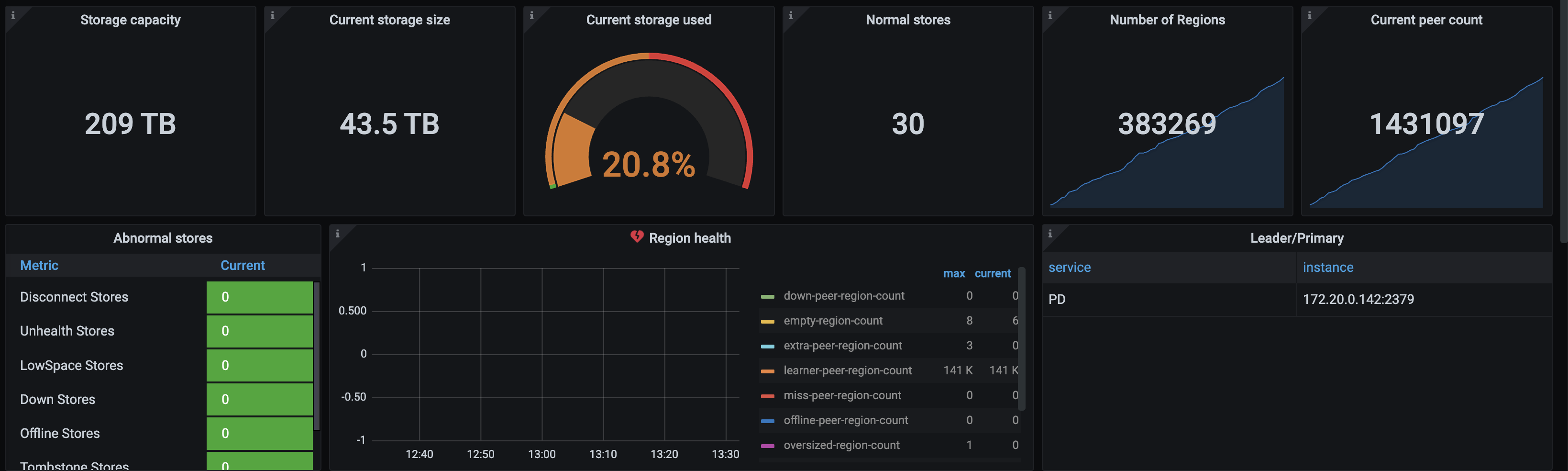
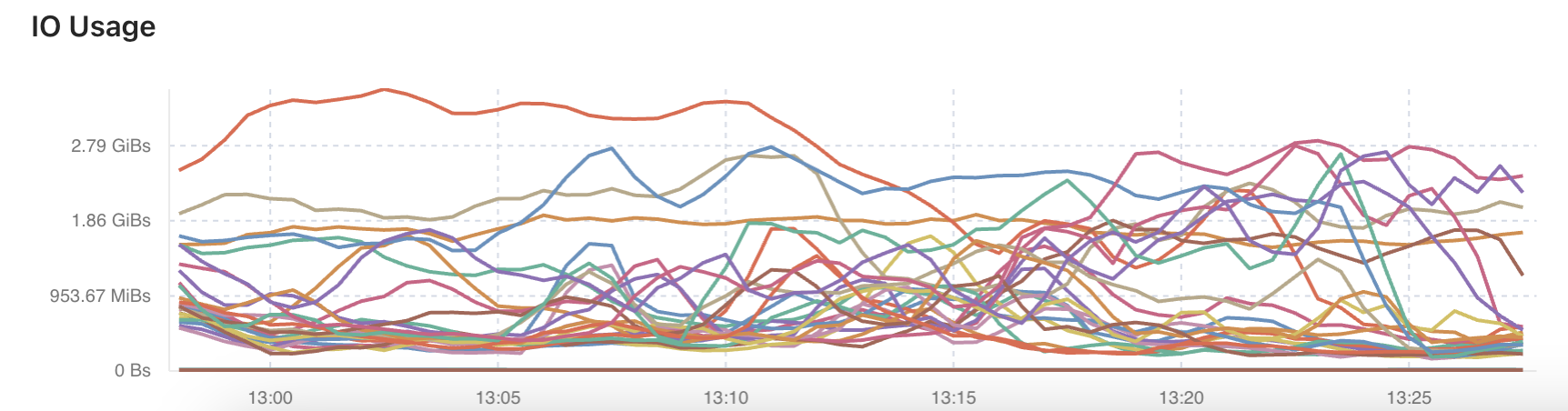
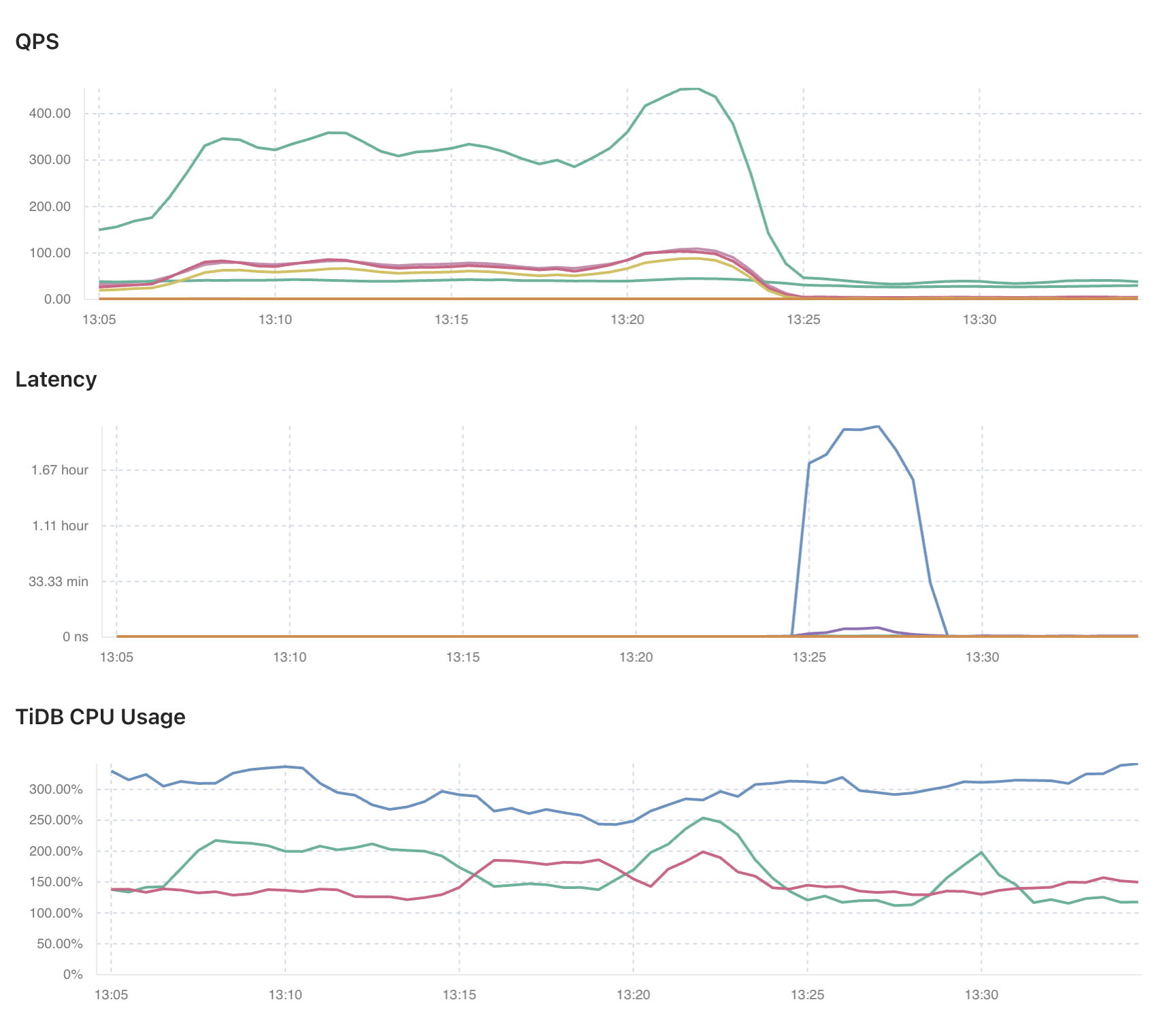
Hi, the learner-peer-region-count is about 141K. is it ok?
I also have another question. according to the data, storage size and the regions size, how many nodes should I have for each component?
can I scale-in tikv nodes to have and merge cpu cores and memory (32 core, 64g memory) so I would have more performant nodes?
how many tidb nodes should I have?
pd ctl config
also here is my config of pd
{
"replication": {
"enable-placement-rules": "true",
"enable-placement-rules-cache": "false",
"isolation-level": "",
"location-labels": "",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "true",
"enable-diagnostic": "true",
"enable-heartbeat-breakdown-metrics": "true",
"enable-joint-consensus": "true",
"enable-tikv-split-region": "true",
"enable-witness": "false",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"hot-regions-reserved-days": 7,
"hot-regions-write-interval": "10m0s",
"leader-schedule-limit": 8,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-movable-hot-peer-size": 512,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"max-store-preparing-time": "48h0m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "10ms",
"region-schedule-limit": 2048,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"slow-store-evicting-affected-store-ratio-threshold": 0.3,
"split-merge-interval": "1h0m0s",
"store-limit-version": "v1",
"switch-witness-interval": "1h0m0s",
"tolerant-size-ratio": 0,
"witness-schedule-limit": 4
}
}
Application environment:
on virtual machines. described below in resource section.
region size: about 400,000
storage size: 45TB
TiDB version:
8.1.0
Problem:
in monito
Resource allocation:
27 tikv nodes (16core, 32g memory)
3 tiflash nodes (32core, 100g memory)
3 tidb nodes (16core, 32g memory)
3 pd nodes (8 core, 16g memory)
1 tiproxy
all disks are ssd enterprise