Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 集群升级cdc中断15分钟
[TiDB Usage Environment] Production Environment
[TiDB Version]
v5.4.3 → v7.1.5
[Reproduction Path] What operations were performed when the issue occurred
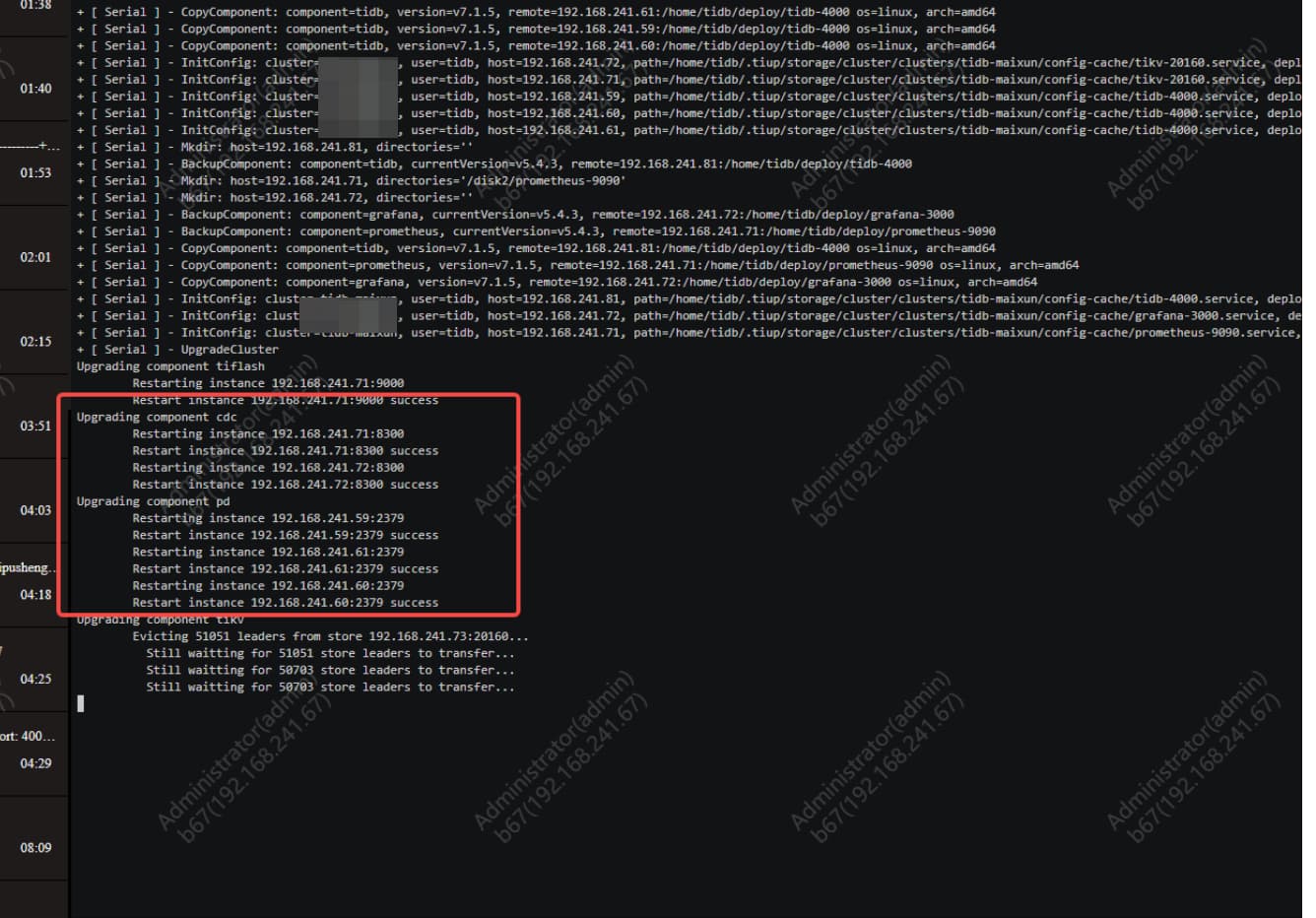
Upgraded cluster version from v5.4.3 to v7.1.5, during the upgrade process, CDC data was interrupted for 15 minutes.
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
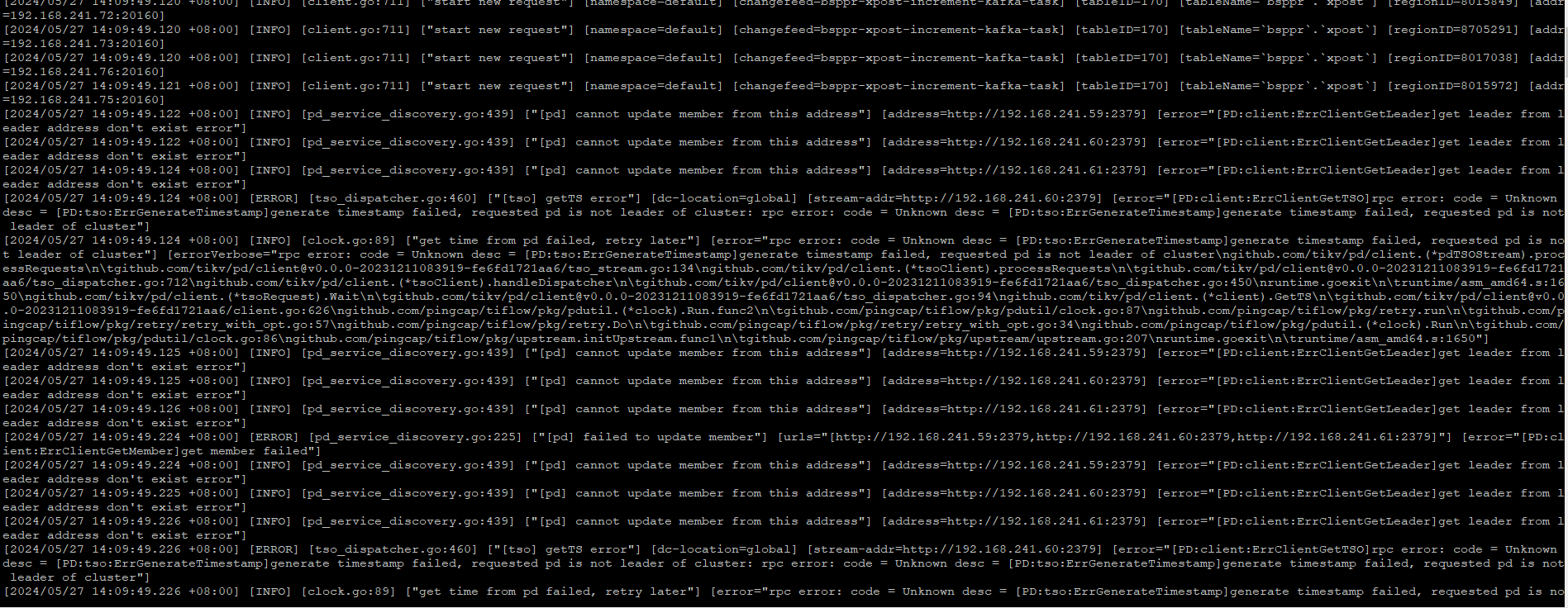
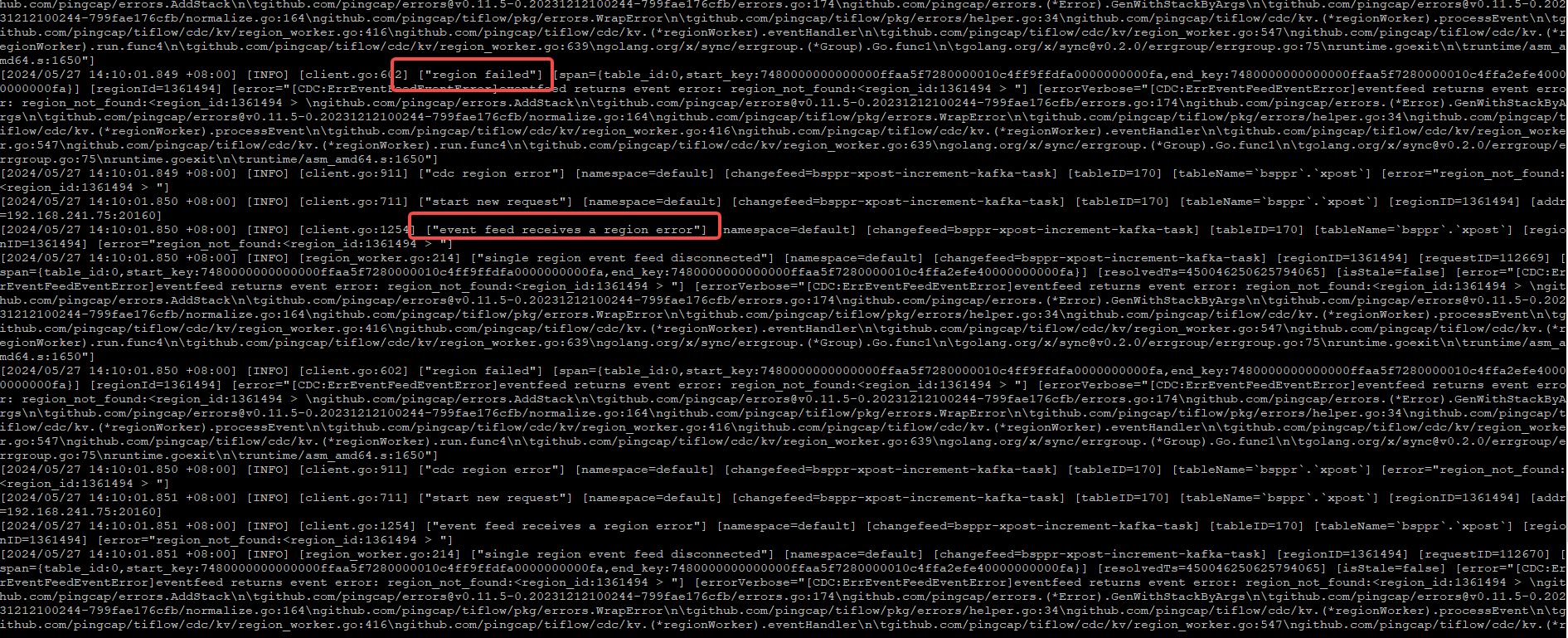
CDC logs started reporting errors
The affected time range seems to be all these kinds of logs, too large to upload
The first log should be the PD leader switch, and the subsequent info might be related to the rolling leader switch of TiKV.
CDC needs to scan the TiKV raft logs, so it’s understandable that region leader switches and TiKV restarts could affect CDC tasks.
Isn’t the leader supposed to switch proactively when it goes offline normally? As I understand it, shouldn’t PD know the current leader information? Why does it keep reporting the following errors? Even if the leader can’t be found, there should always be one found, right? The issue is that the CDC data is directly zero, which isn’t normal, right?
The proactive switching of the TiKV leader does not necessarily mean that the PD information is up-to-date. By default, TiKV should report leader information once every minute. If an error occurs, let TiKV report it proactively.
How should we understand the CDC data being directly 0? Could it be that the CDC CLI was not updated at that time, leading to issues with the query results… and it might actually be running?
The actual data is 0. The logic is: ticdc writes data to the downstream Kafka, and through the monitoring of the Kafka topic, it is observed that the data producer for this topic is 0.
Grafana → CDC’s dashboard → TiKV’s Row → Three Initial scan panels
If it’s a scan, then these three panels will respond at 14:35.
If a scan occurs, it’s expected to be stuck.
The image is not visible. Please provide the text you need translated.
Does it match the peak time?
The online upgrade appears to be as expected from the monitoring.
- Upgrading from 5.4.3 to 7.1.5, CDC does not support rolling upgrades. Synchronization will stop until all CDCs are upgraded, then it will resume.
- After the upgrade is completed, CDC needs time to perform incremental scans and catch up with the previously missed data. Therefore, there is a short period of increased data writes after 14:30.
Learning from the expert~!