Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tikv存储的数据db文件实例问题请教
To improve efficiency, please provide the following information. Clear problem descriptions can be resolved faster:
【TiDB Usage Environment】
【Overview】 I would like to ask about the differences between using TiKV and standalone RocksDB data files.
【Application Framework and Business Logic Adaptation】
【Background】 What operations have been performed
【Phenomenon】 Business and database phenomena
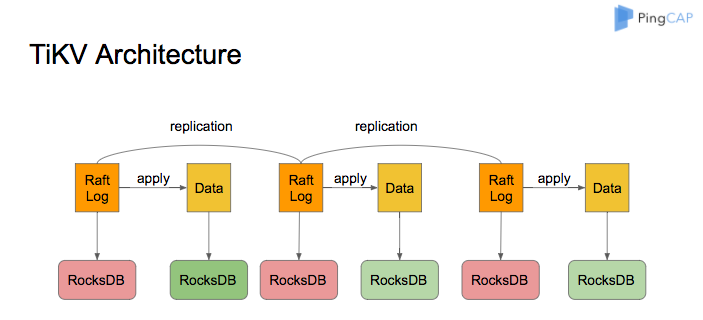
【Question】 We are currently using standalone RocksDB, where different data types instantiate multiple different DB files to operate on data, and there is a domain ID distinction. Different domain IDs generate different files like 100_accountdb.db to isolate data. In different domains, the same key might be operated on. However, if we switch to TiKV, does this concept no longer exist? For developers, there are no different DB file instances to operate on; it’s transparent, and you can only distinguish by different keys (e.g., prefixing with domain ID-key). All operation mechanisms are flattened, and you can’t isolate operations like with standalone RocksDB. Could someone familiar with TiKV’s underlying mechanisms please explain? Thank you.
【Business Impact】
【TiDB Version】
【Attachments】 Relevant logs and monitoring (https://metricstool.pingcap.com/)
For questions related to performance optimization or troubleshooting, please download the script and run it. Please select all and copy-paste the terminal output results for upload.