Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 课程笔记 TiDB 快速起步(中)
Course Link
Course Outline
-
History of Database, Big Data, and TiDB Development
-
01: History and Trends of Database and Big Data Development
-
02: Development of Distributed Relational Databases
-
03: Evolution of TiDB Products and Open Source Community
-
-
Overview of TiDB
-
04: What Kind of Database Do We Really Need
-
05: How to Build a Distributed Storage System
-
06: How to Build a Distributed SQL Engine
-
-
Selection of Next-Generation HTAP Database
-
07: HTAP Database Based on Distributed Architecture
-
08: Key Technological Innovations of TiDB
-
09: Typical Application Scenarios and User Cases of TiDB
-
-
First Experience with TiDB
- 10: First Experience with TiDB
Course Notes (in progress)
-
Storage Engine
-
Finer-grained Elastic Scaling
-
High Concurrent Read and Write
-
No Data Loss or Errors
-
Multi-replica Ensures Consistency and High Availability
-
Supports Distributed Transactions
-
-
Data Structure is the Core Fundamental Technology of Databases
-
BTree and LSM-tree
-
The LSM-tree structure essentially uses space to trade off write latency, replacing random writes with sequential writes.
-
TiKV single node uses the rocksdb engine based on LSM-tree
-
-
-
Data Replication
-
Consensus Algorithms: raft, paxos
-
Implementation of Scaling: Pre-sharding (static), Auto-sharding (dynamic)
-
Sharding Algorithms: hash, range, list
-
Range Sharding
-
More Efficient Data Scanning
-
Simple Implementation of Automatic Splitting and Merging
-
Elastic Priority, Shards Can Be Automatically Scheduled
-
May Encounter Hot Shard Issues
-
-
-
-
TiKV
-
A Multi-Raft System, Data is Split by Region (default 96M)
-
Each Region is a Key Range, from StartKey to EndKey, left-closed and right-open interval.
-
Data Storage/Access/Replication/Scheduling is done by region
-
Multi-version Control: TiKV’s MVCC is implemented by adding a version number to the Key
-
Coprocessor is the module in TiKV that reads data and performs calculations, each TiKV storage node has a coordinator calculator
-
-
Distributed Transaction Model
-
Decentralized Two-Phase Commit
-
Google Percolator Transaction Model
-
TiKV Supports Full Transaction KV API
-
Default Optimistic Transaction Model
-
Default Isolation Level: Snapshot Isolation
-
-
Implementing Logical Tables on KV, Secondary Index Based on KV
-
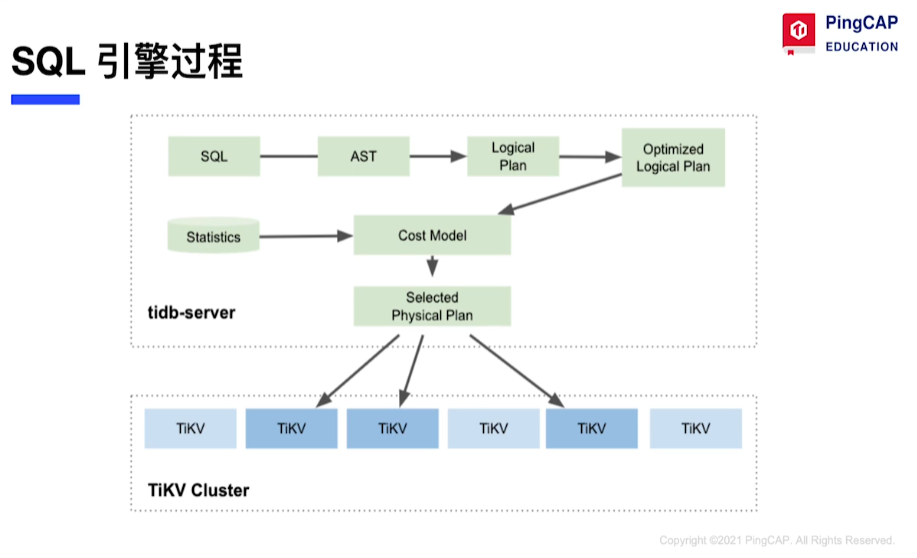
Cost-based Optimizer
-
Main Optimization Strategy of Distributed SQL Engine: Push Down
-
Key Operators Distributed
-
Online DDL Algorithm
-
No Sharding Concept in TiDB
-
The DDL process is divided into several states such as public, delete-only, write-only, etc., each state is synchronized and consistent across multiple nodes, eventually completing the full DDL
-
-
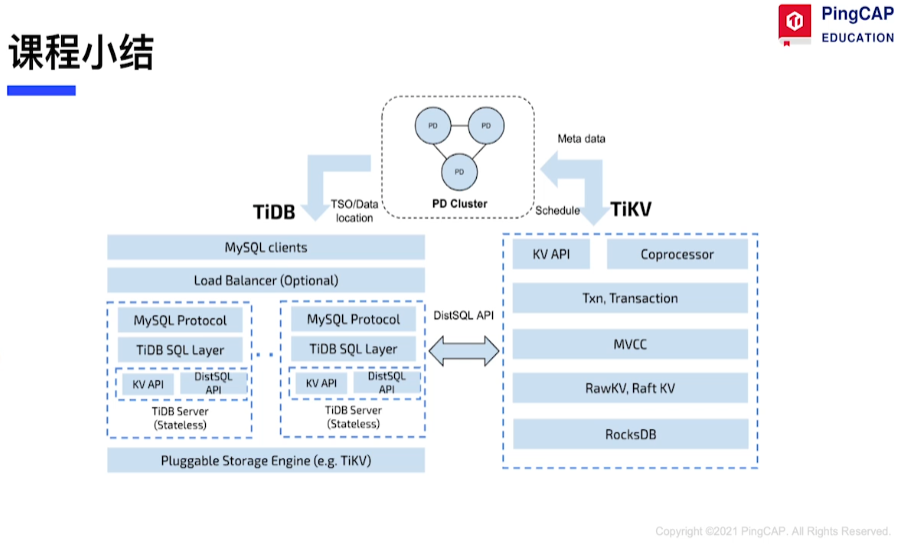
TiDB-server is a peer-to-peer, stateless, horizontally scalable, multi-point writable entry that directly handles user SQL
-
Other Functions of TiDB-server
-
Front-end Functions
-
Connection and Account Permission Management
-
MYSQL Protocol Encoding and Decoding
-
Independent SQL Execution
-
Database Table Metadata and System Variables
-
-
Back-end Functions
-
GC
-
Execute DDL
-
Statistics Management
-
SQL Optimizer and Executor
-
-
Reference Materials